机器学习:集成学习(Ada Boosting 和 Gradient Boosting)
一、集成学习的思路
共 3 种思路:
- Bagging:独立的集成多个模型,每个模型有一定的差异,最终综合有差异的模型的结果,获得学习的最终的结果;
- Boosting(增强集成学习):集成多个模型,每个模型都在尝试增强(Boosting)整体的效果;
- Stacking(堆叠):集成 k 个模型,得到 k 个预测结果,将 k 个预测结果再传给一个新的算法,得到的结果为集成系统最终的预测结果;
二、增强集成学习(Boosting)
1)基础理解
- Boosting 类的集成学习,主要有:Ada Boosting 和 Gradient Boosting 两类;
- 由于每个子模型要使用全部的数据集进行训练,因此 Ada Boosting 算法中没有 oob 数据集,在使用 Ada Boosting 算法前,需要划分数据集:train_test_split;
- 每个 Ada Boosting 集成学习算法的模型只使用一个基本算法进行训练子模型;
- 相对于集成学习方法,决策树算法、SVM 算法、逻辑回归算法等,称为基本的学习方法;
2)Ada Boosting 集成学习算法
思想

- 假设是一个回归问题:图的最下层代表全部的训练数据集,深色的点为模型预测错误的点,定义为权重高样本,需要下一次生成的子模型时被重点对待;浅色的点为模型预测成功的点,定义为权重低样本;
- 图的中间层代表一种基本算法;
- 图的最上层代表算法根据拥有不同权重的样本的数据集,所训练出的模型;
- 箭头表示不同的子模型按一定规律生成;
- 解释上图过程(Ada Boosting 的思路):第一次进行学习得到第一个子模型,根据第一子模型的预测结果重新定义数据集——将预测错误的点(深色点)划分较高权重,将预测成功的点(浅色点)划分较低权重;第二次进行学习时,使用上一次学习后被重新定义的数据集进行训练,再根据模型的预测结果重新定义数据集——将预测错误的点(深色点)划分较高权重,将预测成功的点(浅色点)划分较低权重;以此类推,最终得到 n 个子模型;
- 特点:
- 每一次生成的子模型都在想办法弥补上一次生成的子模型没有成功预测到的样本点,或者说是弥补上一子模型所犯的错误;也可以说,每一个子模型都在想办法推动(Boosting)整个基础系统,使得整个集成系统准确率更高;
- 每一个子模型都是基于同一数据集的样本点,只是样本点的权重不同,也就是样本对于每一个子模型的重要程度不同,因此每份子模型也是有差异的;最终以所有子模型综合投票的结果作为 Ada Boosting 模型的最终学习结果;
- 怎么为样本赋权值,让下一子模型对不同权值的样本区别对待?
scikit-learn 中封装的 Ada Boosting 集成学习算法:
- AdaBoostClassifier():解决分类问题;
- AdaBoostRegressor():解决回归问题;
- 使用格式:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split X, y = datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=500)
ada_clf.fit(X_train, y_train)# 注:AdaBoostingClassifier() 的参数的使用可查文档;
3)Gradient Boosting 集成学习算法
思想
- 解释(一):
- 使用整体的数据集训练第一个子模型 m1,产生错误 e1(m1 模型预测错误的样本数据);
- 使用 e1 数据集训练第二个子模型 m2,产生错误 e2;
- 使用 e2 数据集训练第三个子模型 m3,产生错误 e3;
- 。。。
- 最终的预测结果是:m1 + m2 + m3 + 。。。(回归问题)
- 解释(二):

- 上图左侧绿色的线,子模型,从上到下: m1、m2、m3 模型;
- 上图右侧的红线,集成算法模型,随着子模型的增多,集成算法模型的整体变化情况,从上到下:m1、m1 + m2、m1 + m2 + m3
- 特点:
- 每一个模型都是对前一个模型所犯错误的补偿;
- Gradient Boosting 集成学习算法不能对基本算法进行选择,它的的基本算法就是决策树算法;
scikit-learn 中封装的 Gradient Boosting 集成学习:
- GradientBoostingClassifier():解决分类问题;
- GradientBoostingRegressor():解决回归问题;
- 使用格式:
from sklearn.ensemble import GradientBoostingClassifier gd_clf = GradientBoostingClassifier(max_depth=2, n_estimators=30)
gd_clf.fit(X_train, y_train)# 注:由于 Gradient Boosting 集成学习算法的基本算法只能用决策树算法,因此在设定参数时,不需要传入基本算法,而直接传决策树算法需要的参数;
三、Stacking(堆叠)
1)思想
对新样本的预测:
- 下图为堆叠集成算法的模型,新的样本讲过 3 种模型的预测,得到 3 个预测结果,再将 3 个预测结果作为输入传递该上层的一个模型得到一个预测值,则认为该预测值为最终的预测结果。
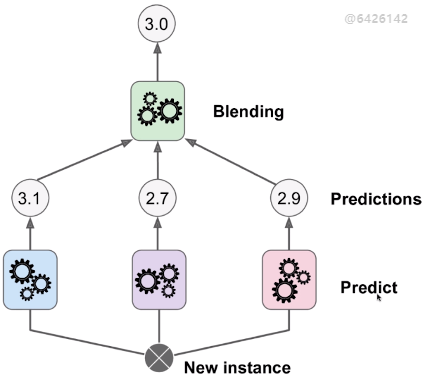
- 解决回归问题时,将 3 个预测值传给 最上层的一个模型,得到的值为最终的预测值;
- 解决分类问题时,3 个预测值为样本分类结果的最大概率值,传给最上层的一个模型,得到的最大的发生概率对应的类别为最终的预测类别;
- 逻辑回归中,可以直接求的回归问题的预测值,也可以直接将预测值转化为样本发生的概率,根据概率判定样本可能的类别;这种思路可以很好的使用一种算法可以解决两类问题:解决回归问题、分类问题;
2)训练 Stacking 的集成分类器
思路:如下图所示;
- 将训练数据集分割为 3 份(有几层就将 X_train 分成几份):X_train_1、X_train_2、X_train_3,使用 X_train_1 训练出 3 个模型(训练方式可以有多种);(得到第一层的 3 个模型)
- 将 X_train _2 数据集传入 3 个模型,得到 3 组预测结果,将 3 组预测结果与 X_train_2 数据集中的 y 值一起组合成一个新的数据集 X_train_new_1;(得到第一个新的数据集:X_train_new_1)
- 使用 X_train_new_1 数据集再训练出 3 个模型,为第二层的模型;(得到第二层的 3 个模型)
- 将 X_train _3 数据集传入第二层的 3 个模型,得到 3 组预测结果,再将 3 组预测结果与 X_train_3 数据集中的 y 值一起组合成一个新的数据集 X_train_new_2;(得到第二个新的数据集:X_train_new_2)
- 使用 X_train_new_2 训练出一个模型,作为最高层的模型;(得到第三层的 1 个模型)
- 系统超参数:层数、每层的模型个数;


