Python 爬虫代码应该怎么写?
对于入行已久的老程序员也并不一定精通爬虫代码,这些需要时间的沉淀还需要更多的实战案例,简单的问句你真的会写爬虫么?下面就是我日常写的一个y文件加上几个请求并且把需要的功能全部实现模块化,可以让我们爬虫更方便让更加快捷。
基础爬虫的架构以及运行流程
首先,给大家来讲讲基础爬虫的架构到底是啥样子的?我给大家画了张粗糙的图:
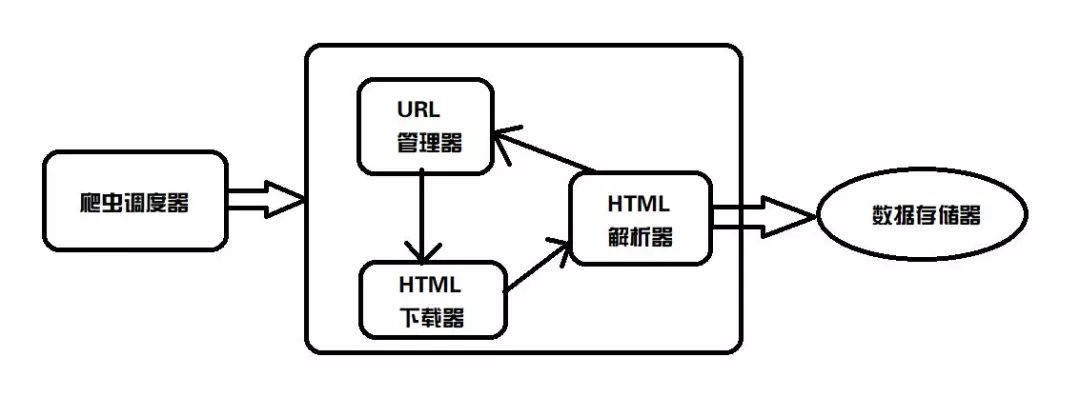
从图上可以看到,整个基础爬虫架构分为5大类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器。
下面给大家依次来介绍一下这5个大类的功能:
爬虫调度器,主要是配合调用其他四个模块,所谓调度就是取调用其他的模板。
URL管理器,就是负责管理URL链接的,URL链接分为已经爬取的和未爬取的,这就需要URL管理器来管理它们,同时它也为获取新URL链接提供接口。
HTML下载器,就是将要爬取的页面的HTML下载下来。
HTML解析器,就是将要爬取的数据从HTML源码中获取出来,同时也将新的URL链接发送给URL管理器以及将处理后的数据发送给数据存储器。
数据存储器,就是将HTML下载器发送过来的数据存储到本地。
实战爬取代码
差不多就介绍这么些东西,相信大家对整体的架构有了初步的认识,下面我简单找了个网站给大家演示一遍用爬虫架构来爬取信息:
我们来获取上面列表中的信息,这里我就省略了分析网站的一步,如果大家不会分析,可以去看我之前写的爬虫项目。
首先,我们来写一下URL管理器(URLManage.py)
class URLManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set() def has_new_url(self):
# 判断是否有未爬取的url
return self.new_url_size()!=0 def get_new_url(self):
# 获取一个未爬取的链接
new_url = self.new_urls.pop()
# 提取之后,将其添加到已爬取的链接中
self.old_urls.add(new_url)
return new_url def add_new_url(self, url):
# 将新链接添加到未爬取的集合中(单个链接)
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url) def add_new_urls(self,urls):
# 将新链接添加到未爬取的集合中(集合)
if urls is None or len(urls)==0:
return
for url in urls:
self.add_new_url(url) def new_url_size(self):
# 获取未爬取的url大小
return len(self.new_urls) def old_url_size(self):
# 获取已爬取的url大小
return len(self.old_urls)
在这里主要就是两个集合,一个是已爬取URL的集合,另一个是未爬取URL的集合。这里我使用的是set类型,因为set自带去重的功能。
接下来,HTML下载器(HTMLDownload.py)
import requests
class HTMLDownload(object):
def download(self, url):
if url is None:
return
s = requests.Session()
s.headers['User-Agent'] ='Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36'
res = s.get(url)
# 判断是否正常获取
if res.status_code == 200:
res.encoding='utf-8'
res = res.text
return res
return None
可以看到这里我们只是简单的获取了,url中的html源码。
接着看HTML解析器(HTMLParser.py)
import re
from bs4 import BeautifulSoup
class HTMLParser(object): def parser(self, page_url, html_cont):
'''
用于解析网页内容,抽取URL和数据
:param page_url: 下载页面的URL
:param html_cont: 下载的网页内容
:return: 返回URL和数据
'''
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data def _get_new_urls(self,page_url,soup):
'''
抽取新的URL集合
:param page_url:下载页面的URL
:param soup: soup数据
:return: 返回新的URL集合
'''
new_urls = set()
for link in range(1,100):
# 添加新的url
new_url = "http://www.runoob.com/w3cnote/page/"+str(link)
new_urls.add(new_url)
print(new_urls)
return new_urls def _get_new_data(self,page_url,soup):
'''
抽取有效数据
:param page_url:下载页面的url
