ElasticSearch文档操作介绍三
ElasticSearch文档的操作
文档存储位置的计算公式:
shard = hash(routing) % number_of_primary_shards
上面公式中,routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing 的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。
ElasticSearch中,新建、删除、索引文档都属于写操作,必须在主分片上面完成之后才能被复制到相关的副本分片。
写一个文档:
下图是官网的一个例子,假设集群中有三个节点,一个索引,两个主分片,每个主分片有两个副本。写操作一个文档的过程如下:
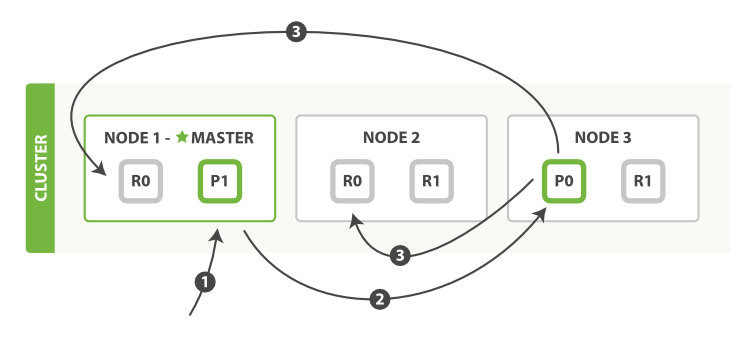
1、客户端向 Node 1 发送新建、索引或者删除请求。
2、节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3`,因为分片 0 的主分片目前被分配在 `Node 3 上。
3、Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点(接受客户端请求的节点)报告成功,协调节点向客户端报告成功。
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。
读一个文档:
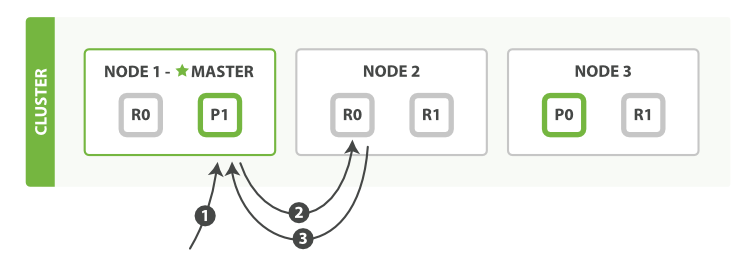
检索(读取)一个文档时,可以从主分片或者其他任意副本分区检索。
以下是从主分片或者副本分片检索文档的步骤顺序:
1、客户端向 Node 1 发送获取请求。
2、节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的主、副分片存在于所有节点上。 在这种情况下,它将请求转发到 Node 2 。
3、Node 2 将文档返回给 Node 1 ,然后将文档返回给客户端。
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。
在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
部分更新一个文档:
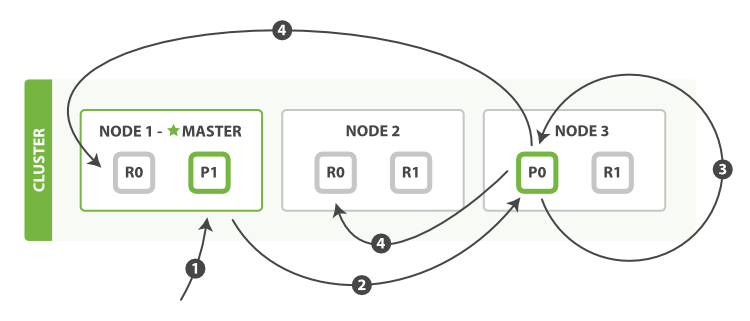
以下是部分更新一个文档的步骤:
1、客户端向 Node 1 发送更新请求。
2、它将请求转发到主分片所在的 Node 3 。
3、Node 3 从主分片检索文档,修改 _source 字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过 retry_on_conflict 次后放弃。
4、如果 Node 3 成功地更新文档,它将新版本的文档并行转发到 Node 1 和 Node 2 上的副本分片,重新建立索引。 一旦所有副本分片都返回成功, Node 3 向协调节点也返回成功,协调节点向客户端返回成功。
ElasticSearch文档操作介绍三的更多相关文章
- elasticsearch 文档阅读笔记(三)
文档 elasticsearch是通过document的形式存储数据的,个人理解文档就是一条数据一个对象 我们添加索引文档中不仅包含了数据还包含了元数据 比如我们为一个数据添加索引 文档中不仅有jso ...
