huffman编码【代码】
哈夫曼编码应该算数据结构“树”这一章最重要的一个问题了,当时大一下学期学的时候没弄懂,一年后现在算是明白了。
首先,讲讲思路。
正好这学期在学算法,这里面就用到了贪心算法,刚好练练手。
整个问题有几个关键点:
1,首先是要思考怎么样存下从txt中读取的所有字符中的每种字符出现的次数,首先想到的应该是结构体数组,再仔细想想不对呀,时间复杂度太高了,每次判断一个字符都对知道它属于结构体数组中的哪一个,那要是txt中有很多字符,那光这个就得花好多时间。然后想想,如果读取的字符如果只有那255个ASCII中的字符时可以直接用一个整形数组来表示呀!数组的下标为整数,整数和字符数不正是通过ASCII码一一对应了吗。当然这些字符必须全部是那255个中的。所以整形数组的大小也只需255.当然了,如果对C++关联容器的知识比较熟悉,用关联容器更方便,毕竟,我们这种方法其实就是在模拟关联容器。
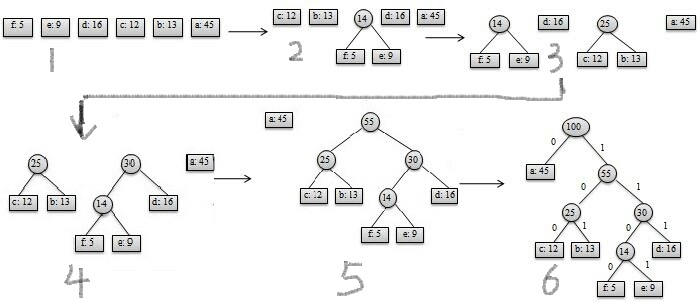
2,然后我们怎么从刚才得到的各个字符的频率来整出一颗哈夫曼树呢?首先,离散数学上讲的构建哈夫曼树应该是比较容易理解的,就是每次选取两个权值(也就是这里的频率)最小的两个节点作为左右孩子(小的在左,大的在右),然后把它们的权值之和作为一个新的待选择的结点去和剩余结点判断,自底向上构建,直到剩余权值最大的一个结点,完毕。虽然这样说着很简单,但是落实到代码就值得思考了。我们该怎么样表示这样一棵树呢?习惯性地用指针?认真思考后我们发现,用指针行不通,因为这棵树是自底向上构建的,我们在构建完成之前是不知道这棵树的遍历序列的,也就没法通过递归的形式来创建这棵树。那么,我们现在应该想到的是用数组,没错,用数组可以!显然是结构体数组,所以得考虑结构体中要有哪些变量,首先要有每个结点表示的字符,对应的权值,还要有左右孩子的下标,双亲的下标。这样就可以在数组中存下这棵树了。
3,在得到哈夫曼树后,该怎么输出每个字符对应的哈夫曼编码呢?从每个叶子结点出发,逐步向根结点方向遍历,每次到达其双亲时,判断自己是双亲的左孩子还是右孩子,如果是左孩子,在该叶子表示的字符对应的编码(用string表示)加上0,否则加上1。然后再找到双亲的双亲,。。。直到到达根结点(根结点没有双亲,对应的双亲下标可以设为0),由于这样得到的编码01字符串是反的,所以我们要反一下就得到了正确的编码。
这里放一个ppt,是我们老师上课讲的,便于理解 http://files.cnblogs.com/files/journal-of-xjx/huffman.pptx
注意我是把一个txt文件中的所有字符读到一个string中去的。自己测试的时候随便放一个input.txt进去就可以了(注意必须是ASCII小于等于255的字符,超过这个范围的字符不能用这种方式表示)
代码如下:
#include <iostream>
#include <fstream>
#include <algorithm> using namespace std; #define NUM_CHARS 256 //读取的字符串中最多出现这么多种字符
#define MAX_FREQ 10000 //最大频率必须小于这个数
#define MAX_SIZE 512 //Huffman Tree结点
typedef struct HuffNode
{
char data;
unsigned int freq;
int parent;
int lchild;
int rchild;
}HuffNode;
//编码结点
typedef struct HuffCode
{
char data;//保存字符
string s;//保存字符对应的编码
}HuffCode; //给定一个字符串,把字符的出现频率保存到freqs数组中
//注意字符出现的频率不能超出unsigned int所能表示的范围
int Create_freq_array(unsigned int (&freqs)[NUM_CHARS],string s, int &char_size)//传入数组的引用,
{
int i, maxfreq = ;
for(int i=;i<NUM_CHARS;i++)
freqs[i] = ;//注意传入的数组的各元素先赋值为0
for(auto iter =s.begin(); iter!=s.end(); iter++)
{
freqs[*iter]++; //*iter为char型,这里转换成了int型,即以某个字符的ASCII码作为
if(freqs[*iter] > maxfreq)//它在freq数组中的下标,注意这种方式不能表示非ASCII码字符!