:param soup:
:return: 返回有效数据
'''
data={}
data['url'] = page_url
title = soup.find('div', class_='post-intro').find('h2')
print(title)
data['title'] = title.get_text()
summary = soup.find('div', class_='post-intro').find('p')
data['summary'] = summary.get_text()
return data
在这里,我们将HTML下载器的源码进行了分析和解析,从而得到了我们想要拿到的数据,如果BeautifulSoup不懂的可以去看一下我之前写的文章。
继续看,数据存储器(DataOutput.py)
import codecs
class DataOutput(object): def __init__(self):
self.datas = [] def store_data(self,data):
if data is None:
return
self.datas.append(data) def output_html(self):
fout = codecs.open('baike.html', 'a', encoding='utf-8')
fout.write("<html>")
fout.write("<head><meta charset='utf-8'/></head>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>"%data['url'])
fout.write("<td>《%s》</td>" % data['title'])
fout.write("<td>[%s]</td>" % data['summary'])
fout.write("</tr>")
self.datas.remove(data)
fout.write("</table>")
fout.write("</body>")
fout.write("</html>
大家可能发现我这里是将数据存储到一个html的文件当中,在这里你当然也可以存在Mysql或者csv等文件当中,这个看自己的选择,我这里只是为了演示所以就放在了html当中。
最后一个,爬虫调度器(SpiderMan.py)
from base.DataOutput import DataOutput
from base.HTMLParser import HTMLParser
from base.HTMLDownload import HTMLDownload
from base.URLManager import URLManager class SpiderMan(object):
def __init__(self):
self.manager = URLManager()
self.downloader = HTMLDownload()
self.parser = HTMLParser()
self.output = DataOutput() def crawl(self, root_url):
# 添加入口URL
self.manager.add_new_url(root_url)
# 判断url管理器中是否有新的url,同时判断抓取多少个url
while(self.manager.has_new_url() and self.manager.old_url_size()<100):
try:
# 从URL管理器获取新的URL
new_url = self.manager.get_new_url()
print(new_url)
# HTML下载器下载网页
html = self.downloader.download(new_url)
# HTML解析器抽取网页数据
new_urls, data = self.parser.parser(new_url, html)
print(new_urls)
# 将抽取的url添加到URL管理器中
self.manager.add_new_urls(new_urls)
# 数据存储器存储文件
self.output.store_data(data)
print("已经抓取%s个链接" % self.manager.old_url_size())
except Exception as e:
print("failed")
print(e)
# 数据存储器将文件输出成指定的格式
self.output.output_html() if __name__ == '__main__':
spider_man = SpiderMan()
spider_man.crawl("http://www.runoob.com/w3cnote/page/1")
相信这里大家都能看懂,我就是将前面我们写的四个模板在这里把它们调用了一下,我们运行后的结果:

总结
我们这里简单的讲解了一下,爬虫架构的五个模板,无论是大型爬虫项目还是小型的爬虫项目都离不开这五个模板,希望大家能够照着这些代码写一遍,这样有利于大家的理解,大家以后写爬虫项目也要按照这种架构去写,这样你的爬虫看起来就会更加的规范、健全。
Python 爬虫代码应该怎么写?的更多相关文章
- python爬虫代码
原创python爬虫代码 主要用到urllib2.BeautifulSoup模块 #encoding=utf-8 import re import requests import urllib2 im ...
