按失真类型分类整理IQA数据集:TID2013
前面已经整理了TID2008,这次整理TID2013的工作相对较简单,只需要改代码的一部分就可以了,首先我大概介绍一些TID2013。
TID2013是TID2008的加强版,链接如下:http://www.ponomarenko.info/tid2013.htm。包括25幅参考图像,3000幅失真图像(25参考图像X24种失真×5失真水平)。失真类型有24种,增加了包括:改变色彩饱和度、多重高斯噪声、舒适噪声、有损压缩、彩色图像量化、色差以及稀疏采样。该数据库的DMOS值由971观察者给出524340个数据统计得到,MOS取值范围为[0,9]。所有图像都以Bitmap格式保存在数据库中,没有任何压缩。
文件名命名方式:参考图像号,失真类型,失真水平(“iXX_YY_Z.bmp”)。例如,名称为“i05_11_4.bmp”是指第5个参考图像,第11个类型的失真和与此失真相关的第4种水平。
分类整理过程跟之前的一样,先建立一个存放整体新数据的文件夹,比如disimage_fenkai,然后在该文件夹中建立24个存放每类失真图片和对应主观评分的文件夹,再在每个失真文件夹中建立文本文档存放主观评分(分割源mos_with_names.txt文本),最后根据文本中的数据将失真图片进行相应的分类。以下是详细过程代码:
1、新建disimage_fenkai,然后在该文件中建立24个用于存放每类失真的文件夹。
mkdir('./disimage_fenkai')
for i =1:24
mkdir('./disimage_fenkai/',['#',num2str(i)]);
end
% 文件路径中必须是斜杠不能是反斜杠
%.m文件的命名不能是mkdir,否则会报错
2、在每个对应的文件夹中新建文本文档用于存放每类失真图片的主观评分,然后将mos_with_names.txt文本中的文本按要求分割到每一个文本文档中,对应的代码如下:
%filename = '.\mos_with_names.txt';
%[vale,name] = textread(filename , '%f %s');
clc; clear file = '.\mos_with_names.txt';
fid = fopen(file,'r');
disp(['Reading file: ',file]);
linenumber = 0;
fid1=fopen('.\disimage_fenkai\#1\#1.txt','wt'); %必须要以wt的方式打开,不然不能换行
fid2=fopen('.\disimage_fenkai\#2\#2.txt','wt');fid3=fopen('.\disimage_fenkai\#3\#3.txt','wt');
fid4=fopen('.\disimage_fenkai\#4\#4.txt','wt');fid5=fopen('.\disimage_fenkai\#5\#5.txt','wt');
fid6=fopen('.\disimage_fenkai\#6\#6.txt','wt');fid7=fopen('.\disimage_fenkai\#7\#7.txt','wt');
fid8=fopen('.\disimage_fenkai\#8\#8.txt','wt');fid9=fopen('.\disimage_fenkai\#9\#9.txt','wt');
fid10=fopen('.\disimage_fenkai\#10\#10.txt','wt');fid11=fopen('.\disimage_fenkai\#11\#11.txt','wt');
fid12=fopen('.\disimage_fenkai\#12\#12.txt','wt');fid13=fopen('.\disimage_fenkai\#13\#13.txt','wt');
fid14=fopen('.\disimage_fenkai\#14\#14.txt','wt');fid15=fopen('.\disimage_fenkai\#15\#15.txt','wt');
fid16=fopen('.\disimage_fenkai\#16\#16.txt','wt');fid17=fopen('.\disimage_fenkai\#17\#17.txt','wt');
fid18=fopen('.\disimage_fenkai\#18\#18.txt','wt');fid19=fopen('.\disimage_fenkai\#19\#19.txt','wt');
fid20=fopen('.\disimage_fenkai\#20\#20.txt','wt');fid21=fopen('.\disimage_fenkai\#21\#21.txt','wt');
fid22=fopen('.\disimage_fenkai\#22\#22.txt','wt');fid23=fopen('.\disimage_fenkai\#23\#23.txt','wt');
fid24=fopen('.\disimage_fenkai\#24\#24.txt','wt'); while ~feof(fid)
linenumber = linenumber + 1;
line = fgetl(fid);
if(line(12:15) == '_01_') %跟之前的失真类型的位置不一样,因为TID2013的主观评分的精度要高一位。
%disp([num2str(linenumber),':',line]);
fprintf(fid1,[line,'\n']);
elseif(line(12:15) == '_02_')
fprintf(fid2,[line,'\n']);
