SQL SERVER大话存储结构(3)_数据行的行结构

1 引入
SELECT
表名 = CASE WHEN A.COLORDER=1 THEN D.NAME ELSE '' END,
表说明 = CASE WHEN A.COLORDER=1 THEN ISNULL(F.VALUE,'') ELSE '' END,
列序列号 = A.COLORDER,
列名 = A.NAME,
标识 = CASE WHEN COLUMNPROPERTY( A.ID,A.NAME,'ISIDENTITY')=1 THEN '√'ELSE '' END,
约束 = CASE WHEN EXISTS(
SELECT 1
FROM SYSOBJECTS
WHERE XTYPE='PK' AND PARENT_OBJ=A.ID AND NAME IN (
SELECT
NAME
FROM SYSINDEXES
WHERE INDID IN( SELECT INDID FROM SYSINDEXKEYS WHERE ID = A.ID AND COLID=A.COLID )
)
) THEN 'PK'
WHEN EXISTS (
SELECT 1 FROM sys.foreign_key_columns
WHERE parent_object_id=A.ID AND parent_column_id=A.COLID
) THEN 'FK'+'('+(SELECT OBJECT_NAME(referenced_object_id)+'.'+COL_NAME(referenced_object_id,referenced_column_id)+')' FROM sys.foreign_key_columns WHERE parent_object_id=A.ID AND parent_column_id=A.COLID)
ELSE '' END,
数据类型 = CASE WHEN B.NAME IN ('CHAR','NCHAR','VARCHAR','NVARCHAR') THEN B.NAME+'('+ISNULL(CAST(case when COLUMNPROPERTY(A.ID,A.NAME,'PRECISION')=-1 then null else COLUMNPROPERTY(A.ID,A.NAME,'PRECISION') end AS VARCHAR(10)),'MAX')+')'
WHEN B.NAME ='DECIMAL' THEN B.NAME+'('+CAST(COLUMNPROPERTY(A.ID,A.NAME,'PRECISION') AS VARCHAR(10))+','+CAST(ISNULL(COLUMNPROPERTY(A.ID,A.NAME,'SCALE'),0) AS VARCHAR(10))+')'
ELSE B.NAME END,
占用字节长度 = A.LENGTH,
--长度 = COLUMNPROPERTY(A.ID,A.NAME,'PRECISION'),
--小数位数 = ISNULL(COLUMNPROPERTY(A.ID,A.NAME,'SCALE'),0),
