《手把手教你》系列基础篇(八十八)-java+ selenium自动化测试-框架设计基础-Log4j 2实现日志输出-下篇(详解教程)
1.简介
上一篇宏哥讲解和分享了如何在控制台输出日志,但是你还需要复制粘贴才能发给相关人员,而且由于界面大小限制,你只能获取当前的日志,因此最好还是将日志适时地记录在文件中直接打包发给相关人员即可。因此这一篇宏哥主要讲解和分享如何通过log4j2将日志输出到文件中。
2.配置文件
先简单介绍一下下面这个配置文件。
1)根节点configuration,然后有两个子节点:appenders和loggers(都是复数,意思就是可以定义很多个appender和logger了)(如果想详细的看一下这个xml的结构,可以去jar包下面去找xsd文件和dtd文件)
2)appenders:这个下面定义的是各个appender,就是输出了,有好多类别,这里也不多说(容易造成理解和解释上的压力,一开始也未必能听懂,等于白讲),先看这个例子,只有一个Console,这些节点可不是随便命名的,Console就是输出控制台的意思。然后就针对这个输出设置一些属性,这里设置了PatternLayout就是输出格式了,基本上是前面时间,线程,级别,logger名称,log信息等,差不多,可以自己去查他们的语法规则。
3)loggers下面会定义许多个logger,这些logger通过name进行区分,来对不同的logger配置不同的输出,方法是通过引用上面定义的logger,注意,appender-ref引用的值是上面每个appender的name,而不是节点名称。
这个例子为了说明什么呢?宏哥要说说这个logger的name(名称)了(上一篇文章 开头部分有提到)。
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="OFF">
<appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</appenders>
<loggers>
<!--我们只让这个logger输出trace信息,其他的都是error级别-->
<!--
additivity开启的话,由于这个logger也是满足root的,所以会被打印两遍。
不过root logger 的level是error,为什么Bar 里面的trace信息也被打印两遍呢
-->
<logger name="testSuites.Test" level="trace" additivity="false">
<appender-ref ref="Console"/>
</logger>
<root level="error">
<appender-ref ref="Console"/>
</root>
</loggers>
</configuration>
3.name的机制
想要详细了解的同学们或者小伙伴们可以参考: http://logging.apache.org/log4j/2.x/manual/architecture.html)
