【强化学习】python 实现 q-learning 例三(例一改写)
本文作者:hhh5460
本文地址:https://www.cnblogs.com/hhh5460/p/10139738.html
例一的代码是函数式编写的,这里用面向对象的方式重新撸了一遍。好处是,更便于理解环境(Env)、个体(Agent)之间的关系。
有缘看到的朋友,自己慢慢体会吧。
0.效果图
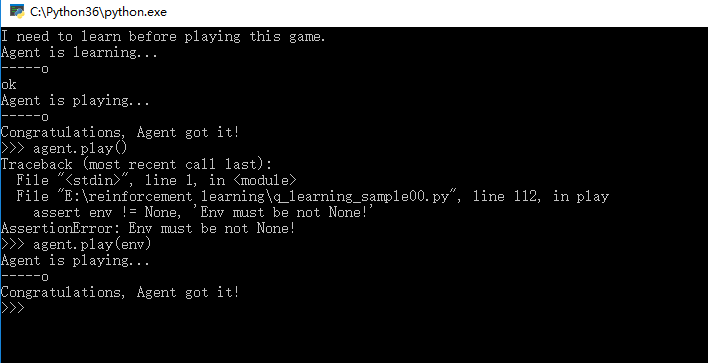
1.完整代码
import pandas as pd
import random
import time
import pickle
import pathlib '''
-o---T
# T 就是宝藏的位置, o 是探索者的位置 作者:hhh5460
时间:20181218
地点:Tai Zi Miao
''' class Env(object):
'''环境类'''
def __init__(self):
'''初始化'''
self.env = list('-----T') def update(self, state, delay=0.1):
'''更新环境,并打印'''
env = self.env[:]
env[state] = 'o' # 更新环境
print('\r{}'.format(''.join(env)), end='')
time.sleep(delay) class Agent(object):
'''个体类'''
def __init__(self, alpha=0.01, gamma=0.9):
'''初始化'''
self.states = range(6)
self.actions = ['left', 'right']
self.rewards = [0,0,0,0,0,1] self.alpha = alpha
self.gamma = gamma self.q_table = pd.DataFrame(data=[[0 for _ in self.actions] for _ in self.states],
index=self.states,
columns=self.actions) def save_policy(self):
'''保存Q table'''
with open('q_table.pickle', 'wb') as f:
# Pickle the 'data' dictionary using the highest protocol available.
pickle.dump(self.q_table, f, pickle.HIGHEST_PROTOCOL) def load_policy(self):
'''导入Q table'''
with open('q_table.pickle', 'rb') as f:
self.q_table = pickle.load(f) def choose_action(self, state, epsilon=0.8):
'''选择相应的动作。根据当前状态,随机或贪婪,按照参数epsilon'''
if (random.uniform(0,1) > epsilon) or ((self.q_table.ix[state] == 0).all()): # 探索
action = random.choice(self.get_valid_actions(state))
else:
action = self.q_table.ix[state].idxmax() # 利用(贪婪)
return action def get_q_values(self, state):
'''取状态state的所有Q value'''
q_values = self.q_table.ix[state, self.get_valid_actions(state)]
return q_values def update_q_value(self, state, action, next_state_reward, next_state_q_values):
'''更新Q value,根据贝尔曼方程'''
self.q_table.ix[state, action] += self.alpha * (next_state_reward + self.gamma * next_state_q_values.max() - self.q_table.ix[state, action]) def get_valid_actions(self, state):
'''取当前状态下所有的合法动作'''
valid_actions = set(self.actions)
if state == self.states[-1]: # 最后一个状态(位置),则
valid_actions -= set(['right']) # 不能向右
if state == self.states[0]: # 最前一个状态(位置),则
valid_actions -= set(['left']) # 不能向左
return list(valid_actions) def get_next_state(self, state, action):
'''对状态执行动作后,得到下一状态'''
# l,r,n = -1,+1,0
if action == 'right' and state != self.states[-1]: # 除非最后一个状态(位置),向右就+1
next_state = state + 1
elif action == 'left' and state != self.states[0]: # 除非最前一个状态(位置),向左就-1
next_state = state -1
else:
next_state = state
return next_state def learn(self, env=None, episode=1000, epsilon=0.8):
'''q-learning算法'''
print('Agent is learning...')
for _ in range(episode):
current_state = self.states[0] if env is not None: # 若提供了环境,则更新之!
