python提效小工具-统计xmind用例数量
问题:做测试的朋友们经常会用到xmind这个工具来梳理测试点或写测试用例,但是xmind8没有自带的统计测试用例,其他版本的xmind有些自带节点数量统计功能,但也也不会累计最终的数量,导致统计测试工作量比较困难。
解决方法:利用python开发小工具,实现同一份xmind文件中一个或多个sheet页的用例数量统计功能。
一、源码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'zhongxintao'
import tkinter as tk
from tkinter import filedialog, messagebox
from xmindparser import xmind_to_dict
import xmind class ParseXmind:
def __init__(self, root):
self.count = 0
self.case_fail = 0
self.case_success = 0
self.case_block = 0
self.case_priority = 0 # total汇总用
self.total_cases = 0
self.total_success = 0
self.total_fail = 0
self.total_block = 0
self.toal_case_priority = 0 # 设置弹框标题、初始位置、默认大小
root.title(u'xmind文件解析及用例统计工具')
width = 760
height = 600
xscreen = root.winfo_screenwidth()
yscreen = root.winfo_screenheight()
xmiddle = (xscreen - width) / 2
ymiddle = (yscreen - height) / 2
root.geometry('%dx%d+%d+%d' % (width, height, xmiddle, ymiddle)) # 设置2个Frame
self.frm1 = tk.Frame(root)
self.frm2 = tk.Frame(root) # 设置弹框布局
self.frm1.grid(row=1, padx='20', pady='20')
self.frm2.grid(row=2, padx='30', pady='30') self.but_upload = tk.Button(self.frm1, text=u'上传xmind文件', command=self.upload_files, bg='#dfdfdf')
self.but_upload.grid(row=0, column=0, pady='10')
self.text = tk.Text(self.frm1, width=55, height=10, bg='#f0f0f0')
self.text.grid(row=1, column=0)
self.but2 = tk.Button(self.frm2, text=u"开始统计", command=self.new_lines, bg='#dfdfdf')
self.but2.grid(row=0, columnspan=6, pady='10')
self.label_file = tk.Label(self.frm2, text=u"文件名", relief='groove', borderwidth='2', width=25,
bg='#FFD0A2')
self.label_file.grid(row=1, column=0)
self.label_case = tk.Label(self.frm2, text=u"用例数", relief='groove', borderwidth='2', width=10,
bg='#FFD0A2').grid(row=1, column=1)
self.label_pass = tk.Label(self.frm2, text=u"成功", relief='groove', borderwidth='2', width=10,
bg='#FFD0A2').grid(row=1, column=2)
self.label_fail = tk.Label(self.frm2, text=u"失败", relief='groove', borderwidth='2', width=10,
bg='#FFD0A2').grid(row=1, column=3)
self.label_block = tk.Label(self.frm2, text=u"阻塞", relief='groove', borderwidth='2', width=10,
bg='#FFD0A2').grid(row=1, column=4)
self.label_case_priority = tk.Label(self.frm2, text="p0case", relief='groove', borderwidth='2',
width=10, bg='#FFD0A2').grid(row=1, column=5) def count_case(self, li):
"""统计xmind中的用例数"""
for i in range(len(li)):
if li[i].__contains__('topics'):
# 带topics标签表示有子标题,递归执行方法
self.count_case(li[i]['topics'])
# 不带topics表示无子标题,此级别即是用例
else:
# 有标记成功或失败时会有makers标签
if li[i].__contains__('makers'):
for mark in li[i]['makers']:
# 成功
if mark == "symbol-right":
self.case_success += 1
# 失败
elif mark == "symbol-wrong":
self.case_fail += 1
# 阻塞
elif mark == "symbol-attention":
self.case_block += 1
# 优先级
elif mark == "priority-1":
self.case_priority += 1
# 用例总数
self.count += 1 def new_line(self, filename, row_number):
"""用例统计表新增一行"""
# sheets是一个list,可包含多sheet页
sheets = xmind_to_dict(filename) # 调用此方法,将xmind转成字典
for sheet in sheets:
print(sheet)
# 字典的值sheet['topic']['topics']是一个list
my_list = sheet['topic']['topics']
print(my_list)
self.count_case(my_list) # 插入一行统计数据
lastname = filename.split('/')