elseif(line(12:15) == '_03_')
fprintf(fid3,[line,'\n']);
elseif(line(12:15) == '_04_')
fprintf(fid4,[line,'\n']);
elseif(line(12:15) == '_05_')
fprintf(fid5,[line,'\n']);
elseif(line(12:15) == '_06_')
fprintf(fid6,[line,'\n']);
elseif(line(12:15) == '_07_')
fprintf(fid7,[line,'\n']);
elseif(line(12:15) == '_08_')
fprintf(fid8,[line,'\n']);
elseif(line(12:15) == '_09_')
fprintf(fid9,[line,'\n']);
elseif(line(12:15) == '_10_')
fprintf(fid10,[line,'\n']);
elseif(line(12:15) == '_11_')
fprintf(fid11,[line,'\n']);
elseif(line(12:15) == '_12_')
fprintf(fid12,[line,'\n']);
elseif(line(12:15) == '_13_')
fprintf(fid13,[line,'\n']);
elseif(line(12:15) == '_14_')
fprintf(fid14,[line,'\n']);
elseif(line(12:15) == '_15_')
fprintf(fid15,[line,'\n']);
elseif(line(12:15) == '_16_')
fprintf(fid16,[line,'\n']);
elseif(line(12:15) == '_17_')
fprintf(fid17,[line,'\n']);
elseif(line(12:15) == '_18_')
fprintf(fid18,[line,'\n']);
elseif(line(12:15) == '_19_')
fprintf(fid19,[line,'\n']);
elseif(line(12:15) == '_20_')
fprintf(fid20,[line,'\n']);
elseif(line(12:15) == '_21_')
fprintf(fid21,[line,'\n']);
elseif(line(12:15) == '_22_')
fprintf(fid22,[line,'\n']);
elseif(line(12:15) == '_23_')
fprintf(fid23,[line,'\n']);
elseif(line(12:15) == '_24_')
fprintf(fid24,[line,'\n']); end
end fclose(fid1);fclose(fid2);fclose(fid3);fclose(fid4);
fclose(fid5);fclose(fid6);fclose(fid7);fclose(fid8);
fclose(fid9);fclose(fid10);fclose(fid11);fclose(fid12);
fclose(fid13);fclose(fid14);fclose(fid15);fclose(fid16);
fclose(fid17);fclose(fid18);fclose(fid19);fclose(fid20);
fclose(fid21);fclose(fid22);fclose(fid23);fclose(fid24);fclose(fid);
结果如下:
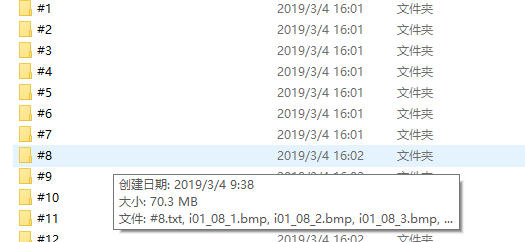
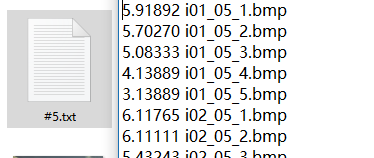
3、根据文本中的数据将文件distorted_images中的3000张失真图片进行相应的分类,将分类的图片存到对应的失真类型文件夹中,代码如下:
for i =1:24
file = ['.\disimage_fenkai\#',int2str(i),'\#',int2str(i),'.txt'];
fid = fopen(file,'r');
disp(['Reading file: ',file]);
while ~feof(fid) line = fgetl(fid);
filename = line(9:20); %取出图片名,注意现在的图片名要往后移动一位(跟TID2008相比),因为TID2013的主观评分精度高一位
A=imread(['.\distorted_images\',filename]); %按照图片名读取图片
%mkdir('.\disimage_fenkai\#1\');
imwrite(A,['.\disimage_fenkai\#',int2str(i),'\',filename]); %将图片按原名字存在#i中
end
fclose(fid); end
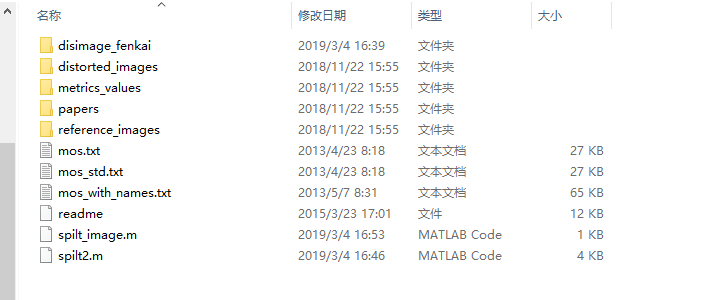
分割的最后结果显示如下:

所有代码的.m文件放到跟下载的失真数据集distorted_images文件夹同一路径下即可运行。如:
按失真类型分类整理IQA数据集:TID2013的更多相关文章
- 按失真类型分类整理TID2008
对于图像质量评价(IQA)数据库,TID2008算是不大不小的数据集了.TID2008是由乌克兰国家航空航天大学的N504信号接收.传输与处理系建立,包括25幅参考图像,1700幅失真图像.失真类型有 ...