maxfreq = freqs[*iter];//每次记得更新maxfreq的值
}
for(i=; i<NUM_CHARS; i++)//计算char_size值
{
if(freqs[i])
{
char_size++;
}
}
return ;
} //打印字符频率表
int Print_freqs(unsigned int (&freqs)[NUM_CHARS],int n)
{
int i;
char c;
for(i = ; i < NUM_CHARS; i++)
{
if(freqs[i])
{
c = i;//把i以ASCII码值还原出对应的字符
cout << "字符 " << c << " 出现的频率为:" << freqs[i] << endl;
} }
cout << endl << "以上共出现" << n << "种字符" << endl <<endl;
return ;
} int Build_Huffman_tree(unsigned int (&freqs)[NUM_CHARS],HuffNode (&Huffman_array)[MAX_SIZE],int n)
{ //n表示freqs数组中实际包含的字符种类数
char c;
int k = ,x1,x2;
unsigned int m1, m2; for(int i=;i<NUM_CHARS;i++)//把前n个叶结点的信息输入Huffman_array数组
{
if(freqs[i])
{
c=i;//还原字符
Huffman_array[k].data = c;
Huffman_array[k].freq = freqs[i];
Huffman_array[k].parent = ;
Huffman_array[k].lchild = ;
Huffman_array[k].rchild = ;
k++;
}
}
for(int i=n;i<*n-;i++)//处理剩下n-1个非叶子结点
{
Huffman_array[i].data = '#';
Huffman_array[i].freq = ;
Huffman_array[i].parent = ;
Huffman_array[i].lchild = ;
Huffman_array[i].rchild = ;
}
// 循环构造 Huffman 树
for(int i=; i<n-; i++)
{
m1=m2=MAX_FREQ; // m1、m2中存放两个无父结点且结点权值最小的两个结点
x1=x2=; //x1、x2:构造哈夫曼树不同过程中两个最小权值结点在数组中的序号
/* 找出所有结点中权值最小、无父结点的两个结点,并合并之为一颗二叉树 */
for (int j=; j<n+i; j++)
{
if (Huffman_array[j].freq < m1 && Huffman_array[j].parent==)
{ //如果当前判断的结点的权值小于最小的m1,则把它赋给m1,同时
m2=m1; //更新m1结点的下标, 保持m1是当前所有判断过的元素中是最小的
x2=x1; //再把m1的信息赋给m2,保持m2是当前所有判断过的元素中是第二小的
m1=Huffman_array[j].freq ;
x1=j;
}
else if (Huffman_array[j].freq < m2 &&Huffman_array[j].parent==)
//如果当前判断的结点的权值大于等于最小的m1,但是小于m2,
{ //则只需把它赋给m2,更新m2,保持m2是当前所有判断过的元素中是第二小的
m2=Huffman_array[j].freq ;
x2=j;
}
}
/* 设置找到的两个子结点 x1、x2 的父结点信息 */
Huffman_array[x1].parent = n+i;
Huffman_array[x2].parent = n+i;
Huffman_array[n+i].freq = Huffman_array[x1].freq + Huffman_array[x2].freq ;
Huffman_array[n+i].lchild = x1;
Huffman_array[n+i].rchild = x2;
}
return ;
}
//哈夫曼编码,输出string中各种字符对应的编码
int Huffman_code(HuffNode(&Huffman_array)[MAX_SIZE],HuffCode (&Huffman_code_array)[NUM_CHARS],int n)
{
int temp;
for(int i = ;i < n;i++)
{
temp = i;//当前处理的Huffman_array数组下标
Huffman_code_array[i].data = Huffman_array[i].data;
while(Huffman_array[temp].parent)
{
if(Huffman_array[Huffman_array[temp].parent].lchild == temp)//左孩子为0
{
Huffman_code_array[i].s += '';
}
else//右孩子为1
{
Huffman_code_array[i].s += '';
}
temp = Huffman_array[temp].parent;
}
reverse(Huffman_code_array[i].s.begin(), Huffman_code_array[i].s.end());
} //注意翻转每一个string,这里用到了#include <algorithm>
return ;
} int Print_huffman_code(HuffCode (&Huffman_code_array)[NUM_CHARS],int n)
{
for(int i = ;i < n;i++)
{
cout << "字符 " << Huffman_code_array[i].data << " 对应的哈夫曼编码为:" << Huffman_code_array[i].s << endl;
}
cout << endl;
return ;
} int main()
{
ifstream in("input.txt",ios::in);//从input.txt中读取输入数据
ofstream out("output.txt",ios::out);//向output.txt中写入数据
string s,temp;
int char_size = ;//用以保存string中所包含的字符种类
unsigned int freqs[NUM_CHARS];
HuffNode Huffman_array[MAX_SIZE];
HuffCode Huffman_code_array[NUM_CHARS];
while(getline(in,temp))//按行读取一个txt文件中的各个字符到一个string,每读完一行加上一个'\n'
{
s += temp;
s += '\n';
}
cout << "输入的字符总数为: " << s.size() << endl << endl << "其中:" << endl;//string中包含的字符数
Create_freq_array(freqs,s,char_size);
Print_freqs(freqs,char_size);
Build_Huffman_tree(freqs,Huffman_array,char_size);
Huffman_code(Huffman_array,Huffman_code_array,char_size);
Print_huffman_code(Huffman_code_array,char_size);
return ;
}
参考了别人的一些代码。
huffman编码【代码】的更多相关文章
- [老文章搬家] 关于 Huffman 编码
按:去年接手一个项目,涉及到一个一个叫做Mxpeg的非主流视频编码格式,编解码器是厂商以源代码形式提供的,但是可能代码写的不算健壮,以至于我们tcp直连设备很正常,但是经过一个UDP数据分发服务器之后 ...