self.label_file = tk.Label(self.frm2, text=lastname[-1], relief='groove', borderwidth='2', width=25)
self.label_file.grid(row=row_number, column=0) self.label_case = tk.Label(self.frm2, text=self.count, relief='groove', borderwidth='2', width=10)
self.label_case.grid(row=row_number, column=1)
self.label_pass = tk.Label(self.frm2, text=self.case_success, relief='groove', borderwidth='2',
width=10)
self.label_pass.grid(row=row_number, column=2)
self.label_fail = tk.Label(self.frm2, text=self.case_fail, relief='groove', borderwidth='2', width=10)
self.label_fail.grid(row=row_number, column=3)
self.label_block = tk.Label(self.frm2, text=self.case_block, relief='groove', borderwidth='2', width=10)
self.label_block.grid(row=row_number, column=4)
self.label_case_priority = tk.Label(self.frm2, text=self.case_priority, relief='groove', borderwidth='2',
width=10)
self.label_case_priority.grid(row=row_number, column=5)
self.total_cases += self.count
self.total_success += self.case_success
self.total_fail += self.case_fail
self.total_block += self.case_block
self.toal_case_priority += self.case_priority def new_lines(self):
"""用例统计表新增多行"""
# 从text中获取所有行
lines = self.text.get(1.0, tk.END)
row_number = 2
# 分隔成每行
for line in lines.splitlines():
if line == '':
break
print(line)
self.new_line(line, row_number)
row_number += 1 # total汇总行
self.label_file = tk.Label(self.frm2, text='total', relief='groove', borderwidth='2', width=25)
self.label_file.grid(row=row_number, column=0)
self.label_case = tk.Label(self.frm2, text=self.total_cases, relief='groove', borderwidth='2', width=10)
self.label_case.grid(row=row_number, column=1) self.label_pass = tk.Label(self.frm2, text=self.total_success, relief='groove', borderwidth='2',
width=10)
self.label_pass.grid(row=row_number, column=2)
self.label_fail = tk.Label(self.frm2, text=self.total_fail, relief='groove', borderwidth='2', width=10)
self.label_fail.grid(row=row_number, column=3)
self.label_block = tk.Label(self.frm2, text=self.total_block, relief='groove', borderwidth='2',
width=10)
self.label_block.grid(row=row_number, column=4) self.label_case_priority = tk.Label(self.frm2, text=self.toal_case_priority, relief='groove',
borderwidth='2',
width=10)
self.label_case_priority.grid(row=row_number, column=5) def upload_files(self):
"""上传多个文件,并插入text中"""
select_files = tk.filedialog.askopenfilenames(title=u"可选择1个或多个文件")
for file in select_files:
self.text.insert(tk.END, file + '\n')
self.text.update() if __name__ == '__main__':
r = tk.Tk()
ParseXmind(r)
r.mainloop()
二、工具使用说明
1、xmind文件中使用下列图标进行分类标识:
标记表示p0级别case:数字1
标记表示执行通过case:绿色√
标记表示执行失败case:红色×
标记表示执行阻塞case:橙色!
2、执行代码
3、在弹框内【上传xmind文件】按钮
三、实现效果
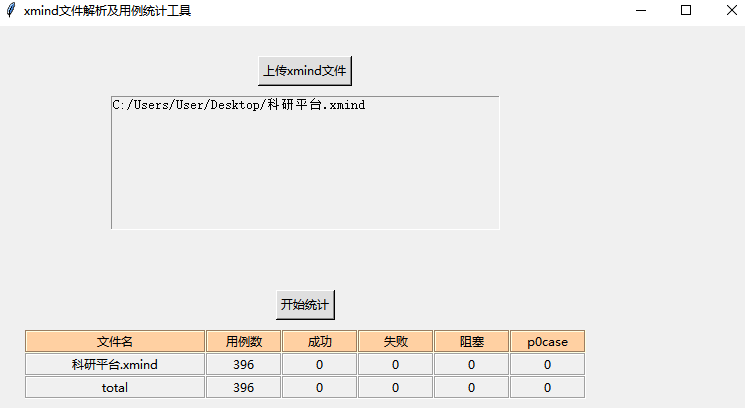
python提效小工具-统计xmind用例数量的更多相关文章
- java性能问题排查提效脚本工具
在性能测试过程中,往往会出现各种各样的性能瓶颈.其中java常见瓶颈故障模型有cpu资源瓶颈:文件IO瓶颈:网络IO瓶颈:内存资源瓶颈:资源消耗不高程序本身执行慢等场景模型. 如何快速定位分析这些类型 ...
- 前端必备,5大mock省时提效小tips,用了提前下班一小时
一.一些为难前端的业务场景 在我的工作经历里,需要等待后端童鞋配合我的情形大概有以下几种: a.我们跟外部有项目合作,需要调用到第三方接口. 一般这种情况下,商务那边谈合同,走流程,等第三方审核, ...
- Python趣味实用小工具
代码地址如下:http://www.demodashi.com/demo/12918.html python 趣味实用小工具 概述 用python实现的三个趣味实用小工具: 图片转Execl工具 , ...
