memcached讲解
memcached是一个开源的高性能分布式内存对象缓存系统。
其实思想还是比较简单的,实现包括server端(memcached开源项目一般只单指server端)和client端两部分:
1.server端本质是一个in-memory key-value store,通过在内存中维护一个大的hashmap用来存储小块的任意数据,对外通过统一的简单接口(memcached protocol)来提供操作。
2.client端是一个library,负责处理memcached protocol的网络通信细节,与memcached server通信,针对各种语言的不同实现分装了易用的API实现了与不同语言平台的集成。在接口中我们可以配置不同参数,来满足自己的需求。
3.web系统则通过client库来使用memcached进行对象缓存。
memcached的分布式主要体现在client端,对于server端,仅仅是部署多个memcached server组成集群,每个server独自维护自己的数据(互相之间没有任何通信),通过daemon监听端口等待client端的请求。
而在client端,通过一致的hash算法,将要存储的数据分布到某个特定的server上进行存储,后续读取查询使用同样的hash算法即可定位。
client端可以采用各种hash算法来定位server:取模
最简单的hash算法
targetServer = serverList[hash(key) % serverList.size]
直接用key的hash值(计算key的hash值的方法可以自由选择,比如算法CRC32、MD5,甚至本地hash系统,如java的hashcode)模上server总数来定位目标server。这种算法不仅简单,而且具有不错的随机分布特性。
但是问题也很明显,server总数不能轻易变化。因为如果增加/减少memcached server的数量,对原先存储的所有key的后续查询都将定位到别的server上,导致所有的cache都不能被命中而失效。我们无法对服务器进行简单的增加和减少。
由于简单的hash算法没有良好的扩展性,我们下面来介绍一种更好的方法:一致性hash
相对于取模的算法,一致性hash算法除了计算key的hash值外,还会计算每个server对应的hash值,然后将这些hash值映射到一个有限的值域上(比如0~2^32)。通过寻找hash值大于hash(key)的最小server作为存储该key数据的目标server。如果找不到,则直接把具有最小hash值的server作为目标server。
为了方便理解,可以把这个有限值域理解成一个环,值顺时针递增。
如上图所示,集群中一共有5个memcached server,已通过server的hash值分布到环中。
如果现在有一个写入cache的请求,首先计算x=hash(key),映射到环中,然后从x顺时针查找,把找到的第一个server作为目标server来存储cache,如果超过了2^32仍然找不到,则命中第一个server。比如x的值介于A~B之间,那么命中的server节点应该是B节点
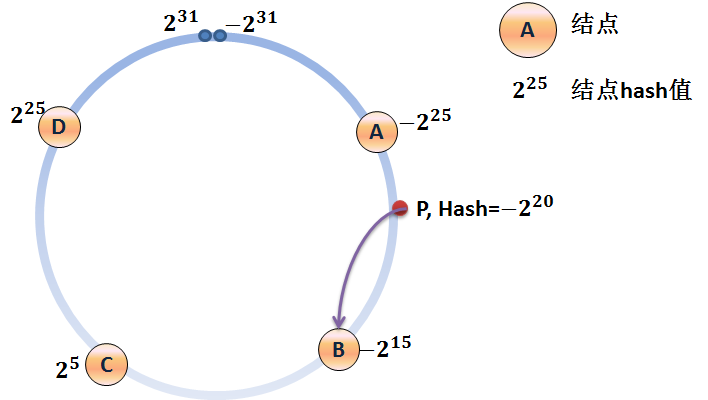
可以看到,通过这种算法,对于同一个key,存储和后续的查询都会定位到同一个memcached server上。
那么它是怎么解决增/删server导致的cache不能命中的问题呢?
假设,现在增加一个server F,如下图
此时,cache不能命中的问题仍然存在,但是只存在于B~F之间的位置(由C变成了F),其他位置(包括F~C)的cache的命中不受影响(删除server的情况类似)。尽管仍然有cache不能命中的存在,但是相对于取模的方式已经大幅减少了不能命中的cache数量。
虚拟节点
但是,这种算法相对于取模方式也有一个缺陷:当server数量很少时,很可能他们在环中的分布不是特别均匀,进而导致cache不能均匀分布到所有的server上。
一共有3台server – 1,2,4。命中4的几率远远高于1和2。
为解决这个问题,需要使用虚拟节点的思想:为每个物理节点(server)在环上分配100~200个点,这样环上的节点较多,就能抑制分布不均匀。
当为cache定位目标server时,如果定位到虚拟节点上,就表示cache真正的存储位置是在该虚拟节点代表的实际物理server上。
另外,如果每个实际server的负载能力不同,可以赋予不同的权重,根据权重分配不同数量的虚拟节点。
通过这种方式我们很好的能够增加删除我们的缓存服务器。
memcached讲解的更多相关文章
- 有关memcached企业面试案例讲解
有关memcached企业面试案例讲解 1.Memcached是什么,有什么作用? a. memcached是一个开源的.高性能的内存的缓存软件,从名称上看Mem就是内存的意思,而Cache就是 ...