- 优先队列求解Huffman编码 c++
优先队列小析 优先队列的模板: template <class T, class Container = vector<T>,class Compare = less< ...
- Huffman编码实现电文的转码与译码
//first thing:thanks to my teacher---chenrong Dalian Maritime university /* 构造Huffman Tree思路: ( ...
- huffman 编码
huffman压缩是一种压缩算法,其中经典的部分就是根据字符出现的频率建立huffman树,然后根据huffman树的构建结果标示每个字符.huffman编码也称为前缀编码,就是每个字符的表示形式不是 ...
- 基于二叉树和数组实现限制长度的最优Huffman编码
具体介绍详见上篇博客:基于二叉树和双向链表实现限制长度的最优Huffman编码 基于数组和基于链表的实现方式在效率上有明显区别: 编码256个符号,符号权重为1...256,限制长度为16,循环编码1 ...
- Jcompress: 一款基于huffman编码和最小堆的压缩、解压缩小程序
前言 最近基于huffman编码和最小堆排序算法实现了一个压缩.解压缩的小程序.其源代码已经上传到github上面: Jcompress下载地址 .在本人的github上面有一个叫Utility的re ...
- 【算法】Huffman编码(数据结构+算法)
1.描述 Huffman编码,将字符串利用C++编码输出该字符串的Huffman编码. Huffman树是一种特殊结构的二叉树,由Huffman树设计的二进制前缀编码,也称为Huffman编码在通信领 ...
- Huffman编码实现文件的压缩与解压缩。
以前没事的时候写的,c++写的,原理很简单,代码如下: #include <cstdio> #include <cstdlib> #include <iostream&g ...
- Huffman编码(Huffman树)
[0]README 0.1) 本文总结于 数据结构与算法分析, 源代码均为原创, 旨在 理解 "Huffman编码(Huffman树)" 的idea 并用源代码加以实现: 0.2) ...
- Huffman编码实现压缩解压缩
这是我们的课程中布置的作业.找一些资料将作业完毕,顺便将其写到博客,以后看起来也方便. 原理介绍 什么是Huffman压缩 Huffman( 哈夫曼 ) 算法在上世纪五十年代初提出来了,它是一种无损压 ...
随机推荐
- 过程 : 概念 : 结构 jobbox jobPost
概念是employer创建jobPost时,可以publish或unpublish. sort expired后,会通过server tast 去更新成history.所有的publish和unpub ...
- 每天一个linux命令(41)--ping命令
Linux系统的 ping 命令是常用的网络命令,它通常用来测试与目标主机的连通性,它通过发送 ICMP ECHO_REQUEST数据包到网络主机(send ICMP ECHO_REQUEST t ...
- 《Django By Example》第七章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者@ucag注:咳咳,第七章终于来了.其 ...
- 在Vue中通过自定义指令获取元素
vue.js 是数据绑定的框架,大部分情况下我们都不需要直接操作 DOM Element,但在某些时候,我们还是有获取DOM Element的需求的: 在 vue.js 中,获取某个DOM Eleme ...
- Eclipse的Spring IDE插件的安装和使用
Spring IDE是Spring官方网站推荐的Eclipse插件,可提供在研发Spring时对Bean定义文件进行验证并以可视化的方式查看各个Bean之间的依赖关系等. 安装 使用Eclipse M ...
- 自己动手编写Maven的插件
Maven的插件机制是完全依赖Maven的生命周期的,因此理解生命周期至关重要.本文参考官方文档后使用archetype创建,手动创建太麻烦. 创建创建项目 选择maven-archetype-moj ...
- Java日志工具之SLF4J
SLF4J全称为Simple Logging Facade for Java (简单日志门面),作为各种日志框架的简单门面或者抽象,包括 java.util.logging, log4j, logba ...
- 安全体系(三)——SHA1算法详解
本文主要讲述使用SHA1算法计算信息摘要的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 安全体系(二)——RSA算法详解 为保 ...
- 某电商网站线上drbd+heartbeat+nfs配置
1.环境 nfs1.test.com 10.1.1.1 nfs2.test.com 10.1.1.2 2.drbd配置 安装drbd yum -y install gcc gcc-c++ make g ...
- 1491: [NOI2007]社交网络
1491: [NOI2007]社交网络 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 881 Solved: 518[Submit][Status] ...