- Python+Tkinter 密保小工具
上图 代码 核心 编解码方面 Tkinter界面更新 总结 昨天被一同学告知,网上的一个QQ密码库中有我的一条记录,当时我就震惊了,赶紧换了密码.当然了,这件事也给了我一个警示,那就是定期的更换自己的 ...
- 几个可以提高工作效率的Python内置小工具
在这篇文章里,我们将会介绍4个Python解释器自身提供的小工具.这些小工具在笔者的日常工作中经常用到,减少了各种时间的浪费,然而,却很容易被大家忽略.每当有新来的同事看到我这么使用时,都忍不住感叹, ...
- python tkinter模块小工具界面
代码 #-*-coding:utf-8-*- import os from tkinter import * root=Tk() root.title('小工具') #清空文本框内容 def clea ...
- 纯Python综合图像处理小工具(1)分通道直方图
平时工作经常需要做些图像分析,需要给图像分通道,计算各个通道的直方图分布特点,这个事儿photoshop也能做,但是用起来不方便,且需要电脑上安装有PS软件,如果用OpenCV, 更是需要在visua ...
- 纯Python综合图像处理小工具(4)自定义像素级处理(剪纸滤镜)
上一节介绍了python PIL库自带的10种滤镜处理,现成的库函数虽然用起来方便,但是对于图像处理的各种实际需求,还需要开发者开发自定义的滤镜算法.本文将给大家介绍如何使用PIL对图像进行自定义 ...
- 纯Python综合图像处理小工具(3)10种滤镜算法
<背景> 滤镜处理是图像处理中一种非常常见的方法.比如photoshop中的滤镜效果,除了自带的滤镜,还扩展了很多第三方的滤镜效果插件,可以对图像做丰富多样的变换:很多手机app实现了实 ...
随机推荐
- ZJOI2022选做
\(ZJOI2022\) 众数 发现并不存在\(poly(log(n))\)的做法,那么尝试\(n\sqrt n\) 套路的按照出现次数分组,分为大于\(\sqrt n\)和小于\(\sqrt n\) ...
- Apache DolphinScheduler 2.X保姆级源码解析,中国移动工程师揭秘服务调度启动全流程
2022年1月,科学技术部高新技术司副司长梅建平在"第六届中国新金融高峰论坛"上表示,当前数据量已经大大超过了处理能力的上限,若信息技术仍然是渐进式发展,则数据处理能力的提升将远远 ...
- pnpm 的 workspace 实现 monorepo 工程
前言 前端多个包管理的的方式一般都是采用monorepo的方式去管理,之前都是使用的lerna的workspace去管理.这段时间包管理切换到了pnpm上,它也有worksapce,可以支持monor ...
- Two---python循环语句/迭代器生成器/yield与return/自定义函数与匿名函数/参数传递
python基础02 条件控制 python条件语句是通过一条或多条语句的执行结果(Ture或者False)来执行的代码块 python中用elif代替了else if,所以if语句的关键字为:if- ...
- 若依 | 点击顶部 tag 标签不自动刷新
需求场景 之前:只要点击若依顶部的标签,页面都会自动刷新. 问题:A 页面有查询结果,切换到 B 页面查看信息,再切回 A 页面,则 A 页面的查询结果不会保留. 需求:点击标签,页面不自动刷新,或者 ...
- monodepth2学习1-原理介绍
monodepth2介绍 monodepth2是在2019年CVPR会议上提出的一种三维重建算法,monodepth2是基于monodepth进行了改进,采用的是基于自监督的神经网络,提出了一下三点优 ...
- Spring 08: AOP面向切面编程 + 手写AOP框架
核心解读 AOP:Aspect Oriented Programming,面向切面编程 核心1:将公共的,通用的,重复的代码单独开发,在需要时反织回去 核心2:面向接口编程,即设置接口类型的变量,传入 ...
- 【java】基础1-字符串、堆、栈、静态与引用类型
/*结论:1,一般变量(int,float,boolean..)使用==比较,引用类型(String,int[],对象)使用equals比较.2,一般的变量存放在栈中,new出来的对象都存放在堆中,字 ...
- Java基础——01
今日学习 2020-2-27 Java多态 多态性格式 /* 代码中体现多态性 其实就是一句话:父类指向子类对象 格式: 父类名称 对象名= new 子类名称(): 或者 接口名称 对象名 = new ...
- 服务端挂了,客户端的 TCP 连接还在吗?
作者:小林coding 计算机八股文网站:https://xiaolincoding.com 大家好,我是小林. 如果「服务端挂掉」指的是「服务端进程崩溃」,服务端的进程在发生崩溃的时候,内核会发送 ...