OpenCV探索之路(二十八):Bag of Features(BoF)图像分类实践
在深度学习在图像识别任务上大放异彩之前,词袋模型Bag of Features一直是各类比赛的首选方法。首先我们先来回顾一下PASCAL VOC竞赛历年来的最好成绩来介绍物体分类算法的发展。
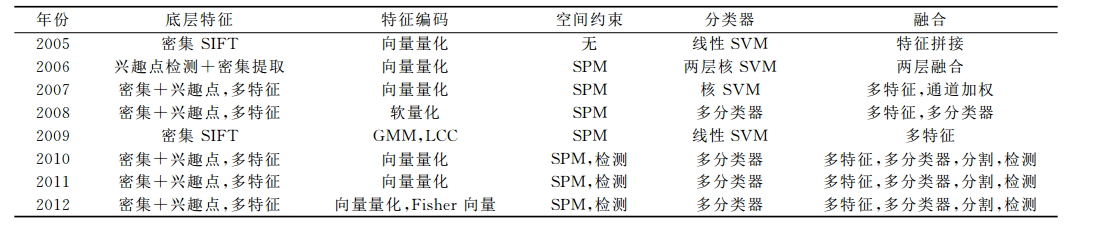
从上表我们可以发现,在2012年之前,词袋模型是VOC竞赛分类算法的基本框架,几乎所有算法都是基于词袋模型的,可以这么说,词袋模型在图像分类中统治了很多年。虽然现在深度学习在图像识别任务中的效果更胜一筹,但是我们也不要忘记在10年前,Bag of Features的框架曾经也引领过一个时代。那这篇文章就是要重温BoF这个经典框架,并从实践上看看它在图像物体分类中效果到底如何。
Bag of Features理论浅谈
其实Bag of Features 是Bag of Words在图像识别领域的延伸,Bag of Words最初产生于自然处理领域,通过建模文档中单词出现的频率来对文档进行描述与表达。

词包模型还有一个起源就是纹理检测(texture recognition),有些图像是由一些重复的基础纹理元素图案所组成,所以我们也可以将这些图案做成频率直方图,形成词包模型。
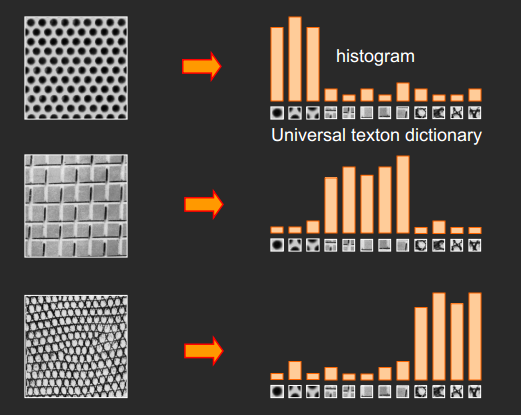
词包模型于2004年首次被引入计算机视觉领域,由此开始大量集中于词包模型的研究,在各类图像识别比赛中也大放异彩,逐渐形成了由下面4部分组成的标准物体分类框架:
- 底层特征提取
- 特征编码
- 特征汇聚
- 使用SVM等分类器进行分类
2005年第一届PASCAL VOC竞赛 数据库包含了4类物体:摩托车、自行车、人、汽车,训练集加验证集一共684张图像,测试集包含689张图像,数据规模相对较少。从方法上说,采用“兴趣点-SIFT地城特征描述-向量量化编码直方图-支持向量机”得到了最好的物体分类性能,这种方法也就是我们今天所讲的Bag of Features方法。
为什么要用BOF模型描述图像?