env.update(current_state) while current_state != self.states[-1]:
current_action = self.choose_action(current_state, epsilon) # 按一定概率,随机或贪婪地选择
next_state = self.get_next_state(current_state, current_action)
next_state_reward = self.rewards[next_state]
next_state_q_values = self.get_q_values(next_state)
self.update_q_value(current_state, current_action, next_state_reward, next_state_q_values)
current_state = next_state if env is not None: # 若提供了环境,则更新之!
env.update(current_state)
print('\nok') def play(self, env=None, delay=0.5):
'''玩游戏,使用策略'''
assert env != None, 'Env must be not None!' if pathlib.Path("q_table.pickle").exists():
self.load_policy()
else:
print("I need to learn before playing this game.")
self.learn(env, 13)
self.save_policy() print('Agent is playing...')
current_state = self.states[0]
env.update(current_state, delay)
while current_state != self.states[-1]:
current_action = self.choose_action(current_state, 1.) # 1., 不随机
next_state = self.get_next_state(current_state, current_action)
current_state = next_state
env.update(current_state, delay)
print('\nCongratulations, Agent got it!') if __name__ == '__main__':
env = Env() # 环境
agent = Agent() # 个体
#agent.learn(env, episode=13) # 先学
#agent.save_policy() # 保存所学
#agent.load_policy() # 导入所学
agent.play(env) # 再玩
【强化学习】python 实现 q-learning 例三(例一改写)的更多相关文章
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- 机器学习之强化学习概览(Machine Learning for Humans: Reinforcement Learning)
声明:本文翻译自Vishal Maini在Medium平台上发布的<Machine Learning for Humans>的教程的<Part 5: Reinforcement Le ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 廖雪峰网站:学习python函数—函数参数(三)
1.*args # 位置参数,计算x2的函数 def power(x): return x * x p = power(5) print(p) # 把power(x)修改为power(x, n),用来 ...
- 廖雪峰网站:学习python基础知识—判断(三)
一.判断 1.条件判断 age = 18 if age >= 18: print('your are is', age) print('adult') age = 3 if age >= ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
随机推荐
- Angular基础(五) 内建指令和表单
Angular提供了一些内建的指令,可以作为属性添加给HTML元素,以动态控制其行为. 一.内建指令 a) *ngIf,可以根据条件来显示或隐藏HTML元素. <div *ngIf='a&g ...
- 安卓界面之Toolbar+tablayout+viewpager仿WhatsApp界面样式
实现界面: 布局代码: <?xml version="1.0" encoding="utf-8"?> <android.support.con ...
- Flume Source 实例
Flume Source 实例 Avro Source 监听avro端口,接收外部avro客户端数据流.跟前面的agent的Avro Sink可以组成多层拓扑结构. 1 2 3 4 5 6 7 8 9 ...
- 动态导入模块:__import__、importlib、动态导入的使用场景
相关内容: __import__ importlib 动态导入的使用场景 首发时间:2018-02-23 16:06 __import__: 功能: 是一个函数,可以在需要的时候动态导入模块 使用: ...
- 09-OpenLDAP加密传输配置
OpenLDAP加密传输配置(CA服务器与openldap服务器异机) 阅读视图 环境准备 CA证书服务器搭建 OpenLDAP服务端与CA集成 OpenLDAP客户端配置 客户端测试验证 故障处理 ...
- python第六十八天--第十二周作业
主题: 需求: 用户角色,讲师\学员, 用户登陆后根据角色不同,能做的事情不同,分别如下讲师视图 管理班级,可创建班级,根据学员qq号把学员加入班级 可创建指定班级的上课纪录,注意一节上课纪录对应多条 ...
- systemd 和 如何修改和创建一个 systemd service (Understanding and administering systemd)
系统中经常会使用到 systemctl 去管理systemd程序,刚刚看了一篇关于 systemd 和 SysV 相关的文章,这里简要记录一下: systemd定义: (英文来解释更为原汁原味) sy ...
- Jersey常用注解解释 @DET、@PUT、@POST 、@DELETE等
uri : ... /resource/{id} public voide method(@PathParam("id") String userId){} uri : .../ ...
- CyclicBarrier源码解读
1. 简介 JUC中的CyclicBarrier提供了一种多线程间的同步机制,可以让多个线程在barrier等待其它线程到达barrier.正如其名CyclicBarrier含义就是可以循环使用的屏障 ...
- HDFS的namenode从单节点扩展为HA需要注意的问题
扩展为HA需要注意的问题 原Namenode称为namenode1,新增的Namenode称为namenode2. 从namenode单节点扩展为HA模式官网上有详细的教程,下面是扩展过程中疏忽的地方 ...