Hadoop2.7.3分布式集群安装
一、依赖文件安装
1.1 JDK
参见博文:http://www.cnblogs.com/liugh/p/6623530.html
二、文件准备
2.1 文件名称
hadoop-2.7.3.tar.gz
2.2 下载地址
http://hadoop.apache.org/releases.html

三、工具准备
3.1 Xshell
一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。
Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
3.2 Xftp
一个基于 MS windows 平台的功能强大的SFTP、FTP 文件传输软件。
使用了 Xftp 以后,MS windows 用户能安全地在UNIX/Linux 和 Windows PC 之间传输文件。
四、部署图

五、Hadoop安装
以下操作,均使用root用户
5.1 主机名与IP地址映射关系配置
Master节点上,执行如下命令:
#vi /etc/hosts
在文件最后,输入如下内容:
10.10.0.1 DEV-SH-MAP-
10.10.0.2 DEV-SH-MAP-
10.10.0.3 DEV-SH-MAP-
保存,退出,然后通过scp命令,将配置好的文件拷贝其他两个Slave节点:
#scp /etc/hosts root@DEV-SH-MAP-02:/etc
#scp /etc/hosts root@DEV-SH-MAP-03:/etc
5.2 SSH免登陆配置
#ssh-keygen -t rsa
一直回车
然后分别拷贝到Master以及Slave节点:
#ssh-copy-id DEV-SH-MAP-
#ssh-copy-id DEV-SH-MAP-
#ssh-copy-id DEV-SH-MAP-
通过#ssh DEV-SH-MAP-02 测试是否配置成功,如果不需要输入密码,则证明配置成功
5.3 通过Xftp将下载下来的Hadoop安装文件上传到Master及两个Slave的/usr目录下
5.4 通过Xshell连接到虚拟机,在Master及两个Slave上,执行如下命令,解压文件:
# tar zxvf hadoop-2.7.3.tar.gz
5.5 在Master上,使用Vi编辑器,设置环境变量
# vi /etc/profile
在文件最后,添加如下内容:
# Hadoop Env
export HADOOP_HOME=/usr/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5.6 退出vi编辑器,使环境变量设置立即生效
# source /etc/profile
通过scp命令,将/etc/profile拷贝到两个Slave节点:
#scp /etc/profile root@DEV-SH-MAP-02:/etc
#scp /etc/profile root@DEV-SH-MAP-03:/etc
分别在两个Salve节点上执行# source /etc/profile使其立即生效
5.7 查看Hadoop版本信息
# hadoop version
Hadoop 2.7.
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on --18T01:41Z
Compiled with protoc 2.5.
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /usr/hadoop-2.7./share/hadoop/common/hadoop-common-2.7..jar
六、Hadoop配置
以下操作均在Master节点,配置完后,使用scp命令,将配置文件拷贝到两个Slave节点即可。
切换到/usr/hadoop-2.7.3/etc/hadoop/目录下,修改如下文件:
6.1 hadoop-env.sh
在文件最后,增加如下配置:
export JAVA_HOME=/usr/jdk1..0_121
export HADOOP_PREFIX=/usr/hadoop-2.7.