SIFT特征虽然也能描述一幅图像,但是每个SIFT矢量都是128维的,而且一幅图像通常都包含成百上千个SIFT矢量,在进行相似度计算时,这个计算量是非常大的,更重要的是,每一幅图提取到的SIFT特征点数目都不一样,所以我们要将这些特征量化(比如生成统计直方图),这样才能进行相似度计算。通行的做法是用聚类算法对这些矢量数据进行聚类,然后用聚类中的一个簇代表BOF中的一个视觉词,将同一幅图像的SIFT矢量映射到视觉词序列生成码本,这样每一幅图像只用一个码本矢量来描述,这样计算相似度时效率就大大提高了。
搭建Bag-of-Features的步骤:
- 特征提取(在这里我们使用很稳定的SIFT算子)
- K-means聚类。将第一步提取到的特征向量及进行聚类,得出N个类心。

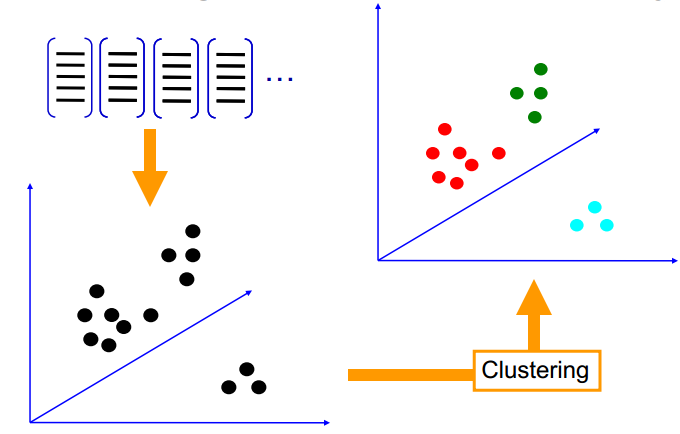
- 量化特征,形成词袋

- 统计每一类别的视觉单词出现频率,形成视觉单词直方图
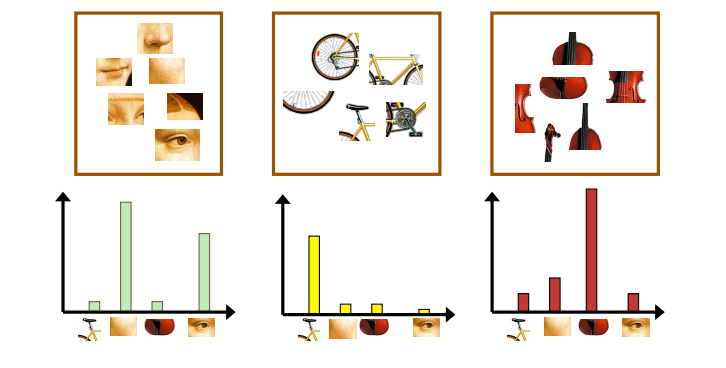
5.训练SVM分类器
实践篇
要编码实现BoF,其实只需严格按照上述讲的步骤进行就可以了,而且OpenCV给我们准备了关于BoF的相关API,所以实现起来的难度进一步降低。现在我们要思考的的是,怎么把opencv所提供的的这些API重新整合在一起,来构成一个分类能力还不错的图像分类器。
今天还是以票据分类任务为例子讲解BoF模型。
先观察数据集,我们已经分出了训练集和测试集

每一类图片放在不同的文件夹下面,文件夹的名字就是这个类别的label
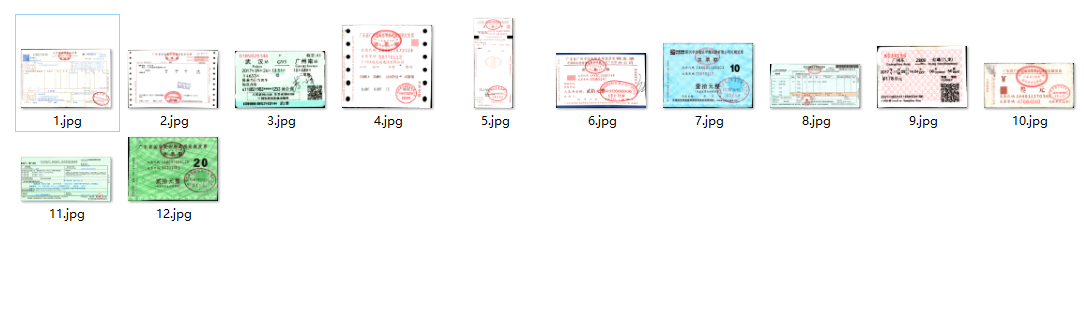
这是我们要分类的12种票据
一、特征提取
对底层特征,我们选择的还是最为经典的SIFT特征,用opencv做SIFT特征提取只需要用到几个API就可以了。
我们还是老套路,先准备好一些提取SIFT特征的数据结构和描述SIFT的一些类。
//create Sift feature point extracter
static Ptr<FeatureDetector> detector1(new SiftFeatureDetector());
//create Sift descriptor extractor
static Ptr<DescriptorExtractor> extractor(new SiftDescriptorExtractor);
//To store the keypoints that will be extracted by SIFT
vector<KeyPoint> keypoints;
//To store the SIFT descriptor of current image
Mat descriptor;
//To store all the descriptors that are extracted from all the images
Mat featuresUnclustered;
//The SIFT feature extractor and descriptor
SiftDescriptorExtractor detector;
然后我们对我们的训练样本进行遍历,对每一类的训练图片进行SIFT特征提取,并将提取出来的特征存进featuresUnclustered里,用于接下来的k-means聚类。
/*第一步,计算目录下所有训练图片的features,放进featuresUnclustered*/
printf("step1:sift features extracting...\n");
for (int num = 1; num < MAX_TRAINING_NUM; num++)
{
sprintf(filename, ".\\training\\%d\\train.txt", num);
//首先先检查一下该类文件夹下有没有用于train的特征文件,有的话就不需要提取特征点了
if (_access(filename, 0) == -1)
{
printf("extracting features %d class\n", num);
for (int i = 1; i <= MAX_TRAINING_NUM; i++)
{
sprintf(filename, ".\\training\\%d\\%d.jpg", num, i);
//create the file name of an image