允许空 = CASE WHEN A.ISNULLABLE=1 THEN '√'ELSE '' END,
默认值 = case when E.TEXT is not null then
case when substring(e.text,1,2)='((' then substring(e.text,3,len(e.text)-4)
when substring(e.text,1,1)='(' then substring(e.text,2,len(e.text)-2)
else e.text end
else '' end ,
列说明 = ISNULL(G.[VALUE],'')
FROM SYSCOLUMNS A LEFT JOIN SYSTYPES B ON A.XUSERTYPE=B.XUSERTYPE
INNER JOIN SYSOBJECTS D ON A.ID=D.ID AND D.XTYPE='U' AND D.NAME<>'DTPROPERTIES'
LEFT JOIN SYSCOMMENTS E ON A.CDEFAULT=E.ID
LEFT JOIN sys.extended_properties G ON A.ID=G.major_id AND A.COLID=G.minor_id
LEFT JOIN sys.extended_properties F ON D.ID=F.major_id AND F.minor_id=0
WHERE D.NAME IN ('area','','')
ORDER BY A.ID,A.COLORDER
查询表结构SQL
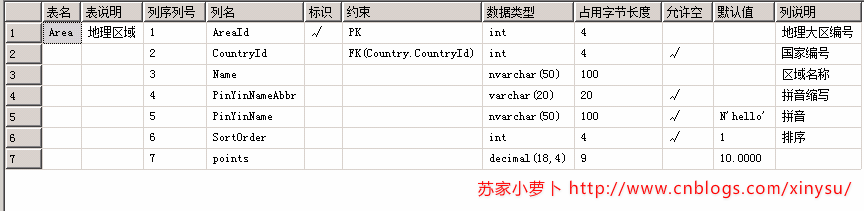
2 数据行
2.1 数据行结构
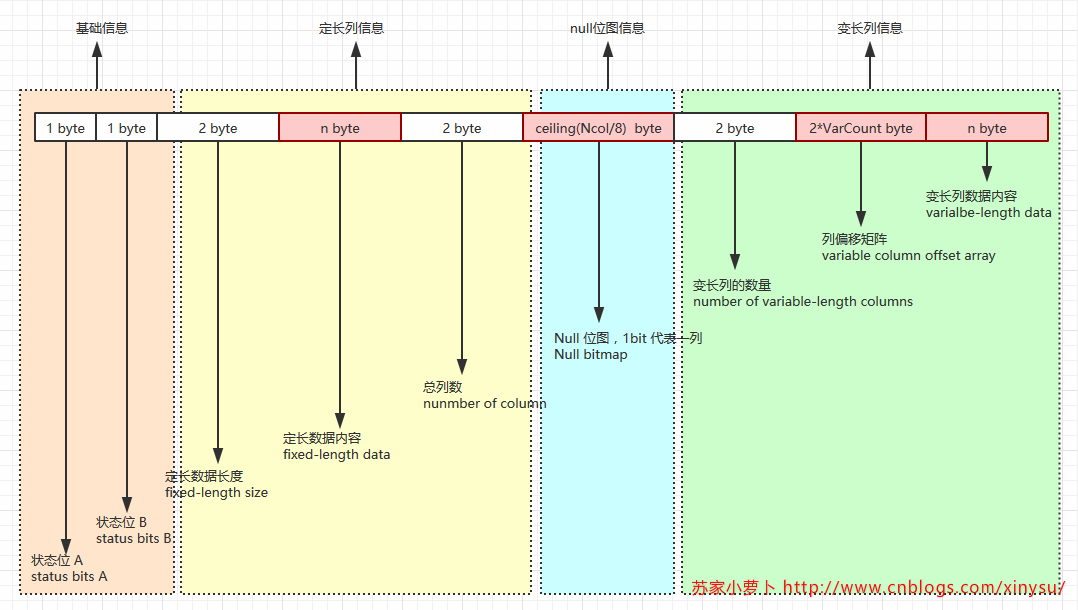
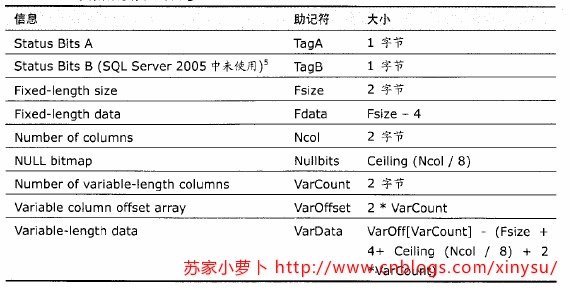
- 状态位A:表示行属性的位图,1字节,8bit
- Bit 0 位,版本信息
- Bits 1-3 位,行记录类型
- 0,primary record,主记录
- 1,forwarded record
- 2,forwarding stub
- 3,index record,索引记录
- 4,blob或者行溢出数据
- 5,ghost索引记录
- 6,ghost数据记录
- Bit 4 位,NULL位图
- Bit 5 位,表示行中有变长列
- Bit 6 位,保留
- Bit 7 位,ghost record(幽灵记录)
- 列偏移矩阵
- 如果一个表格,没有变长列,那么这个表格则不需要列偏移矩阵
- 一个变长列,有一个列偏移矩阵,一个列偏移矩阵2个字节,用于表示变长列中每个列的结束位置。
2.2 特殊情况(大对象、行溢出及forword)
2.2.1 大对象
2.2.2 行溢出
2.2.3 forword
3 测试存储情况
- 先建立一个只有2列非空定长列的堆表,然后INSERT一行数据,检查page页面存储内容
- 添加主键,检查存储页面内容
- 增加一列:可空变长列
- 增加一列:非空变长列+默认值(分大对象和非大对象)
- 删除无数据的列
- 删除有数据的列
- 行溢出
- forword
3.1 堆表分析



