QANet
Reading Comprehension(RC)
阅读理解对于机器来说, 是一项非常艰巨的任务。google提出QANet, 目前(2018 0505)一直是SQuAD的No. 1. 今天简单地与大家分享一下。
SQuAD
Stanford Question Answering Dataset (SQuAD) [1] 阅读理解理解数据集,包含100,000+ 的数据样本,采用众包的方式,对500+的 Wikipedia 文章进行处理,得到(Context, question, answer) 三元组样本。答案是Context 中的一小段文本。
In meteorology, precipitation is any product of the condensation of atmospheric water vapor that falls under gravity. The main forms of precipitation include drizzle, rain, sleet, snow, graupel and hail... Precipitation forms as smaller droplets coalesce via collision with other rain drops or ice crystals within a cloud. Short, intense periods of rain in scattered locations are called “showers”.
# What causes precipitation to fall?
gravity
# What is another main form of precipitation besides drizzle, rain, snow, sleet and hail?
graupel
# Where do water droplets collide with ice crystals to form precipitation?
within a cloud
SQuAD Leaderboard

QANet
Contribution:
- 移除了循环(Recurrent)机制,使用巻积(convolution)与自注意(self-attention)机制处理相关任务,提升了模型的数据处理速度(trainging: 3x to 13x, inference: 4x to 9x)
- 提出了数据增强技术:NMT。
Model Structure:
- Embedding layer
- Embedding encoder layer
- Context-attention layer
- Model encoder layer
- Output layer
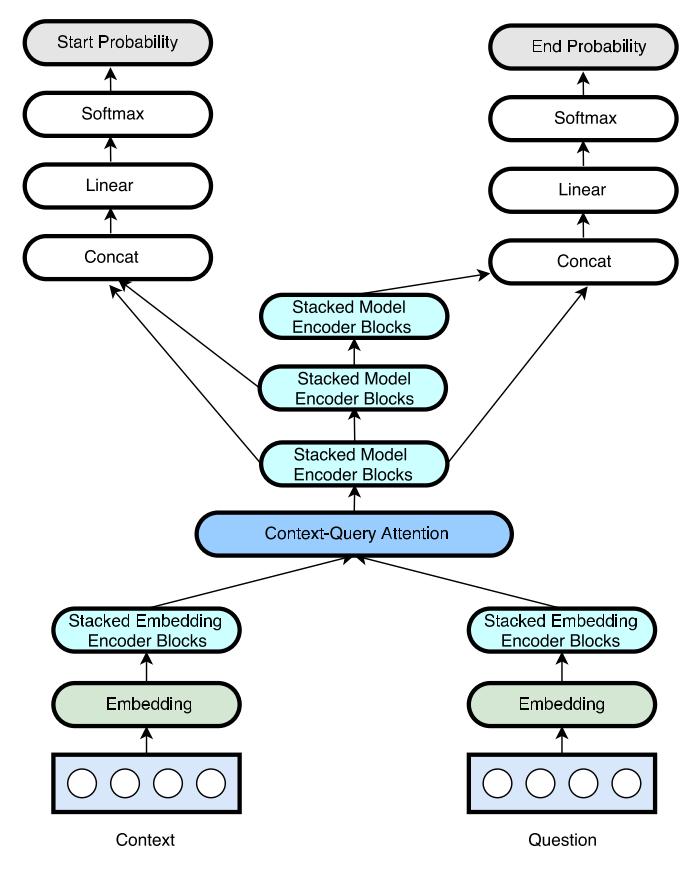
Embedding Layer:
将自然语言转化计算机可处理的向量,并尽量保留词语中所包含的语义信息。
采用词向量与字向量拼接的方式获得最终的词向量:
- Word embedding: 预训练,采用 GloVe 词向量。
- Character embedding: 可训练(trainable)。
处理过程:
- 对于字量操作:
- 将每个字符转化(truncated or padded) 成统一长的单词(16);
- 池化(max pooling)(沿 行),
char_embedding = reduce_max(char_embedding, axis= row); - 巻积操作。
- 字、词向量拼接:
\]
- Highway Nets [2]处理:
\[outputs = H(x,W_H) \cdot T(x, W_T) + x \cdot C(x,W_C)
\]其中, H() 是仿射变换(Affine Transformation), 一般可理解为处理 x 时所用的网络, T(), C() 则是构成高速路网络的非线性变换, 一般为简洁: \(C = 1 - T\):
\[outputs = H(x,W_H) \cdot T(x, W_T) + x \cdot (1 - T(x,W_T))
\]
Embedding Encoder layer:
提取Context 与 question中的主义信息。
采用巻积与自注意机制:构建了一个 encoder block:
[(pos-encoding)+conv x # + self-attention + feed-forward]
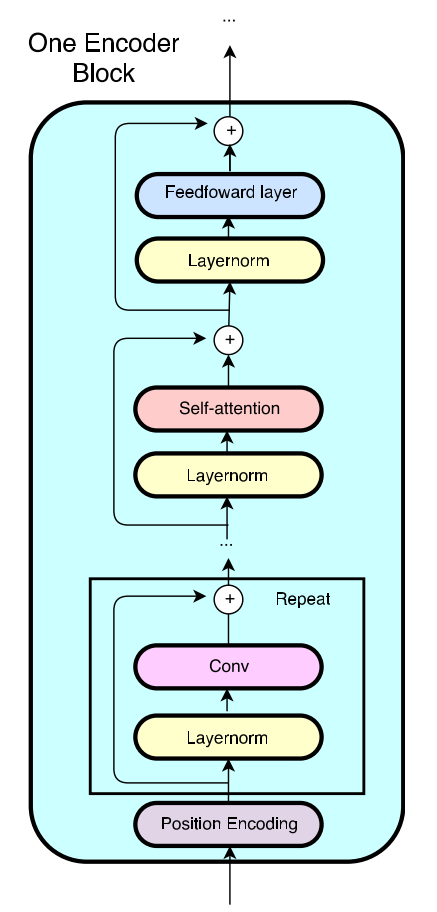
Position encoding[3]:
捕捉位置信息
\[PE_{(pos,2i)} = \sin(pos / 10000^{2i/d_{model}})\\
PE_{(pos,2i+1)} = \cos(pos / 10000^{2i/d_{model}})
\]
其中, pos表示词的位置,i表示的\(i^{th}\) 的embedding维度。\(d_{model}\) 表示embedding的维度.
posting encoding 结果与输入相加,作为下一步的输入。
深度(可分离)巻积(Depth wise separable convolutions)[4]:
在经典巻积中,巻积核在所有输入通道上进行巻积操作, 并综合所有输入通道情况得到巻积结果(如加和,池化等等),而在深度可分离巻积中,巻积操作分为两步,第一步,巻积核对每个输入通道进行单独地处理, 不做综合处理;每二步,对第一步的结果,使用(WxH=1x1)的巻积核进行处理,并得到最终结果。这样可以提高泛化能力与巻积效率,避免参数冗余。
与经典巻积的对比:

[经典巻积]
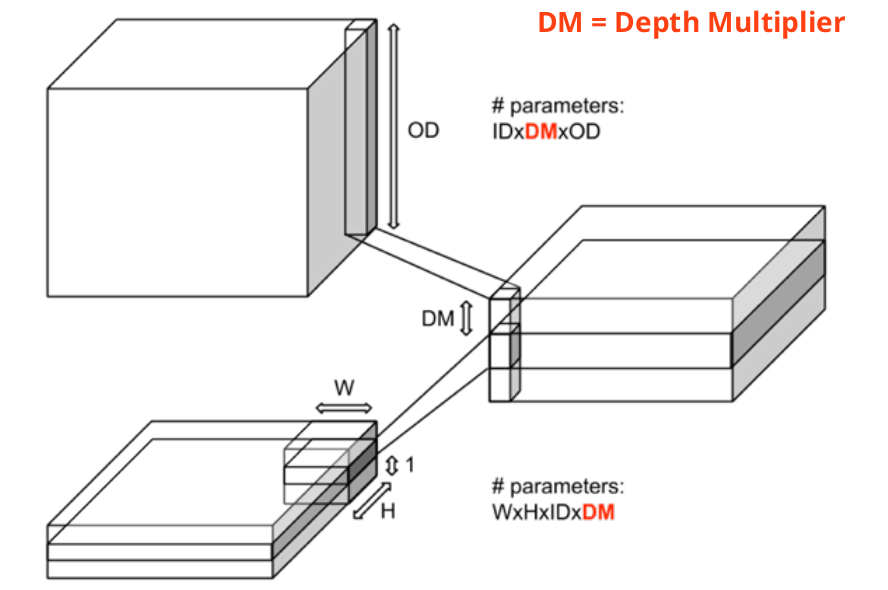
[深度可分离巻积]
自注意力机制[3]:
一种序列表示(sequence representation), 提取全局信息。
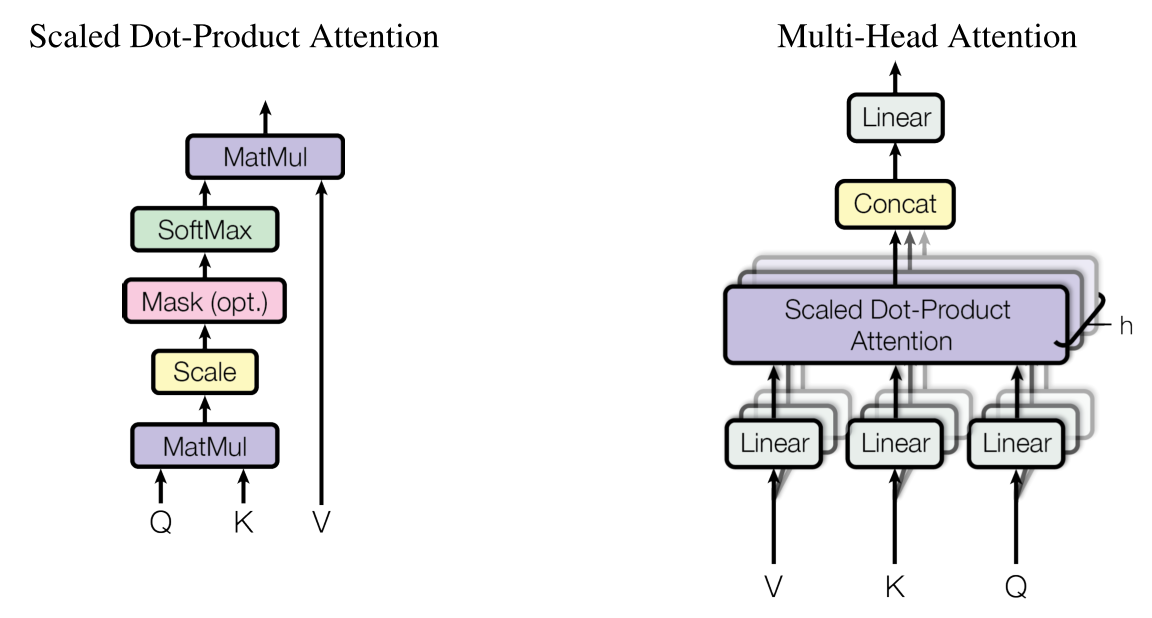
\]
其中Q:query, K: key, V:value.
其中,\ head_i = Attention(QW_i^Q,KW_i^K,VW_i^V)
\]
- 在 encoder block中, 将每个子层都包裹在列差模块中:
\[Output = f(layernorm(x)) + x
\]其中 f 表示encoder block 中的子层,如 depth conv, self-attention, feed-forward等。layernorm() 表示 layer normalization[5].
Context-Query Attention Layer
发现context query 之间的联系,并在词的层面上,解析出query, context中关键的词语。
从词的层面上,挖掘context, query 之间的关系S (n x m) [6]:
\[S_{i,j} = f(q,c ) = W_0[q,c,q\odot c]
\]其中,\(\odot\) 表示逐元素(element-wise)相乘, n 表示 context 的长度, m表示query的长度。
Context-to-query attention A:
\[A = softmax(S, axis=row) \cdot Q^T \quad \in R^{n\times d}
\]其中,d 为embedding长度
query-to-context attention B:
\[B = A\cdot softmax(S,axis=column)^T \cdot C^T
\]
Model Encoder layer
从全局的层面来考虑context与query之间的关系。
采用 stacked blocks x 3(权值共享), stack blocks = encoder block x 7. 输入: \([c,a,c\odot a, c\odot b]\), 三个stacked blocks 分别输出\(M_0, M_1,M_2\).
Output layer
解析answer在context中的位置(start position, end position):
\]
Loss function
\]
其中\(y_{i}^{start},y_i^{end}\) 分别表示真实的answer 在context中的真实起始,终止位置。
Other experiment detail