//open the file
input = imread(filename, CV_LOAD_IMAGE_GRAYSCALE); //Load as grayscale
if (input.empty())
{
break;
}
//resize:reduce keypoints numbers to accerlate
resize(input, input, Size(), 0.5, 0.5);
//detect feature points
detector.detect(input, keypoints);
printf("keypoints:%d\n", keypoints.size());
//compute the descriptors for each keypoint
detector.compute(input, keypoints, descriptor);
//save descriptor to file
char train_name[32] = { 0 };
sprintf(train_name, ".\\training\\%d\\train.txt", num);
WriteFeatures2File(train_name, descriptor);
//put the all feature descriptors in a single Mat object
featuresUnclustered.push_back(descriptor);
//train_features[num][i].push_back(descriptor);
}
}
else
{
Mat descriptor;
load_features_from_file(filename, descriptor);
featuresUnclustered.push_back(descriptor);
}
}
需要注意的是,我在特征提取阶段把每一类提取到的特征都写进了txt文件中,只是为了以后增加类别时,我们不再需要再次遍历提取特征,而只需读入我们原先存有特征向量的txt文件就可以了,这将大大加快训练速度。
static int load_features_from_file(const string& file_name,Mat& features)
{
FILE* fp = fopen(file_name.c_str(), "r");
if (fp == NULL)
{
printf("fail to open %s\n", file_name.c_str());
return -1;
}
printf("loading file %s\n", file_name.c_str());
vector<float> inData;
while (!feof(fp))
{
float tmp;
fscanf(fp, "%f", &tmp);
inData.push_back(tmp);
}
//vector to Mat
int mat_cols = 128;
int mat_rows = inData.size() / 128;
features = Mat::zeros(mat_rows, mat_cols, CV_32FC1);
int count = 0;
for (int i = 0; i < mat_rows; i++)
{
for (int j = 0; j < mat_cols; j++)
{
features.at<float>(i, j) = inData[count++];
}
}
return 0;
}
static int WriteFeatures2File(const string& file_name,const Mat& features)
{
FILE* fp = fopen(file_name.c_str(), "a+");
if (fp == NULL)
{
printf("fail to open %s\n", file_name.c_str());
return -1;
}
for (int i = 0; i < features.rows; i++)
{
for (int j = 0; j < features.cols; j++)
{
int data = features.at<float>(i, j);
fprintf(fp, "%d\t", data);
}
fprintf(fp,"\n");
}