- Python爬虫入门教程 61-100 写个爬虫碰到反爬了,动手破坏它!
python3爬虫遇到了反爬 当你兴冲冲的打开一个网页,发现里面的资源好棒,能批量下载就好了,然后感谢写个爬虫down一下,结果,一顿操作之后,发现网站竟然有反爬措施,尴尬了. 接下来的几篇文章,我们 ...
- 动态调整线程数的python爬虫代码分享
这几天在忙一个爬虫程序,一直在改进他,从一开始的单线程,好几秒一张图片(网络不好),,,到现在每秒钟十几张图片,,, 四个小时586万条数据,,,简直不要太爽 先上图 最终写出来的程序,线程数已经可以 ...
- 我不就是吃点肉,应该没事吧——爬取一座城市里的烤肉店数据(附完整Python爬虫代码)
写在前面的一点屁话: 对于肉食主义者,吃肉简直幸福感爆棚!特别是烤肉,看着一块块肉慢慢变熟,听着烤盘上"滋滋"的声响,这种期待感是任何其他食物都无法带来的.如果说甜点是" ...
- python爬虫学习(11) —— 也写个AC自动机
0. 写在前面 本文记录了一个AC自动机的诞生! 之前看过有人用C++写过AC自动机,也有用C#写的,还有一个用nodejs写的.. C# 逆袭--自制日刷千题的AC自动机攻克HDU OJ HDU 自 ...
- 爬取汽车之家新闻图片的python爬虫代码
import requestsfrom bs4 import BeautifulSouprespone=requests.get('https://www.autohome.com.cn/news/' ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- 如何用Python爬虫实现百度图片自动下载?
Github:https://github.com/nnngu/LearningNotes 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求 分析网页源代码,配合开发者工具 编写正则表达式或 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
随机推荐
- 在回显时遇到的问题,回显的值无法显示到页面 vue
//理解为 重新渲染 this.form的数据 1 this.form = Object.assign({}, this.form)
- WebSocket服务
package com.sxsoft.admin.Component; import com.alibaba.fastjson.JSON; import io.netty.handler.codec. ...
- 《Vue.js 3.x高效前端开发(视频教学版)》简介
#好书推荐##好书奇遇季#<Vue.js 3.x高效前端开发(视频教学版)>,京东当当天猫都有发售.本书配套示例源码.PPT课件.思维导图.数据集.开发环境与答疑服务. 本书通过对Vue. ...
- 5-6:实现多窗口之异常(AttributeError: 'list' object has no attribute 'click')
代码: #coding = utf-8 from selenium import webdriver import time ##############5-6:实现多窗口切换_start###### ...
- C++future promise
A future is an object that can retrieve a value from some provider object or function, properly sync ...
- viewpager加fragment可滑动加radio跟随滑动
public class MainActivity extends AppCompatActivity implements RadioGroup.OnCheckedChangeListener, V ...
- Xpath 常用语法展示
非标准代码处理 from lxml import etree #导入lxml 中erree模块 parser = etree.HTMLParser(encoding="utf-8" ...
- 7.项目结构的构建和提交到gitee
创建微服务模块 以商城项目的产品模块为例 点击Next,然后倒入依赖的包,Spring Web 然后在选择一个微服务和微服务之间调用需要的包:OpenFeign 导入这两个微服务的组件就行,后面需要用 ...
- linux 中sed命令如何删除第一列和最后一列
删除第一列 (base) root@PC1:/home/test# cat test.txt1 MIR1302-10 12 FAM138A 23 OR4F5 34 RP11-34P13.7 45 RP ...
- Jenkins+Appium+Pytest+Allure集成
前提: 已经部署好了Jenkins环境,包括工具配置等 我的环境: Jenkins服务由安装在虚拟机上的Docker启动 Appium相关运行环境安装在虚拟机所在的主机上windows 方式:在Jen ...