Optimization & Regularization:
- L2 weight decay (\(\lambda = 3 \times 10^{{-7}}\))
- stochastic depth[8] (layer dropout)(在每个encoder中) (survival rate of layer l \(p_l = 1 - \frac{1}{L}(1-p_L)\), L 表示最后一层, \(p_L = 0.9\),)
- layer normalization
- dropout (绝大部分0.1, 在character embedding为0.05)
- ADAM[7] (\(\beta_1 = 0.8, beta_2 = 0.999, \epsilon = 10^{-7}\))
- depth-wise separable convolutions
- self-attention, multi-head, position encoding(compared with rnn)
- position encoding
- exponentially moving average(EMA: 0.9999)
PS: 代码过几天附上。
Reference
Pranav Rajpurkar, Jian Zhang,Konstantin Lopyrev, and Percy Liang. Squad: 100, 000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, November 1-4, 2016, pp. 2383–2392, 2016
Rupesh Kumar Srivastava, Klaus Greff, and J¨ urgen Schmidhuber. Highway networks. CoRR, abs/1505.00387, 2015. URL http://arxiv.org/abs/1505.00387
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin, Attention is all you need, In Neural Information Processing Systems, 2017b
François Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint arXiv:1610.02357, 2016
Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer Normalization. https://doi.org/10.1038/nature14236
Min Joon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hannaneh Hajishirzi. Bidirectional attention flow for machine comprehension. CoRR, abs/1611.01603, 2016. URL http://arxiv.org/ abs/1611.01603
Kingma, D. P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization, 1–15. https://doi.org/http://doi.acm.org.ezproxy.lib.ucf.edu/10.1145/1830483.1830503
Kingma, D. P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization, 1–15. https://doi.org/http://doi.acm.org.ezproxy.lib.ucf.edu/10.1145/1830483.1830503
QANet的更多相关文章
- QAnet Encoder
#!/usr/bin/python3# -*- coding: utf-8 -*-'''date: 2019/8/19mail: cally.maxiong@gmail.comblog: http:/ ...