fclose(fp);
return 0;
}
二、特征聚类
我们将上一步得到的训练集的所有特征进行聚类,聚类初始化方式选择means++,类心数量选择1000。这里需要说明一下,聚类的类心数量是一个超参数,是一个需要反复调整的参数,如果类心过少,那就表示BOF模型的视觉单词数目很少,即该模型的表达能力很低,很可能在分类任务中不能区分出每一类物体(有点像Deep Learning中说的欠拟合);但类心过多,就会造成视觉单词过于分散,很可能导致模型在泛化效果不佳(过拟合)。所以,选择一个合理的类心数目很重要。
/*第二步,定义好聚类的中心数目,进行聚类,并得到词典dictionary*/
printf("step2:clusting...\n");
int dictionarySize = 1000; //类心数目,即codebook num
//define Term Criteria
TermCriteria tc(CV_TERMCRIT_ITER, 1000, 0.001); //最大迭代1000次
//retries number
int retries = 1;
//necessary flags
int flags = KMEANS_PP_CENTERS; //kmeans++初始化
//Create the BoW (or BoF) trainer
BOWKMeansTrainer bowTrainer(dictionarySize, tc, retries, flags);
//cluster the feature vectors
Mat dictionary = bowTrainer.cluster(featuresUnclustered); //聚类
//store the vocabulary
FileStorage fs(".\\dictionary1.yml", FileStorage::WRITE); //将聚类后的结果写入文件
fs << "vocabulary" << dictionary;
fs.release();
cout << "Saving BoW dictionary\n";
这个聚类时间还是比较长的,大概需要20分钟。
三、量化特征,形成词典直方图
/*第三步,计算每个类别的词典直方图*/
printf("step3:generating dic histogram...\n");
//create a nearest neighbor matcher
Ptr<DescriptorMatcher> matcher(new FlannBasedMatcher);
//create Sift feature point extracter
Ptr<FeatureDetector> detector1(new SiftFeatureDetector());
//create Sift descriptor extractor
Ptr<DescriptorExtractor> extractor(new SiftDescriptorExtractor);
//create BoF (or BoW) descriptor extractor
BOWImgDescriptorExtractor bowDE(extractor, matcher);
//Set the dictionary with the vocabulary we created in the first step
bowDE.setVocabulary(dictionary);
cout << "extracting histograms in the form of BOW for each image " << endl;
Mat labels(0, 1, CV_32FC1);
Mat trainingData(0, dictionarySize, CV_32FC1);
int k = 0;
vector<KeyPoint> keypoint1;
Mat bowDescriptor1;
Mat img2;
//extracting histogram in the form of bow for each image
for (int num = 1; num <= MAX_TRAINING_NUM; num++)
{
for (int i = 1; i <= MAX_TRAINING_NUM; i++)
{
sprintf(filename, ".\\training\\%d\\%d.jpg", num,i);