3.2 添加主键


3.3 增加一列:可空变长列

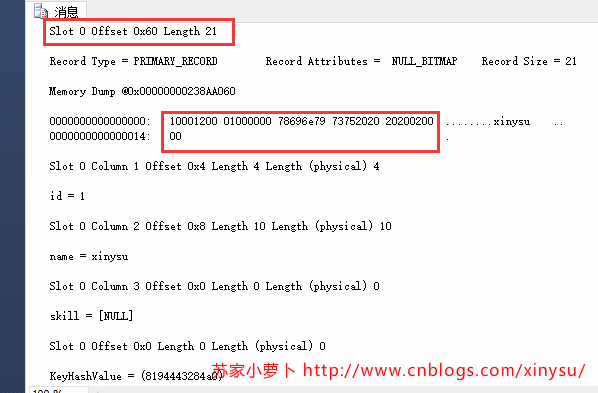
3.4 增加一列:非空变长列+默认值
3.4.1 非大对象列




3.5 删除无数据的列

3.6 删除有数据的列

3.7 行溢出


3.8 Forword


4 行结构与DDL
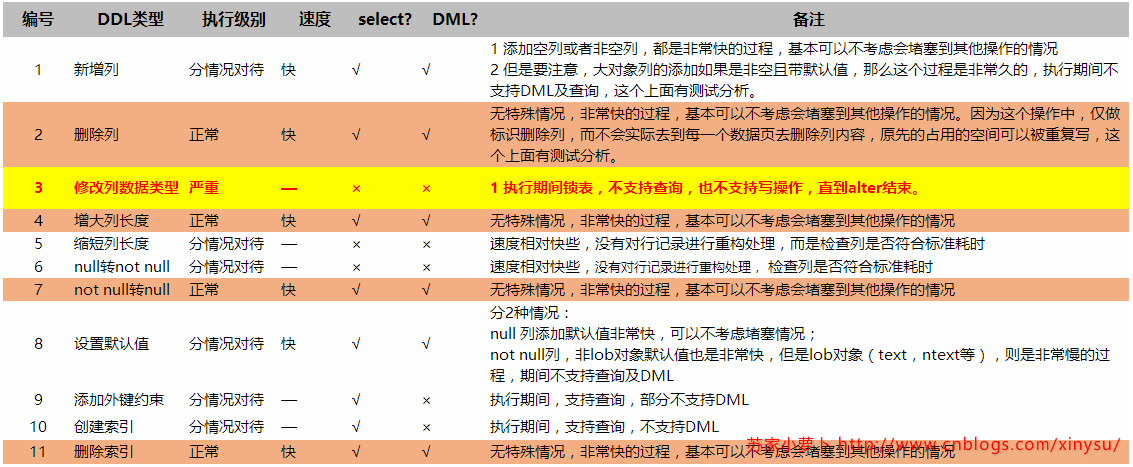
SQL SERVER大话存储结构(3)_数据行的行结构的更多相关文章
- SQL SERVER大话存储结构(6)_数据库数据文件
数据库文件有两大类:数据文件跟日志文件,每一个数据库至少各有一个数据文件或者日志文件,数据文件用来存储数据,日志文件用来存储数据库的事务修改情况,可用于恢复数据库使用. 这里分 ...
- SQL SERVER大话存储结构(4)_复合索引与包含索引
索引这块从存储结构来分,有2大类,聚集索引和非聚集索引,而非聚集索引在堆表或者在聚集索引表都会对其 键值有所影响,这块可以详细查看本系列第二篇文章:SQL SERVER大话存储结构 ...
- SQL SERVER大话存储结构(5)_SQL SERVER 事务日志解析
本系列上一篇博文链接:SQL SERVER大话存储结构(4)_复合索引与包含索引 1 基本介绍 每个数据库都具有事务日志,用于记录所有事物以及每个事物对数据库所作的操作. 日志的记录 ...
- SQL SERVER大话存储结构(1)_数据页类型及页面指令分析
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! SQLServer的数据页大 ...
- SQL SERVER大话存储结构(2)_非聚集索引如何查找到行记录
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! 1 行记录如何存储 这里引入两个 ...
- 人人都是 DBA(VIII)SQL Server 页存储结构
当在 SQL Server 数据库中创建一张表时,会在多张系统基础表中插入所创建表的信息,用于管理该表.通过目录视图 sys.tables, sys.columns, sys.indexes 可以查看 ...
- 使用Spark加载数据到SQL Server列存储表
原文地址https://devblogs.microsoft.com/azure-sql/partitioning-on-spark-fast-loading-clustered-columnstor ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
- SQL Server ---(CDC)监控表数据(转译)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 实现过程(Realization) 补充说明(Addon) 参考文献(References) ...