- 做一个logitic分类之鸢尾花数据集的分类
做一个logitic分类之鸢尾花数据集的分类 Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例.数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都 ...
- (zhuan) 126 篇殿堂级深度学习论文分类整理 从入门到应用
126 篇殿堂级深度学习论文分类整理 从入门到应用 | 干货 雷锋网 作者: 三川 2017-03-02 18:40:00 查看源网址 阅读数:66 如果你有非常大的决心从事深度学习,又不想在这一行打 ...
- python基础——重访类型分类
python基础--重访类型分类 对象根据分类来共享操作:例如,字符串.列表和元组都共享诸如合并.长度和索引等序列操作. 只有可变对象(列表.字典和集合)可以原处修改:我们不能原处修改数字,字符串.元 ...
- Android Studio 分类整理 res/layout 中的布局文件
•准备工作 新建一个名为 TestLayouts 的项目: 进入 Project 模式: 来到 TestLayouts/app/src/main/res/layout 文件夹下: •分类整理 layo ...
- C++ //构造函数的分类及调用 //分类 // 按照参数分类 无参构造函数(默认构造) 有参构造函数 //按照类型分类 普通构造 拷贝构造
1 //构造函数的分类及调用 2 //分类 3 // 按照参数分类 无参构造函数(默认构造) 有参构造函数 4 //按照类型分类 普通构造 拷贝构造 5 6 #include <iostream ...
- DevOps开源工具的三种分类整理
原文地址:http://www.360doc.com/content/16/0322/07/31263000_544210096.shtml 随着开发运维一体化的DevOps运动在国内外蓬勃发展,De ...
- .NET系列文章——近一年文章分类整理,方便各位博友们查询学习
由于博主今后一段时间可能会很忙(准备出书:<.NET框架设计—模式.配置.工具>,外加换了新工作),所以博客会很少更新: 在最近一年左右时间里,博主各种.NET技术类型的文章都写过,根据博 ...
- 大量Python开源第三方库资源分类整理,含菜鸟教程章节级别链接
Python是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明.因其具有丰富和强大的库,它常被称为胶水语言,能够把用其它语言制作的各种模块(尤其是C/C ...
随机推荐
- 基于Python语言使用RabbitMQ消息队列(一)
介绍 RabbitMQ 是一个消息中间人(broker): 它接收并且发送消息. 你可以把它想象成一个邮局: 当你把想要寄出的信放到邮筒里时, 你可以确定邮递员会把信件送到收信人那里. 在这个比喻中, ...
- MongoTemplate聚合操作
Aggregation简单来说,就是提供数据统计.分析.分类的方法,这与mapreduce有异曲同工之处,只不过mongodb做了更多的封装与优化,让数据操作更加便捷和易用.Aggregation操作 ...
- 分布式代码管理github
Git是世界上最先进的分布式版本的控制系统,特点是:简单大气上档次. Linus在1991年创建了开源的Linux,从此,Linux系统不断发展,已经成为最大的服务器系统软件了.
- PostgreSQL 监控数据库活动
监控数据库活动 1. 标准Unix 工具 [root@mysqlhq ~]# ps auxww | grep ^postgrespostgres 12106 0.0 0.0 340060 15064 ...
- webbrowser和js交互小结
一.实现WebBrowser内部跳转,阻止默认打开IE 1.引用封装好的WebBrowserLinkSelf.dll实现 public partial class MainWindow : Windo ...
- 数据校验(3)--demo2---bai
input_user.jsp <%@ page language="java" import="java.util.*" pageEncoding=&qu ...
- 开发环境入门 linux基础 (部分)awk 赋值变量 if
awk 常用于处理格式非常明显的文件 awk -F: '{print $1}' /etc/passwd 含义:取冒号分隔符的第一段内容 $0 指取所有! NF 指有几段内容 $NF 取最后一段内容 ...
- java.lang.ClassCastException: org.apache.catalina.connector.RequestFacade cannot be cast to org.springframework.web.multipart.MultipartHttpServletRequest
转自:https://blog.csdn.net/iteye_17476/article/details/82651580 java.lang.ClassCastException: org.apac ...
- Android 音频播放分析笔记
AudioTrack是Android中比较偏底层的用来播放音频的接口,它主要被用来播放PCM音频数据,和MediaPlayer不同,它不涉及到文件解析和解码等复杂的流程,比较适合通过它来分析Andro ...
- CMake 使用方法 & CMakeList.txt<转>
CMake 使用方法 & CMakeList.txt cmake 简介 CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程).他能够输出各种各样的make ...