jemalloc和内存管里
netty的buffer引入了缓冲池。该缓冲池实现使用了jemalloc的思想。为了看懂这块代码学写了内容分配的知识。这里讲的内存分配是堆的内存分配,其他内容本文不会涉及。
内存分配是面向虚拟内存的而言的,以页为单位进行管理的,页的大小一般为4kb,当在堆里创建一个对象时(小于4kb),会分配一个页,当再次创建一个对象时会判断该页剩余大小是否够,够的话使用该页剩余的内存,减少系统调用。真实的内存分配算法比这个复杂了,效率不好的内存算法会导致出现很多内存碎片。
内存分配的核心思想概括起来有3条
1:首先讲内存区(memory pool)以最小单位(chunk)定义出来 ,然后区分对象大小分别管理内存,小内存定义不同的规格(bins),根据不同的bin分配固定大小的内存块,并用一个表
管理起来,大对象则以页为单位进行管理,配合小对象所在的页,降低碎片,设计一个好的存储方案(metadata)减少对内存的占用,同时优化内存信息的存储。以使对每个bin或大内存区域的访问性能最优且有上限。
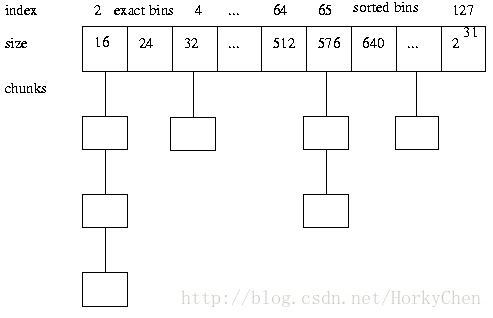
2:当释放内存时,要能够合并小内存为大内存,该保留的保留下次可快速响应,不该保留的释放给系统
3:多线程环境下,每个线程可以独立的占有一段内存区间(TLS),这样线程内操作可以不加锁
jemalloc是freebsd的内存分配算法,他的layout如下:
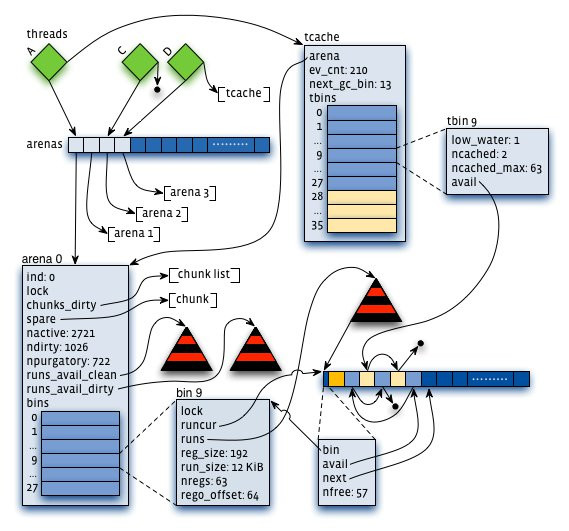
1:arena:把内存分成许多不同的小块来分而治之,该小块便是arena,让我们想象一下,给几个小朋友一张大图纸,让他们随意地画点。结果可想而知,他们肯定相互顾忌对方而不敢肆意地画(synchronization),从而影响画图效率。但是如果老师事先在大图纸上划分好每个人的区域,小朋友们就可以又快又准地在各自地领域上画图。这样的概念就是arena。它是jemalloc的核心分配管理区域,对于多核系统,会默认分配4*cores个arena 。线程采用轮询的方式来选择响应的arena进行内存分配。
2: chunk。具体进行内存分配的区域,默认大小是4M,chunk以page为单位进行管理,每个chunk的前6个page用于存储后面page的状态,比如是否分配或已经分配
3:bin:用来管理各个不同大小单元的分配,比如最小的Bin管理的是8字节的分配,每个Bin管理的大小都不一样,依次递增。
4:run:每个bin在实际上是通过对它对应的正在运行的Run进行操作来进行分配的,一个run实际上就是chunk里的一块区域,大小是page的整数倍,具体由实际的bin来决定,比如8字节的bin对应的run就只有1个page,可以从里面选取一个8字节的块进行分配。在run的最开头会存储着这个run的信息,比如还有多少个块可供分配。
5:tcache。线程对应的私有缓存空间,默认是使用的。因此在分配内存时首先从tcache中找,miss的情况下才会进入一般的分配流程。
arena和bin的关系:每个arena有个bin数组,每个bin管理不同大小的内存(run通过它的配置去获取相应大小的内存),每个tcahe有一个对应的arena,它本身也有一个bin数组(称为tbin),前面的部分与arena的bin数组是对应的,但它长度更大一些,因为它会缓存一些更大的块;而且它也没有对应的run的概念
chunk与run的关系:chunk默认是4M,而run是在chunk中进行实际分配的操作对象,每次有新的分配请求时一旦tcache无法满足要求,就要通过run进行操作,如果没有对应的run存在就要新建一个,哪怕只分配一个块,比如只申请一个8字节的块,也会生成一个大小为一个page(默认4K)的run;再申请一个16字节的块,又会生成一个大小为4096字节的run。run的具体大小由它对应的bin决定,但一定是page的整数倍。因此实际上每个chunk就被分成了一个个的run。
内存分配的,具体流程如下:
jemalloc和内存管里的更多相关文章
- 利用Jemalloc进行内存泄漏的调试
内存不符预期的不断上涨,可能的原因是内存泄漏,例如new出来的对象未进行delete就重新进行复制,使得之前分配的内存块被悬空,应用程序没办法访问到那部分内存,并且也没有办法释放:在C++中,STL容 ...