我们这里看到了配置文件里面是name很重要,没错,这个name可不能随便起(其实可以随便起)。这个机制意思很简单。就是类似于java package一样,比如我们的一个包:cn.lsw.base.log4j2。而且,可以发现我们前面生成Logger对象的时候,命名都是通过 Hello.class.getName(); 这样的方法,为什么要这样呢? 很简单,因为有所谓的Logger 继承的问题。比如 如果你给cn.lsw.base定义了一个logger,那么他也适用于cn.lsw.base.lgo4j2这个logger。名称的继承是通过点(.)分隔的。然后你可以猜测上面loggers里面有一个子节点不是logger而是root,而且这个root没有name属性。这个root相当于根节点。你所有的logger都适用与这个logger,所以,即使你在很多类里面通过 类名.class.getName() 得到很多的logger,而且没有在配置文件的loggers下面做配置,他们也都能够输出,因为他们都继承了root的log配置。
我们上面的这个配置文件里面还定义了一个logger,他的名称是 testSuites.Test ,这个名称其实就是通过前面的Hello.class.getName(); 得到的,我们为了给他单独做配置,这里就生成对于这个类的logger,上面的配置基本的意思是只有testSuites.Test 这个logger输出trace信息,也就是他的日志级别是trace,其他的logger则继承root的日志配置,日志级别是error,只能打印出ERROR及以上级别的日志。如果这里logger 的name属性改成cn.lsw.base,则这个包下面的所有logger都会继承这个log配置(这里的包是log4j的logger name的“包”的含义,不是java的包,你非要给Hello生成一个名称为“myhello”的logger,他也就没法继承cn.lsw.base这个配置了。
那有人就要问了,他不是也应该继承了root的配置了么,那么会不会输出两遍呢?我们在配置文件中给了解释,如果你设置了additivity="false",就不会输出两遍,否则,看下面的输出:
1.这里要在加入一个类做对比,如下图所示:
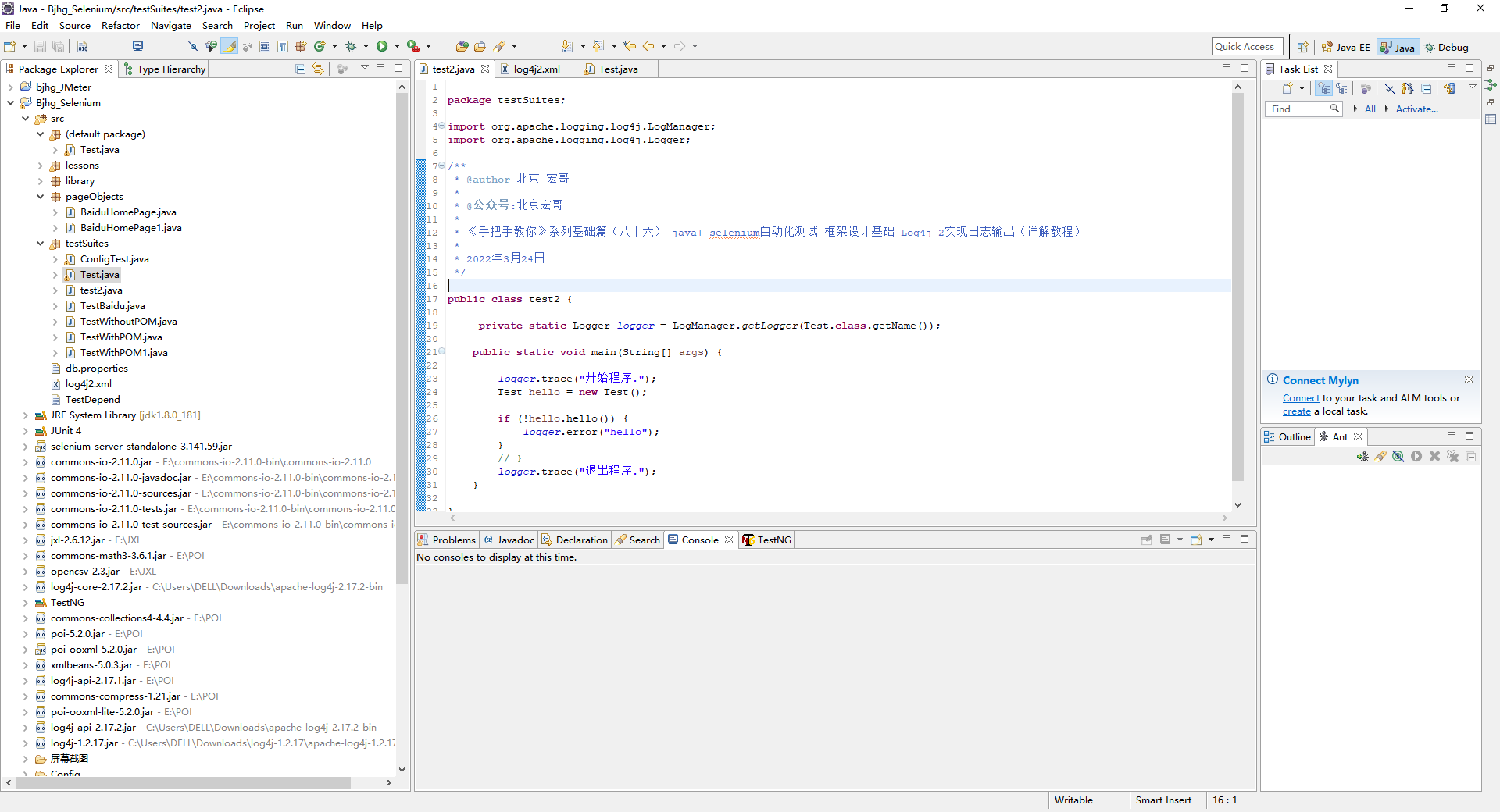
2.这里先把配置文件改一下方便对照,一个是刚才第一个logger的名称还是testSuites.Test,additivity去掉或改为true(因为默认是true,所以可以去掉),第二是把root的level改为info方便观察。 然后运行Test,看控制台的日志输出:
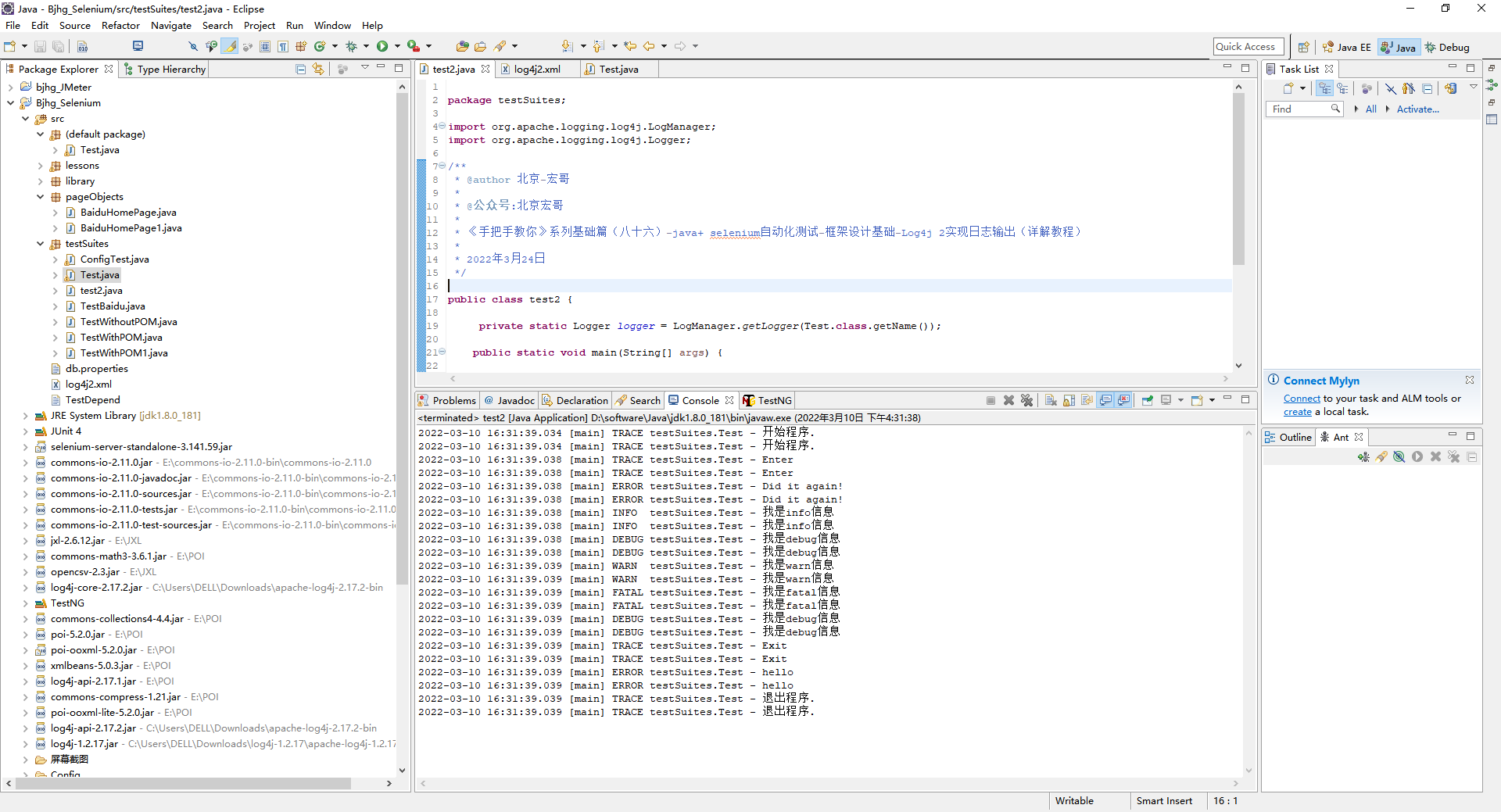
可以看出,Test的trace日志没有输出,因为他继承了root的日志配置,只输出info即以上级别的日志。Hello 输出了trace及以上级别的日志,但是每个都输出了两遍。你可以试一下,把第一个logger的level该为error,那么error以上的级别也是输出两遍。这时候,只要加上additivity为false就可以避免这个问题了。
当然,你可以为每个logger 都在配置文件下面做不同的配置,也可以通过继承机制,对不同包下面的日志做不同的配置。因为loggers下面可以写很多个logger。
4.复杂的配置文件
<?xml version="1.0" encoding="UTF-8"?> <configuration status="error">