//sprintf(filename, "%d%s%d%s", j, " (", i, ").jpg");
img2 = cvLoadImage(filename, 0);
if (img2.empty())
{
break;
}
resize(img2, img2, Size(), 0.5, 0.5);
detector.detect(img2, keypoint1);
bowDE.compute(img2, keypoint1, bowDescriptor1);
trainingData.push_back(bowDescriptor1);
labels.push_back((float)num);
}
}
四、训练SVM
我们使用SVM作为分类器进行训练,训练好的数据以文件的形式存储下来,以后预测时直接读文件就可以还原模型了。
/*第四步,训练SVM得到分类模型*/
printf("SVM training...\n");
CvSVMParams params;
params.kernel_type = CvSVM::RBF;
params.svm_type = CvSVM::C_SVC;
params.gamma = 0.50625000000000009;
params.C = 312.50000000000000;
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 1000, 0.000001);
CvSVM svm;
bool res = svm.train(trainingData, labels, cv::Mat(), cv::Mat(), params);
svm.save(".\\svm-classifier1.xml");
delete[] filename;
printf("bag-of-features training done!\n");
六、预测
首先我们需要载入我们训练好的数据(svm-classifier1.xml和dictionary1.yml)
//字典文件、SVM训练文件读入内存
void TrainingDataInit()
{
FileStorage fs(".\\dictionary1.yml", FileStorage::READ);
Mat dictionary;
fs["vocabulary"] >> dictionary;
fs.release();
bowDE.setVocabulary(dictionary);
svm.load(".\\svm-classifier1.xml");
}
然后再写一个预测函数,用SVM实现线上分类。
//实现发票图像的分类,返回值即预测的分类结果
int invoice_classify(Mat& img)
{
Mat img2 = img.clone();
resize(img2, img2, Size(), 0.5, 0.5);
cvtColor(img2, img2, CV_RGB2GRAY);
SiftDescriptorExtractor detector;
vector<KeyPoint> keypoint2;
Mat bowDescriptor2;
Mat img_keypoints_2;
detector.detect(img2, keypoint2);
bowDE.compute(img2, keypoint2, bowDescriptor2);
int it = svm.predict(bowDescriptor2);
return it;
}
现在开始测试,写一个测试函数,读入测试集进行预测,计算其准确率
void TestClassify()
{
int total_count = 0;
int right_count = 0;
string tag;
for (int num = 1; num < 30; num++)
{
for (int i = 1; i < 30; i++)
{
char path[128] = { 0 };
sprintf(path, ".\\test\\%d\\%d.jpg", num, i);
Mat img = imread(path,0);
if (img.empty())
{
continue;
}
int type = invoice_classify(img);
if (type == -1)
{
