大数据测试之初识Hadoop
大数据测试之初识Hadoop
POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的case或者开发测试工具完成不同类型的测试。其实自动化测试涉及面非常之广,目前来讲,case基本都可以写成自动化,而性能测试的脚本开发要围绕业务和协议特点来完成开发,并测试完成后依靠软件分析工具对被测试系统进行评估测试。
未来的技术趋势是云测试,大数据测试,安全性测试,这些要完成测试都需要自动化来完成,而自动化测试的case和工具需要测试开发工程师来完成。 poptest为了适应未来的测试人员的能力要求,寻找bat的一线测试专家开发了大数据测试的课程,课程的提纲可以到www.poptest.cn上查看,由于海量数据的增多,大数据会引起未来人的生活变化,也会出现新的商业模式,我觉得以下三个方向会有机会:1、数据源方向,国内一些政府部门的信息采集公司,如移动、统计局等,这些部门的数据是很丰富的,但是要经过专业的分类及数据采集才会有用,那么大数据会在这一领域产生大量的采集公司;2、数据加工方向,大数据的亮点就是在数据加工后能找到便捷有效的管理、营销、精准推销的方法和人群。也指数据分析;3、数据分析报告及推广。大数据有证据显示可有效地为政府提供决策支持,为企业提供有效的营销指导。但是这些报告的真实性有效性需要有权威的机构去证明和核实。所以报告的出台及报告的推广也会是大数据行业里的又一细分领域。后续我会普及一些大数据测试方面的测试,今天先讲讲hadoop.
Hadoop历史
雏形开始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
随后在2003年Google发表了一篇技术学术论文谷歌文件系统(GFS)。GFS也就是google File System,google公司为了存储海量搜索数据而设计的专用文件系统。
2004年Nutch创始人Doug Cutting基于Google的GFS论文实现了分布式文件存储系统名为NDFS。
2004年Google又发表了一篇技术学术论文MapReduce。MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行分析运算。
2005年Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。
2006年,Yahoo雇用了Doug Cutting,Doug Cutting将NDFS和MapReduce升级命名为Hadoop,Yahoo开建了一个独立的团队给Goug Cutting专门研究发展Hadoop。
不得不说Google和Yahoo对Hadoop的贡献功不可没。
Hadoop核心
Hadoop的核心就是HDFS和MapReduce,而两者只是理论基础,不是具体可使用的高级应用,Hadoop旗下有很多经典子项目,比如HBase、Hive等,这些都是基于HDFS和MapReduce发展出来的。要想了解Hadoop,就必须知道HDFS和MapReduce是什么。
HDFS
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
HDFS的设计特点是:
1、大数据文件,非常适合上T级别的大文件或者一堆大数据文件的存储,如果文件只有几个G甚至更小就没啥意思了。
2、文件分块存储,HDFS会将一个完整的大文件平均分块存储到不同计算器上,它的意义在于读取文件时可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得都。
3、流式数据访问,一次写入多次读写,这种模式跟传统文件不同,它不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
4、廉价硬件,HDFS可以应用在普通PC机上,这种机制能够让给一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
5、硬件故障,HDFS认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
HDFS的关键元素:
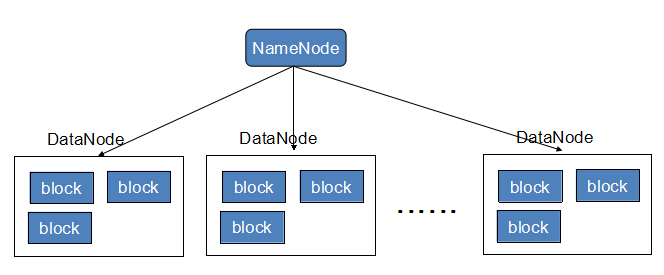
Block:将一个文件进行分块,通常是64M。
NameNode:保存整个文件系统的目录信息、文件信息及分块信息,这是由唯一一台主机专门保存,当然这台主机如果出错,NameNode就失效了。在Hadoop2.*开始支持activity-standy模式----如果主NameNode失效,启动备用主机运行NameNode。
DataNode:分布在廉价的计算机上,用于存储Block块文件。
MapReduce
通俗说MapReduce是一套从海量·源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。
下面以一个计算海量数据最大值为例:一个银行有上亿储户,银行希望找到存储金额最高的金额是多少,按照传统的计算方式,我们会这样:
Long moneys[] ...