- 用卷积神经网络和自注意力机制实现QANet(问答网络)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/ ,学习更多的机器学习.深度学习的知识! 在这篇文章中,我们将解决自然语言处理(具体是指问答)中最具挑战性 ...
- SQUAD的rnet复现踩坑记
在港科大rnet(https://github.com/HKUST-KnowComp/R-Net) 实现的基础上做了复现 采用melt框架训练,原因是港科大实现在工程上不是很完美,包括固定了batch ...
- 机器阅读理解(看各类QA模型与花式Attention)
目录 简介 经典模型概述 Model 1: Attentive Reader and Impatient Reader Model 2: Attentive Sum Reader Model 3: S ...
- 机器阅读理解(看各类QA模型与花式Attention)(转载)
目录 简介 经典模型概述 Model 1: Attentive Reader and Impatient Reader Attentive Reader Impatient Reader Model ...
- 干货 | NLP算法岗大厂面试经验与路线图分享
最近有好多小伙伴要面经(还有个要买简历的是什么鬼),然鹅真的没有整理面经呀,真的木有时间(。 ́︿ ̀。).不过话说回来,面经有多大用呢?最起码对于NLP岗位的面试来说,作者发现根本不是面经中说的样子 ...
- QG-2019-AAAI-Improving Neural Question Generation using Answer Separation
Improving Neural Question Generation using Answer Separation 本篇是2019年发表在AAAI上的一篇文章.该文章在基础的seq2seq模型的 ...
- BERT-MRC:统一化MRC框架提升NER任务效果
原创作者 | 疯狂的Max 01 背景 命名实体识别任务分为嵌套命名实体识别(nested NER)和普通命名实体识别(flat NER),而序列标注模型只能给一个token标注一个标签,因此对于嵌套 ...
随机推荐
- Android hdpi ldpi mdpi xhdpi xxhdpi适配详解
设计稿计算: x/2.5=1080/3x=900y/2.5=1920/3y=1600 http://blog.csdn.net/lantiankongmo/article/details/505491 ...
- Linux 安装python3.7.0
我这里使用的时centos7-mini,centos系统本身默认安装有python2.x,版本x根据不同版本系统有所不同,可通过 python --V 或 python --version 查看系统自 ...
- spring datasource 使用 proxool
XmlWebApplicationContext使用的xml配置如下: <?xml version="1.0" encoding="UTF-8"?> ...
- [js]js设计模式-修改原型
参考 操作原型 - 给原型添加属性 - 方法1: Fn.prototype.sum=function{} - 方法2: Fn.prototype={} //constructor指向了Object的原 ...
- [macOS] PHP双版本,5.6跟7.1
转过来的,原文看这里,https://www.symfony.fi/page/how-to-run-both-php-5-6-and-php-7-x-with-homebrew-on-os-x-wit ...
- 使用quartz数据库锁实现定时任务的分布式部署
,1.根据项目引用的quartz依赖版本,确定下载的quartz-distribution安装包,我项目引用的信息如下图所示: 2.解压,在\quartz-2.2.3-distribution\qua ...
- 融云开发漫谈:你是否了解Go语言并发编程的第一要义?
2007年诞生的Go语言,凭借其近C的执行性能和近解析型语言的开发效率,以及近乎完美的编译速度,席卷全球.Go语言相关书籍也如雨后春笋般涌现,前不久,一本名为<Go语言并发之道>的书籍被翻 ...
- AUTEL MaxiSYS Pro MS908P Diagnostic System with WiFi Update Online
The MaxiSYS? Pro has been designed to be the go-to tool for the professional technician who performs ...
- random模块写的验证码
import randomabc=''for i in range(4): a=random.randrange(0,4) if i != a: b=chr(random.r ...
- chrome内核浏览器插件的使用--Tampermonkey(油猴插件)
Tampermonkey(油猴插件),这个插件是一个用于改造你浏览器打开的网站的插件.它可以在你打开的网页中注入任意js脚本,以达到你想要的外加功能.可以说非常不错.很多时候也值得使用. 这是个chr ...