printf("reject image %s\n", path);
continue;
}
total_count++;
if (num == type)
{
tag = "CORRECT";
right_count++;
}
else
{
tag = "WRRONG";
}
printf("[%s] label: %d predict: %d, %s\n", path, num, type, tag.c_str());
}
}
printf("total image:%d acc:%.2f\n", total_count,(float)right_count/total_count);
}
完整的流程如下:先建立BoF模型,然后更新训练数据,将训练参数保存至文件。当线上预测时,先将训练参数读入内存,再利用模型对图片进行分类。模拟测试代码如下:
#include "bof.h"
int main()
{
BuildDictionary(12,6);
TrainingDataInit();
TestClassify();
return 0;
}
训练:

预测结果:
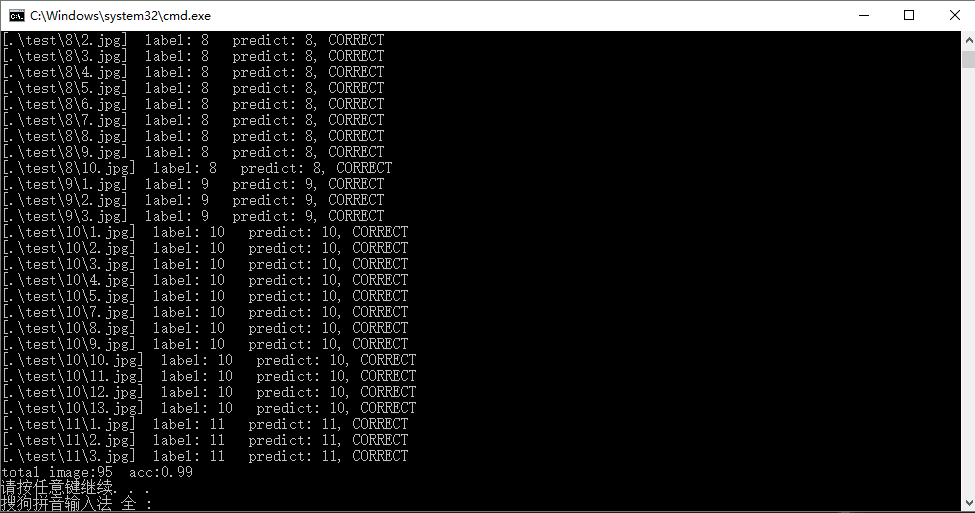
可以看出,BoF模型在这种简单分类任务的效果还可以,更重要的是我每一类只用了6张训练样本(小样本集)就可以有这个效果了,如果是采用深度学习做分类,这个估计不行了。
再优化
总体而言,2005年提出来的Bag-of-Features的分类效果并不是很好,尤其是一些比较像的类别,它的区分能力还是不足的。那能不能可以做哪些优化进一步提升分类准确率呢?我觉得可以从以下几点入手试一试:
- kmeans类心数目调整
- 增加每一类训练图片的数目
- 可以加入颜色特征,比如颜色直方图。个人认为这个措施会有较大效果,因为SIFT特征点提取时,图片已经是灰度图了,所以颜色这个很重要的特征并没有用上。
- 加入一些全局特征做特征融合,因为SIFT是局部特征,所以如果有一些全局特征作为补充的话,效果会有比较好的提升。
- 空间域金字塔思路(CVPR2006)
完整的代码可以在我的github上获取。
总结
在今天看来,曾经引领过一个时代的Bag-of-Features在普通分类任务上并没有取得让人满意的效果,但我估计它在场景分类或图像检索上还是会比较出色(比如地标)。现在已经全面进入深度学习的时代了,BoF的概念越来越淡出人们的视野,但BoF模型在某些应用场景还是很有潜力的。
OpenCV探索之路(二十八):Bag of Features(BoF)图像分类实践的更多相关文章
- OpenCV探索之路(十八):使用imwrite调整保存的图片质量
近日在用opencv做一些图像处理的操作时,需要对一些高分辨率的图像进行保存.比如,在操作一个容量为230M的图像后,并对该图像保存为JPG格式后,发现图像容量变为80M了!针对这个问题,忙了大半天, ...
- Bootstrap <基础二十八>列表组
列表组.列表组件用于以列表形式呈现复杂的和自定义的内容.创建一个基本的列表组的步骤如下: 向元素 <ul> 添加 class .list-group. 向 <li> 添加 cl ...
- Web 前端开发人员和设计师必读文章推荐【系列二十八】
<Web 前端开发精华文章推荐>2014年第7期(总第28期)和大家见面了.梦想天空博客关注 前端开发 技术,分享各类能够提升网站用户体验的优秀 jQuery 插件,展示前沿的 HTML5 ...
- Citrix 服务器虚拟化之二十八 XenApp6.5发布文档内容
Citrix 服务器虚拟化之二十八 XenApp 6.5发布文档内容 XenApp可发布以下类型的资源向用户提供信息访问,这些资源可在服务器或桌面上虚拟化: 1) 服务器桌面:发布场中服务器的整个 ...
- WCF技术剖析之二十八:自己动手获取元数据[附源代码下载]
原文:WCF技术剖析之二十八:自己动手获取元数据[附源代码下载] 元数据的发布方式决定了元数据的获取行为,WCF服务元数据架构体系通过ServiceMetadataBehavior实现了基于WS-ME ...
- VMware vSphere 服务器虚拟化之二十八 桌面虚拟化之安装View传输服务器
VMware vSphere 服务器虚拟化之二十八 桌面虚拟化之安装View传输服务器 View 传输服务器用于管理和简化数据中心与在最终用户本地系统上检出使用的 View 桌面之间的数据传输.必须安 ...