<!--先定义所有的appender-->
<appenders>
<!--这个输出控制台的配置-->
<Console name="Console" target="SYSTEM_OUT">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)-->
<ThresholdFilter level="trace" onMatch="ACCEPT" onMismatch="DENY"/>
<!--这个都知道是输出日志的格式-->
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</Console>
<!--文件会打印出所有信息,这个log每次运行程序会自动清空,由append属性决定,这个也挺有用的,适合临时测试用-->
<File name="log" fileName="log/test.log" append="false">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</File> <!--这个会打印出所有的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档-->
<RollingFile name="RollingFile" fileName="logs/app.log"
filePattern="log/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout pattern="%d{yyyy-MM-dd 'at' HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n"/>
<SizeBasedTriggeringPolicy size="50MB"/>
</RollingFile>
</appenders>
<!--然后定义logger,只有定义了logger并引入的appender,appender才会生效-->
<loggers>
<!--建立一个默认的root的logger-->
<root level="trace">
<appender-ref ref="RollingFile"/>
<appender-ref ref="Console"/>
</root> </loggers>
</configuration>
说复杂,其实也不复杂,这一个例子主要是为了讲一下appenders。
这里定义了三个appender,Console,File,RollingFile,看意思基本也明白,第二个是写入文件,第三个是“循环”的日志文件,意思是日志文件大于阀值的时候,就开始写一个新的日志文件。
这里我们的配置文件里面的注释算比较详细的了。所以就大家自己看了。有一个比较有意思的是ThresholdFilter ,一个过滤器,其实每个appender可以定义很多个filter,这个功能很有用。如果你要选择控制台只能输出ERROR以上的类别,你就用ThresholdFilter,把level设置成ERROR,onMatch="ACCEPT" onMismatch="DENY" 的意思是匹配就接受,否则直接拒绝,当然有其他选择了,比如交给其他的过滤器去处理了之类的,详情大家自己去琢磨吧。