Long max = 0L;
for(int i=0;i<moneys.length;i++){
if(moneys[i]>max){
max = moneys[i];
}
}
如果计算的数组长度少的话,这样实现是不会有问题的,还是面对海量数据的时候就会有问题。
MapReduce会这样做:首先数字是分布存储在不同块中的,以某几个块为一个Map,计算出Map中最大的值,然后将每个Map中的最大值做Reduce操作,Reduce再取最大值给用户。

MapReduce的基本原理就是:将大的数据分析分成小块逐个分析,最后再将提取出来的数据汇总分析,最终获得我们想要的内容。当然怎么分块分析,怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据。
总结
总的来说Hadoop适合应用于大数据存储和大数据分析的应用,适合于服务器几千台到几万台的集群运行,支持PB级的存储容量。
Hadoop典型应用有:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。
但要知道,Hadoop的使用范围远小于SQL或Python之类的脚本语言,所以不要盲目使用Hadoop,看完这篇试读文章,我知道Hadoop不适用于我们的项目。不过Hadoop作为大数据的热门词,我觉得一个狂热的编程爱好者值得去学习了解,或许你下一个归宿就需要Hadoop人才,不是吗。
原文链接:http://www.cnblogs.com/laoli0201
大数据测试之初识Hadoop的更多相关文章
- 【大数据】初识Hadoop
因为项目日志体量较大,每天有4-7T的日志量,传统的sqlserver已经不能满足,所以现在需要使用到大数据的相关工具进行记录和使用. 虽然公共项目提供了组件和解决方案,但是对于一些名词.概念还是有必 ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- [Hadoop大数据]——Hive初识
Hive出现的背景 Hadoop提供了大数据的通用解决方案,比如存储提供了Hdfs,计算提供了MapReduce思想.但是想要写出MapReduce算法还是比较繁琐的,对于开发者来说,需要了解底层的h ...
- 初识大数据(二. Hadoop是什么)
hadoop是一个由Apache基金会所发布的用于大规模集群上的分布式系统并行编程基础框架.目前已经是大数据领域最流行的开发架构.并且已经从HDFS.MapReduce.Hbase三大核心组件成长为一 ...
- 从Hadoop Summit 2016看大数据行业与Hadoop的发展
前言: 好吧我承认已经有四年多没有更新博客了.... 在这四年中发生了很多事情,换了工作,换了工作的方向.在工作的第一年的时候接触机器学习,从那之后的一年非常狂热的学习机器学习的相关技术,也写了一些自 ...
- ASP.NET + SqlSever 大数据解决方案 PK HADOOP
半个月前看到博客园有人说.NET不行那篇文章,我只想说你们有时间去抱怨不如多写些实在的东西. 1.SQLSERVER优点和缺点? 优点:支持索引.事务.安全性以及容错性高 缺点:数据量达到100万以 ...
- 老李分享:大数据测试之HDFS文件系统
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
随机推荐
- vue生命周期的介绍
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- unity Editor的使用
1.首先定义一个需要控制数值的类,类中定义若干个变量 using UnityEngine;using System.Collections; using UnityEngine; using Syst ...
- unity脚本的运行顺序以及单例的实现
unity引擎把所有脚本先行编译后,在运行的时候一批,一批的函数进行执行. unity脚本自带函数执行顺序如下:将下面脚本挂在任意物体运行即可得到 Awake ->OnEable-> St ...
- 关于Java空指针的控制(转)
1)在已经的String(字符串)调用 equal()和 equalsingnoreCase()而不是未知的对象 通常在已经的非空字符串在调用equals().因为equal()方法是对称的,调用a. ...
- Debian部署RMI异常:java.rmi.ConnectException: Connection refused to host: 127.0.1.1;
现象:在windows上部署RMI很顺利,但移到debian上部署后,客户端报异常: java.rmi.ConnectException: Connection refused to host: 12 ...
- DOM基础(一)
在我们刚刚学JavaScript的时候,就应该听说过,JavaScript是由三部分组成的.分别是ECMAScript,DOM和BOM组成的.ECMAScript是JavaScript的核心,它描述了 ...
- React组件开发经典案例--todolist
点开查看代码 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <me ...
- Xamarin自定义布局系列——瀑布流布局
Xamarin.Forms以Xamarin.Android和Xamarin.iOS等为基础,自己实现了一整套比较完整的UI框架,包含了绝大多数常用的控件,如下图 虽然XF(Xamarin.Forms简 ...
- 1692: [Usaco2007 Dec]队列变换(BZOJ1640强化版)
1692: [Usaco2007 Dec]队列变换 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 682 Solved: 280[Submit][Sta ...
- 浅谈jquery插件开发模式
首先根据<jQuery高级编程>的描述来看,jQuery插件开发方式主要有三种: 通过$.extend()来扩展jQuery 通过$.fn 向jQuery添加新的方法 通过$.widget ...