- Bootstrap入门(二十八)JS插件5:工具提醒
Bootstrap入门(二十八)JS插件5:工具提醒 工具提示在使用过程中比较常见,但是实现起来有些麻烦,而bootstrap则很好地解决了这个问题. 我们来写一个简单的实例 先引入CSS文件和JS文 ...
- mysql进阶(二十八)MySQL GRANT REVOKE用法
mysql进阶(二十八)MySQL GRANT REVOKE用法 MySQL的权限系统围绕着两个概念: 认证->确定用户是否允许连接数据库服务器: 授权->确定用户是否拥有足够的权限执 ...
- JAVA之旅(二十八)——File概述,创建,删除,判断文件存在,创建文件夹,判断是否为文件/文件夹,获取信息,文件列表,文件过滤
JAVA之旅(二十八)--File概述,创建,删除,判断文件存在,创建文件夹,判断是否为文件/文件夹,获取信息,文件列表,文件过滤 我们可以继续了,今天说下File 一.File概述 文件的操作是非常 ...
随机推荐
- jquery.editable-select 可编辑下拉框之获取select值和input值
使用jquery.editable-select可以实现可编辑下拉框的功能,但需要先导入jquery.js,jquery.editable-select.css,jquery.editable-sel ...
- appendChild方法详解
方法:target.appendChild(ele); 执行该方法时,会发生两部操作: 1.将元素ele从原来的父元素中移除掉 2.将元素追加至新的目标元素中,并且保留元素的所有样式信息和事件... ...
- 常见的XSS攻击代码
第一类: <tag on*=*/> 在html标签事件中触发,典型的是on*事件,但是这种触发模式的缺陷在于不能直接触发所以更多的需要配合使用. eg: 1.使html元素占据整个显示页面 ...
- Linux学习(二十)软件安装与卸载(三)源码包安装
一.概述 源码包安装的优点在于它自由程度比较高,可以指定目录与组件.再有,你要是能改源码也可以. 二.安装方法 步骤 1.从官网或者信任站点下载源码包 [root@localhost ~]# wget ...
- 小米/红米导入VCF联系人乱码问题解决
PS:尽量不要用什么豌豆荚啊.微信啊.QQ啊之类的通讯录备份,那就等于把自己的通讯录免费送给腾讯他们了....还是自己手动的好一些,但是小白用户或者经常丢手机的卖就卖吧,总比联系人都丢了要好~~~ 默 ...
- IDEA搭建SSMM框架(详细过程)
IDEA搭建SSMM框架(详细过程) 相关环境 Intellij IDEA Ultimate Tomcat JDK MySql 5.6(win32/win64) Maven (可使用Intellij ...
- scrapy爬虫框架之理解篇(个人理解)
提问: 为什么使用scrapy框架来写爬虫 ? 在python爬虫中:requests + selenium 可以解决目前90%的爬虫需求,难道scrapy 是解决剩下的1 ...
- 谈谈如何用eoLinker管理各类API接口及分享API接口管理小技巧教程
在前后端分离的开发模式下,前后端往往需要接口文档来进行交互.我的上一篇随笔中已经写到用传统的文档写接口时,由于需求经常变动,接口文档也会随之变动.一开始,某接口信息已经写入文档,但后期因为需求变动,发 ...
- 一篇不错的Gibbs Sampling解释文章,通俗易懂
http://cos.name/2013/01/lda-math-mcmc-and-gibbs-sampling/ 直接原文的链接了.原文写的不错,是中文博客中说的比较明白的了. 但为了保留文章,随 ...
- Maven创建父子工程(简单、完整)
Eclipse创建Maven父子工程(书中有的叫聚合工程,因为看了网上很多教程,实际操作总会有这样那样的小问题,有时候包结构还不对,创建成功后索性就自己写一篇帮助小白,有不对请指教) 1 file-n ...