hadoop安装hbase
1、安装hadoop
hadoop安装请参考我的centoos 安装hadoop集群
在安装hadoop的基础上新增了两台slave机器,新增后的配置为
H30(192.168.3.238) master
H31(192.168.3.237) slave
H32(192.168.3.100) slave
H33(192.168.3.101) slave
hadoop安装完成后启动hadoop
2、安装zookeeper
2.1、下载解压
下载地址http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.6/
这里我们使用zookeeper-3.4.6,下载完成后解压到/usr/local
tar -xzf zookeeper-3.4.6.tar.gz -C /usr/local
mv zookeeper-3.4.6 zookeeper
2.2、配置
cd /usr/local
cp zookeeper/conf/zoo_sample.cfg zookeeper/conf/zoo.cfg
vim zookeeper/conf/zoo.cfg
修改
dataDir=/usr/local/zookeeper/data
添加
server.1=H30:2898:3898
server.2=H31:2898:3898
server.3=H32:2898:3898
在指定的dataDir中新建myid文件,添加内容
1
2.3、拷贝zookeeper到其他机器
此处我们只是在H30中安装配置,把配置好的zookeeper拷贝的H31和H32
scp -r zookeeper root@H31:/usr/local
scp -r zookeeper root@H32:/usr/local
在H31和H32中把myid中的内容分别修改为2和3
2.4、启动zookeeper
在H30,H31,H32中依次启动zookeeper
zookeeper/bin/zkServer.sh start
3、安装hbase
2.1、下载解压
下载地址http://mirror.bit.edu.cn/apache/hbase/1.3.1/
这里我们使用hbase-1.3.1,下载完成后解压到/usr/local
tar -xzf hbase-1.3.1-bin.tar.gz -C /usr/local
mv hbase-1.3.1-bin hbase
2.2、配置
vim hbase/conf/hbase-env.sh
添加
export HBASE_MANAGES_ZK=false
表示不使用hbase自带的zookeeper
vim hbase/conf/hbase-site.xml
在configuration标签中添加
<property>
<name>hbase.rootdir</name>
<value>hdfs://H30:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>H30,H31,H32</value>
</property>
vim hbase/conf/regionservers
添加
H31
H32
H33
2.3、启动
hbase/bin/start-hbase.sh
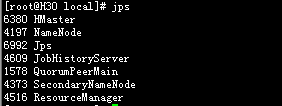
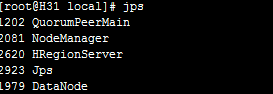
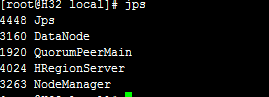
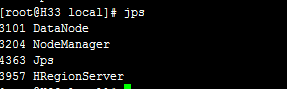
在H30中通过jps可看到
H31
H32
H33
hadoop安装hbase的更多相关文章
- hadoop +zookeeper + hbase 单节点安装
项目描述: 今天花了680元买了阿里云的一台内存1G, 带宽1M 的云主机. 想以后方便测试用,而且想把自己的博客签到自己的主机上.所以自己就搭了一个测试的环境. 可以用来进行基本的hbase 入库, ...
- 在Hadoop伪分布式模式下安装Hbase
安装环境:Hadoop 1.2.0, Java 1.7.0_21 1.下载/解压 在hbase官网上选择自己要下的hbase版本,我选择的是hbase-0.94.8. 下载后解压到/usr/local ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- 第十二章 Ganglia监控Hadoop及Hbase集群性能(安装配置)
1 Ganglia简介 Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点.每台计算机都运行一个收集和发送度量数据(如处理器速度.内存使用量等)的名为 gm ...
- 沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase 一.安装准备 首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安 ...
- Hadoop 伪分布式上安装 HBase
hbase下载:点此链接 (P.S.下载带bin的) 下载文件放入虚拟机文件夹,打开,放在自己指定的文件夹 -src.tar.gz -C /home/software/ 修改环境配置 gedit / ...
- CentOS系统下Hadoop、Hbase、Zookeeper安装配置
近期给一个项目搭建linux下的大数据处理环境,系统是CentOS 6.3.主要是配置JDK.安装Tomcat,Hadoop.HBase和Zookeeper软件.博主在Hadoop这方面也是新手.配置 ...
- hadoop+zookeeper+hbase分布式安装
前期服务器配置 修改/etc/hosts文件,添加以下信息(如果正常IP) 119.23.163.113 master 120.79.116.198 slave1 120.79.116.23 slav ...
随机推荐
- A bean with that name has already been defined in DataSourceConfiguration$Hikari.class
A bean with that name has already been defined in DataSourceConfiguration$Hikari.class 构建springcloud ...
- html语义化练习易牛课堂代码
html <body> <header> <!-- 导航 --> <nav> <a href=" ...
- Eclipse中创建一个新的SpringBoot项目
在Eclipse中创建一个新的spring Boot项目: 1. 首先在Eclipse中安装STS插件:在Eclipse主窗口中点击 Help -> Eclipse Marketplace... ...
- Flask最强攻略 - 跟DragonFire学Flask - 第一篇 你好,我叫Flask
首先,要看你学没学过Django 如果学过Django 的同学,请从头看到尾,如果没有学过Django的同学,并且不想学习Django的同学,轻饶过第一部分 一. Python 现阶段三大主流Web框 ...
- 20175314 《Java程序设计》第四周学习总结
20175314 <Java程序设计>第四周学习总结 教材学习内容总结 每个子类只能有一个父类,而一个父类可以有多个子类.可以使用关键字extends来定义一个类的子类:class 子类名 ...
- 2015-2016 ACM-ICPC Nordic Collegiate Programming Contest (NCPC 2015)
题目链接 : http://codeforces.com/gym/100781/attachments A-Adjoin the Network 题意大概是有多棵树(也可能是一颗),现在要把它们合并 ...
- vm ware虚拟机ping不通解决办法
本人是linux菜鸟,在使用vm ware的时候,在多台电脑上安装了多个虚拟机,这多台电脑是同一网段的,并且能够互相ping通,但是vm ware下的虚拟机就无法ping通 通过自己的各种才是,发现在 ...
- adc指令
adc是带进位加法指令,它利用了CF位上记录的进位值. 指令格式: adc 操作对象1,操作对象2 功能:操作对象1 = 操作对象1 + 操作对象2 + CF 例如指令 adc ax,bx实现的功能 ...
- PHP并发之Swoole
<?php /** * Created by PhpStorm. * User: zhezhao * Date: 2016/10/20 * Time: 10:51 */ $url_arr = a ...
- React-router4 第五篇 Preventing Transitions 防止转换
文档地址:https://reacttraining.com/react-router/web/example/preventing-transitions 大概意思就是说:我在这个页面上写东西呢?不 ...