- tcmalloc jemalloc glibc内存分配管理模块性能测试对比
tcmalloc是谷歌提供的内存分配管理模块 jemalloc是FreeBSD提供的内存分配管理模块 glibc是Linux提供的内存分配管理模块 并发16个线程,分配压测3次,每次压15分钟,可以看 ...
- 基本数据类型的成员变量放在jvm的哪块内存区域里?
几个月前自己提问的一个问题没人回答,现在突然翻到,自己回答下: 问题: 比如class{private int i;}如上代码,之前一直以为基本数据类型都是放在虚拟机栈中的,最近看了<深入理解j ...
- 关于python内存管理里的引用计数算法和标记-清楚算法的讨论
先记录于此,后续有时间再深究吧: 1.https://www.zhihu.com/question/33529443 2.http://patshaughnessy.net/2013/10/30/ge ...
- ptmalloc,tcmalloc和jemalloc内存分配策略研究 ? I'm OWen..
转摘于http://www.360doc.com/content/13/0915/09/8363527_314549949.shtml 最近看了glibc的ptmaoolc,Goolge的tcmall ...
- jemalloc内存占用问题
最近,有部分越南的服务器内存不断上涨,怀疑是内存泄漏,因为框架提供的内存报告里,C内存和Lua占用内存都不大,和ps里看的差好多.总内存在12G左右,C和Lua的加起来约4G,两者相差了8G 经过一番 ...
- jemalloc内存分配器详解
前言 C 中动态内存分配malloc 函数的背后实现有诸派:dlmalloc 之于 bionic:ptmalloc 之于 glibc:allocation zones 之于 mac os x/ios: ...
- jemalloc总结
jemalloc支持SMP系统和并发多线程,多线程的支持是依赖于多个'arenas',并且一个线程第一次调用内存mallocer,与其相关联的是一个特殊的arena. 线程分配arena只有三种可能的 ...
- Redis的内存和实现机制
1. Reids内存的划分 数据 内存统计在used_memory中 进程本身运行需要内存 Redis主进程本身运行需要的内存占用,代码.常量池等 缓冲内存,客户端缓冲区.复制积压缓冲区.AOF缓冲区 ...
随机推荐
- Android Volley完全解析(二),使用Volley加载网络图片
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/17482165 在上一篇文章中,我们了解了Volley到底是什么,以及它的基本用法. ...
- STL的erase函数和lower_bound
前提摘要: [1]一般我们的区间是左闭右开,如下面例子2. [2]erase函数谨慎使用. [3]map也是有序保存的. [erase] 1,删除字符串的首字母: string s="ecu ...
- 51nod 1685 第K大区间2
定义一个长度为奇数的区间的值为其所包含的的元素的中位数.中位数_百度百科 现给出n个数,求将所有长度为奇数的区间的值排序后,第K大的值为多少. 样例解释: [l,r]表示区间的值[1]:3[2]:1[ ...
- npm install -d
nodejs Error: Cannot find module 'xxx'错误 解决方案: 确定package.json里有添加相应的依赖配置 使用npm install -d 可以自动配置pack ...
- Linux查看物理CPU个数、核数,逻辑CPU个数
学习swoole的时候,建议开启的worker进程数为cpu核数的1-4倍.于是就学习怎么查看CPU核数 # 查看物理CPU个数 cat /proc/cpuinfo| grep "physi ...
- mina在spring中的配置多个端口
本次练习中是监听2个端口 applicationContext-mina.xml: <?xml version="1.0" encoding="UTF-8" ...
- How far away ?(LCA)dfs和倍增模版
How far away ? Tarjan http://www.cnblogs.com/caiyishuai/p/8572859.html Time Limit: 2000/1000 MS (Jav ...
- PostgreSQL本地化
从管理员的角度描述可用的本地化特性.PostgreSQL支持两种本地化方法:利用操作系统的区域(locale)特性,提供对区域相关的排序顺序.数字格式. 翻译过的信息和其它方面.提供一些不同的字符集来 ...
- Oracle 静默安装的db_install.rsp 文件
Oracle 静默安装的db_install.rsp 文件,已修改好值 ################################################################ ...
- git学习4 常用命令
1:更新: 更新后,更新只在Workspace中,没有到暂存区.git status可以查看当前状态. git add <file> 可以放到待提交区. git checko ...