- Linux(Cent OS7.2)下启动停止memcached方法及ps命令使用讲解
Linux下,以Cent OS7.2为例,安装memcached后的启动方法很简单,这里我们使用yum源安装. 首先查找yum源版本库的memchaced安装包, yum list | grep me ...
- 第三篇 Nosql讲解之windows下Memcached和Memcache的区别安装(二)
一.Memcached和Memcache的区别: 网上关于Memcached和Memcache的区别的理解众说纷纭,我个人的理解是: Memcached是一个内存缓存系统,而Memcache是php的 ...
- 缓存、队列(Memcached、redis、RabbitMQ)
本章内容: Memcached 简介.安装.使用 Python 操作 Memcached 天生支持集群 redis 简介.安装.使用.实例 Python 操作 Redis String.Hash.Li ...
- Memcached简介
在Web服务开发中,服务端缓存是服务实现中所常常采用的一种提高服务性能的方法.其通过记录某部分计算结果来尝试避免再次执行得到该结果所需要的复杂计算,从而提高了服务的运行效率. 除了能够提高服务的运行效 ...
- 终于等到你---订餐系统之负载均衡(nginx+memcached+ftp上传图片+iis)
又见毕业 对面工商大学的毕业生叕在拍毕业照了,一个个脸上都挂满了笑容,也许是满意自己四年的修行,也许是期待步入繁华的社会... 恰逢其时的连绵细雨与满天柳絮,似乎也是在映衬他们心中那些离别的忧伤,与对 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 【转】Memcached安装
解析:Memcached是什么? Memcached是由Danga Interactive开发的,高性能的,分布式的内存对象缓存系统,用于在动态应用中减少数据库负载,提升访问速度. 一.软件版本 ...
- 在Windows .NET平台下使用Memcached
网上关于Memcached的文章很多,但据我观察,大多是互相转载或者抄袭的,千篇一律.有些则是直接整理的一些超链接然后贴出来.那些超链接笔者大概都进去看了,其实关于Memcached的中文的技术文章, ...
随机推荐
- Azure Powershell对ARM资源的基本操作
本分主要介绍Windows Azure Powershell对ARM资源的基本操作 1.登陆ARM模式,命令:Login-AzureRmAccount -EnvironmentName AzureCh ...
- Sersync+Rsync实现触发式文件同步
背景 通常我们在服务器上使用rsync加上crontab来定时地完成一些同步.备份文件的任务.随着业务和应用需求的不断扩大.实时性要求越来越高.一般rsync是通过校验所有文件后,进行差量同步,如果文 ...
- 深入理解计算机系统(2.3)------布尔代数以及C语言运算符
本篇博客我们主要讲解计算机中的布尔代数以及C语言的几个运算符. 1.布尔代数 我们知道二进制值是计算机编码.存储和操作信息的核心,随着计算机的发展,围绕数值0和1的研究已经演化出了丰富的数学知识体系. ...
- ★10 个实用技巧,让Finder带你飞~
10 个实用技巧,让 Finder 带你飞 Finder 是 Mac 电脑的系统程序,有的功能类似 Windows 的资源管理器.它是我们打开 Mac 首先见到的「笑脸」,有了它,我们可以组织和使用 ...
- 201521123067 《Java程序设计》第6周学习总结
1. 本周学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 2. 书面作业 Q1:clone方法 1.1 Object ...
- 201521123112《Java程序设计》第5周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关多态与接口的知识点 1.2 可选:使用常规方法总结其他上课内容 课上讲了一些Markdown的用法,包括分割线.参考链接.代码引入等等. 2. 书面 ...
- 201521123013 《Java程序设计》第4周学习总结
1. 本章学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. 1.多态是面向对象的三大特性之一.多态的意思:相同的形态,可以实不同的行为.Java中实现多 ...
- 201521123002 《Java程序设计》第1周学习总结
1. 本章学习总结 学习使用Markdown编写文章 jdk的安装和环境变量的设置 java的历史,目前java有三大平台,javaSE,javaEE及javaME.其中javaSE我们会经常用到,由 ...
- 201521123006 《java程序设计》 第10周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. 2. 书面作业 本次PTA作业题集异常.多线程 1.finally 题目4-2 1.1 截图你的提交结果(出 ...
- 201521123103 《java学习笔记》 第十三周学习总结
一.本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 二.书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu.e ...