6.2 yarn-env.sh
在文件最后,增加如下配置:
export JAVA_HOME=/usr/jdk1..0_121
6.3 core-site.xml
创建tmp目录:#mkdir /usr/hadoop-2.7.3/tmp
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://DEV-SH-MAP-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/hadoop/tmp</value>
</property>
</configuration>
6.4 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/mnt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/mnt/hadoop/dfs/data</value>
</property>
</configuration>
6.5 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>DEV-SH-MAP-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>DEV-SH-MAP-01:19888</value>
</property>
</configuration>
6.6 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>DEV-SH-MAP-01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>DEV-SH-MAP-01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>DEV-SH-MAP-01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>DEV-SH-MAP-01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>DEV-SH-MAP-01:8088</value>
</property>
</configuration>
6.7 slaves
DEV-SH-MAP-
DEV-SH-MAP-
DEV-SH-MAP-
6.8 拷贝配置文件到两个Slave节点
在Master节点,执行如下命令:
# scp -r /usr/hadoop-2.7.3/etc/hadoop/ root@DEV-SH-MAP-02:/usr/hadoop-2.7.3/etc/
# scp -r /usr/hadoop-2.7.3/etc/hadoop/ root@DEV-SH-MAP-03:/usr/hadoop-2.7.3/etc/
七、Hadoop使用
7.1 格式化NameNode
Master节点上,执行如下命令
#hdfs namenode -format
7.2 启动HDFS(NameNode、DataNode)
Master节点上,执行如下命令
#start-dfs.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
SecondaryNameNode
NameNode
DataNode
Jps
在两个Slave上,看到如下进程:
DataNode
Jps
7.3 启动 Yarn(ResourceManager 、NodeManager)
Master节点上,执行如下命令
#start-yarn.sh
使用jps命令,分别在Master以及两个Slave上查看Java进程
可以在Master上看到如下进程:
34225 SecondaryNameNode
33922 NameNode
34632 NodeManager
34523 ResourceManager
34028 DataNode
49534 Jps
在两个Slave上,看到如下进程:
34632 NodeManager
34028 DataNode
49534 Jps
7.4 通过浏览器查看HDFS信息
浏览器中,输入http://10.10.0.1:50070
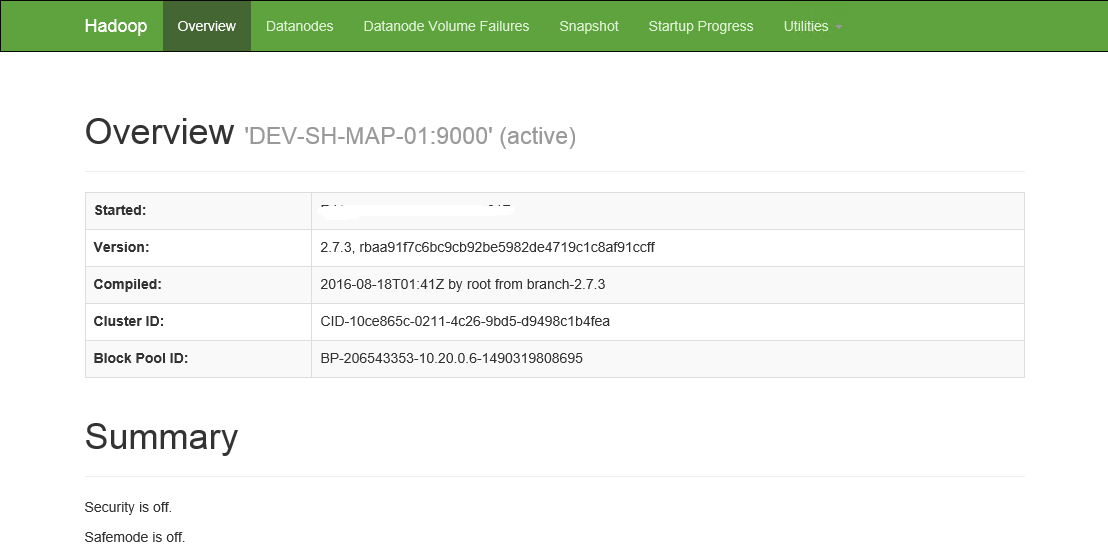
7.5 通过浏览器查看Yarn信息
浏览器中,输入http://10.10.0.1:8088
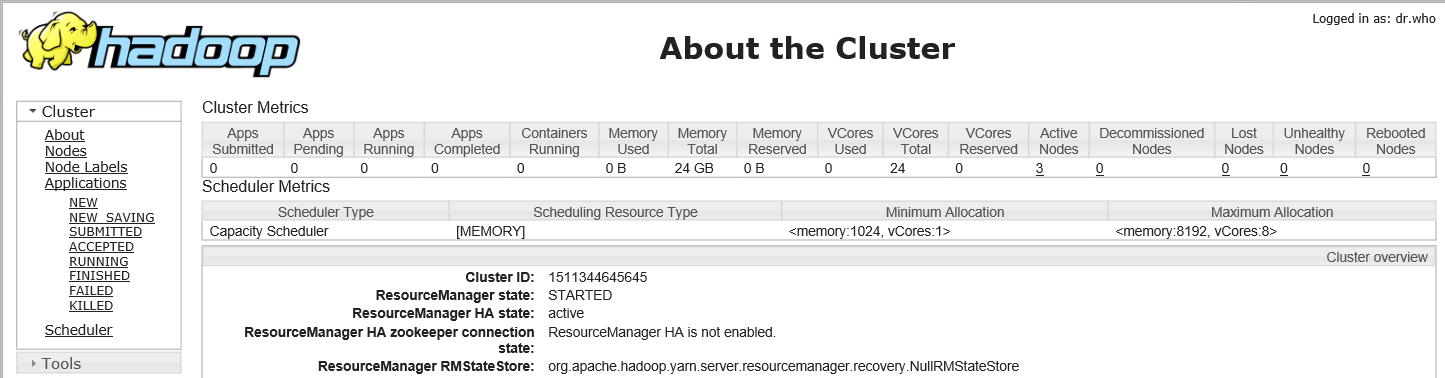
7.6 停止Yarn及HDFS
#stop-yarn.sh
#stop-dfs.sh
Hadoop2.7.3分布式集群安装的更多相关文章
- hadoop2.7.7 分布式集群安装与配置