随机推荐
- 数据库CAST()函数和CONVERT()函数比较
对简单类型转换,CAST()函数和CONVERT()函数的效果一致,只是语法不同.前者更易使用,而后者的优势是格式化时间和数值.在以下这几种情况,二者一样: 1-1.SELECT CONVERT(de ...
- nginx 入门配置
这个星期公司的定期分享内容是Nginx,于是就要写作业了. 一.动静分离 1.下载Windows 版本的Nginx,解压,放到C盘下.进入目录,然后按然shift键右键,打开命令行,输入: start ...
- 【Java进阶】——初识数据库连接池
[简介] 数据库连接池:程序启动时建立足够的数据库连接,并将这些连接组成一个连接池,由程序动态地对池中的链接进行申请,使用,释放. 相比之前的程序连接,减少了数据库的打开关闭次数,从而减少了程序响应的 ...
- 微信小程序登录数据解密以及状态维持
学习过小程序的朋友应该知道,在小程序中是不支持cookie的,借助小程序中的缓存我们也可以存储一些信息,但是对于一些比较重要的信息,我们需要通过登录状态维持来保存,同时,为了安全起见,用户的敏感信息, ...
- javaScript 基本类型之间转换
在Java中,基本类型之间的强制转换也不是这样的,比如,整数要转换成字符串,必须使用Integer.toString()静态方法或者String.valueOf()静态方法,把字符串转换为整数,必须使 ...
- MySQL用户认证及权限grant-revoke
一.MySQL用户认证: 登录并不属于访问控制机制,而属于用户身份识别和认证: 1.用户名-user 2.密码-password 3.登录mysqld主机-host 实现用户登录MySQL,建立连接. ...
- Mybatis(一) mybatis入门
学习了hibernate这个持久层框架之后,在来学习Mybatis简直是无压力,因为Mybatis入门门栏很低,如果学习过了hibernate的话,对于Mybatis的学习很简单了,如果没学习过hib ...
- Linux--管道pipe
管道是一种最基本的IPC机制,由pipe函数创建:#include <unistd.h> int pipe(int filedes[2]); 调用pipe函数时在内核中开辟一块缓冲区(称为 ...
- URL传中文参数导致乱码的解决方案之encodeURI
通过URL传中文参数时,在服务端后台获取到的值往往会出现乱码问题,解决方案有很多种,本文主要介绍如何通过encodeURI来解决中文乱码问题: first:前端传递参数的时候需要对中文参数进行两次en ...
- C#邮件发送开发经本人测试通过
先准备以下工作 1.先开通邮箱我以QQ邮箱为例 2.开通 POP3/SMTP服务 (如何使用 Foxmail 等软件收发邮件?) 已开启 | 关闭 获取授权码 3.C#开发了先写一个CS文件 pub ...