3)其它
- 上图的逻辑思想类似神经网络,只不过对应神经网络来说,每一个神经元不是一个全新的算法,而只是计算一个函数的值;相应的,对应神经网络来说,如果层数增多的话就达到了深度学习的模型;
- 神经网络因其灵活度较高,容易出现过拟合;很多深度学习的话题,其本质就是在探讨,对于这样一个复杂的模型,如何解决其过拟合的问题;其中很多的方法也使用于 Stacking 集成学习算法;
- scikit-learn 中没有封装 Stacking 集成算法;
机器学习:集成学习(Ada Boosting 和 Gradient Boosting)的更多相关文章
- 【笔记】Ada Boosting和Gradient Boosting
Ada Boosting和Gradient Boosting Ada Boosting 除了先前的集成学习的思路以外,还有一种集成学习的思路boosting,这种思路,也是集成多个模型,但是和bagg ...
- 机器学习中的数学(3)-模型组合(Model Combining)之Boosting与Gradient Boosting
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 模型组合(Model Combining)之Boosting与Gradient Boosting
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 集成学习的不二法门bagging、boosting和三大法宝<结合策略>平均法,投票法和学习法(stacking)
单个学习器要么容易欠拟合要么容易过拟合,为了获得泛化性能优良的学习器,可以训练多个个体学习器,通过一定的结合策略,最终形成一个强学习器.这种集成多个个体学习器的方法称为集成学习(ensemble le ...
- 机器学习--集成学习(Ensemble Learning)
一.集成学习法 在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好) ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务.其工作流程为: 1)先产生一组“个体学习器”.在分类问题中,个体学习器也称为基类分类器 2)再使用某种策略将它们结合起来. 通常使用一种或者多种已有的 ...
随机推荐
- Ubuntu无法使用root用户登陆的解决办法
对于一个新安装的Ubuntu操作系统,经常会遇到无法使用root用户ssh连接操作系统,比如说root用户的密码被拒绝等原因. 面对这种问题,介绍一下Ubuntu无法使用root登陆解决 1. 修改 ...
- Linux查看文件编码格式及文件编码转换<转>
如果你需要在Linux 中操作windows下的文件 ,那么你可能会经常遇到文件 编码 转换的问题.Windows中默认的文件 格式是GBK(gb2312),而Linux 一般都是UTF-8.下面介绍 ...
- 出现GC overhead limit exceeded 的解决方案
当我在使用MyEclispe IDE创建Maven项目的时候出现 "An internal error occurred during: “Build Project”. GC overh ...
- eclipse修改端口启动多个tomcat
参考:https://blog.csdn.net/zl544434558/article/details/47857343 在一个eclipse启动多个tomcat,修改tomcat的端口是不可以的, ...
- ios 发布相关材料记录
1 app icon Spotlight iOS 5,6 base: 29pt, 需要 @1x, @2x, @3x,得出:29 x 29, 58 x 58, 87 x 87 iOS 7,8 base: ...
- 探究操作系统【TLCL】
ls – List directory contents file – Determine file type less – View file contents ls常用选项 ls -a 全部输出 ...
- js多个<ul>相应不同的点击事件
$('ul').on("click","li#left",function(){ currentProvince = $(this).text().replac ...
- 分布式技术 memcached
memcached 是一个高性能的分布式内存对象缓存系统,用于动态web应用,以减轻数据库负载,它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度.memcache ...
- MVC 嵌套页面Html.Partial
return View()相关简介 在asp.net mvc中返回View时使用的是ViewResult,它继承自ViewResultBase 同时它还有个兄弟PartialViewResult.一个 ...
- 关于es集群转换为单点后,主分片丢失的问题(健康检测状态为red)
正在找解决方案 前后情况是, 之前是es双节点,之后更改为单节点,data中的数据都是双节点的,也许导致了单节点的状态不正常,删除了data目录下内容后,重启es,好了,这是测试环境,所以这么干的