- ElasticSearch文档-简单介绍
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进行数据索引 ...
- 一款开源免费的.NET文档操作组件DocX(.NET组件介绍之一)
在目前的软件项目中,都会较多的使用到对文档的操作,用于记录和统计相关业务信息.由于系统自身提供了对文档的相关操作,所以在一定程度上极大的简化了软件使用者的工作量. 在.NET项目中如果用户提出了相关文 ...
- ElasticSearch 基本概念 and 索引操作 and 文档操作 and 批量操作 and 结构化查询 and 过滤查询
基本概念 索引: 类似于MySQL的表.索引的结构为全文搜索作准备,不存储原始的数据. 索引可以做分布式.每一个索引有一个或者多个分片 shard.每一个分片可以有多个副本 replica. 文档: ...
- elasticsearch文档-modules
elasticsearch文档-modules modules 模块 cluster 原文 基本概念 cluster: 集群,一个集群通常由很多节点(node)组成 node: 节点,比如集群中的每台 ...
- Elasticsearch文档查询
简单数据集 到目前为止,已经了解了基本知识,现在我们尝试用更逼真的数据集,这儿已经准备好了一份虚构的JSON,关于客户银行账户信息的.每个文档的结构如下: { , , "firstname& ...
- 008-elasticsearch5.4.3【二】ES使用、ES客户端、索引操作【增加、删除】、文档操作【crud】
一.ES使用,以及客户端 1.pom引用 <dependency> <groupId>org.elasticsearch.client</groupId> < ...
- ES入门三部曲:索引操作,映射操作,文档操作
ES入门三部曲:索引操作,映射操作,文档操作 一.索引操作 1.创建索引库 #语法 PUT /索引名称 { "settings": { "属性名": " ...
- elasticsearch 文档
elasticsearch 文档 文档格式 索引中最基本的单元叫做文档 document. 在es中文档的示例如下: { "_index": "questions&quo ...
随机推荐
- JAVA面对对象(五)——接口
接口由全局常量和公共的抽象方法组成,接口的定义格式: interface 接口名称{ 全局常量; 抽象方法; } 接口中的抽象方法必须定义为public访问权限,在接口中如果不写也默认是public访 ...
- FICO模块
- 第八周PSP 新折线图和饼图 个人时间管理
1.PSP DATE START-TIME END-TIME EVENT DELTA TYPE 4.18 15.36 16.10 读构建执法 走神5min 29mi ...
- PHP IF ELSE简化/三元一次式的使用
一般我们会这样写: <? if($_GET['time']==null) { $time = time(); } else { $time = $_GET['time']; } echo $ti ...
- 一本通1609【例 4】Cats Transport
1609:[例 4]Cats Transport 时间限制: 1000 ms 内存限制: 524288 KB sol:非常偷懒的截图了事 注意:只能猫等人,不能人等猫 对于每只猫,我们 ...
- 普通javabean 获得项目的绝对路径
方式一:String path = RequestContext.class.getResource("/").getFile();
- python面对对象编程中会用到的装饰器
1.property 用途:用来将对像的某个方法伪装成属性来提高代码的统一性. class Goods: #商品类 discount = 0.8 #商品折扣 def __init__(self,nam ...
- Luogu3676 小清新数据结构题(树链剖分+线段树)
先不考虑换根.考虑修改某个点权值对答案的影响.显然这只会改变其祖先的子树权值和,设某祖先原子树权值和为s,修改后权值增加了x,则对答案的影响为(s+x)2-s2=2sx+x2.可以发现只要维护每个点到 ...
- day25 上山练习 计算圆练习
# 练习一:在终端输出如下信息 # 小明,10岁,男,上山去砍柴 # 小明,10岁,男,开车去东北 # 小明,10岁,男,最爱大保健 # 老李,90岁,男,上山去砍柴 # 老李,90岁,男,开车去东北 ...
- BZOJ 4555: [Tjoi2016&Heoi2016]求和 (NTT + 第二类斯特林数)
题意 给你一个数 \(n\) 求这样一个函数的值 : \[\displaystyle f(n)=\sum_{i=0}^{n}\sum_{j=0}^{i} \begin{Bmatrix} i \\ j ...