环境准备 服务器四台: 系统信息 角色 hostname IP地址 Centos7.4 Mster hadoop-master-001 10.0.15.100 Centos7.4 Slave hado ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- (转)ZooKeeper伪分布式集群安装及使用
转自:http://blog.fens.me/hadoop-zookeeper-intro/ 前言 ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品.在单机中,系统协作大都是进程级的 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- 一张图讲解最少机器搭建FastDFS高可用分布式集群安装说明
很幸运参与零售云快消平台的公有云搭建及孵化项目.零售云快消平台源于零售云家电3C平台私有项目,是与公司业务强耦合的.为了适用于全场景全品类平台,集团要求项目平台化,我们抢先并承担了此任务.并由我来主 ...
- ZooKeeper伪分布式集群安装及使用
ZooKeeper伪分布式集群安装及使用 让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务. 现在硬件越来越 ...
- Hadoop2.8分布式集群安装与测试
1.hadoop2.x 概述 个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正常工作的,standby状态的N ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- kafka2.9.2的伪分布式集群安装和demo(java api)测试
目录: 一.什么是kafka? 二.kafka的官方网站在哪里? 三.在哪里下载?需要哪些组件的支持? 四.如何安装? 五.FAQ 六.扩展阅读 一.什么是kafka? kafka是LinkedI ...
随机推荐
- Swift 2.2 多态和强制转换
写在前面: 写点东西,就是想告诉自己,有时间其实你也在前进着,快慢不说,至少没停下吧!该有的都会有的.不瞎BB了,说主题,3.0 的多态和继承. 总觉得继承好像也没什么太多的可说的了,在项目中用到的还 ...
- 关于JavaScript中的编码和解码函数
js对文字进行编码涉及3个函数:escape,encodeURI,encodeURIComponent,相应3个解码函数:unescape,decodeURI,decodeURIComponent 1 ...
- 一个RESTful+MySQL程序
前言 本章内容适合初学者(本人也是初学者). 上一章内容(http://www.cnblogs.com/vanezkw/p/6414392.html)是在浏览器中显示Hello World,今天我们要 ...
- 转载 JDK + Android-SDK + Python + MonkeyRunner 的安装
转载来自: 小海豚的博客 http://blog.sina.com.cn/u/1295334083 我只是搬运工... JDK + Android-SDK + Python + MonkeyRun ...
- KMP算法的正确性证明及一个小优化
直接把作业帖上来是不是有点不太公道呀... 无所谓啦反正各位看着开心就行 KMP算法 对于模式串$P$,建立其前缀函数$ N$ ,其中$N [q] $ 表示在$P$中,以$q$位置为结束的可以匹配到前 ...
- VSCode从非根目录编译golang程序
1.问题提出 "习惯在项目目录里建src放源码文件,根目录里放配置文件或者别的什么,在交付时直接忽视掉src目录就行了,但vscode好像不能这样愉快的玩耍..."??? 要实现把 ...
- 分布式配置管理--百度disconf搭建过程和详细使用
先说官方文档:http://disconf.readthedocs.io/zh_CN/latest/index.html 不管是否要根据官方文档来搭建disconf,都应该看一下这一份文档.精炼清晰地 ...
- nginx.conf完整配置实例
#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; ...
- 1.5编程基础之循环控制44:第n小的质数
#include<iostream>#include<cmath>using namespace std;int main(){ int n; cin>>n; in ...
- C语言中NULL的定义
用C语言编程不能不说指针,说道指针又不能不提NULL,那么NULL究竟是个什么东西呢? C语言中又定义,定义如下: #undef NULL #if defined(__cplusplus) #defi ...