为什么要加一个这样的配置文件呢?其实这个配置文件我感觉挺好的,他的实用性就在下面:
4.1实用性
我们用日志一方面是为了记录程序运行的信息,在出错的时候排查之类的,有时候调试的时候也喜欢用日志。所以,日志如果记录的很乱的话,看起来也不方便。所以我可能有下面一些需求:
1)我正在调试某个类,所以,我不想让其他的类或者包的日志输出,否则会很多内容,所以,你可以修改上面root的级别为最高(或者谨慎起见就用ERROR),然后,加一个针对该类的logger配置,比如第一个配置文件中的设置,把他的level设置trace或者debug之类的,然后我们给一个appender-ref是定义的File那个appender(共三个appender,还记得吗),这个appender的好处是有一个append为false的属性,这样,每次运行都会清空上次的日志,这样就不会因为一直在调试而增加这个文件的内容,查起来也方便,这个和输出到控制台就一个效果了。
2)我已经基本上部署好程序了,然后我要长时间运行了。我需要记录下面几种日志,第一,控制台输出所有的error级别以上的信息。第二,我要有一个文件输出是所有的debug或者info以上的信息,类似做程序记录什么的。第三,我要单独为ERROR以上的信息输出到单独的文件,如果出了错,只查这个配置文件就好了,不会去处理太多的日志,看起来头都大了。怎么做呢,很简单。
首先,在appenders下面加一个Console类型的appender,通过加一个ThresholdFilter设置level为error。(直接在配置文件的Console这个appender中修改)
其次,增加一个File类型的appender(也可以是RollingFile或者其他文件输出类型),然后通过设置ThresholdFilter的level为error,设置成File好在,你的error日志应该不会那么多,不需要有多个error级别日志文件的存在,否则你的程序基本上可以重写了。
这里可以添加一个appender,内容如下:
<File name="ERROR" fileName="logs/error.log">
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="%d{yyyy.MM.dd 'at' HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n"/>
</File>
并在loggers中的某个logger(如root)中引用(root节点加入这一行作为子节点)。
<appender-ref ref="ERROR" />
然后,增加一个RollingFile的appender,设置基本上同上面的那个配置文件。
最后,在logger中进行相应的配置。不过如果你的logger中也有日志级别的配置,如果级别都在error以上,你的appender里面也就不会输出error一下的信息了。
还记得上面的Test类里面有一个被注释掉的for循环么?这个是为了做配置文件中RollingFile那个appender的配置的,取消注释,运行商一次或几次,看你的输出配置文件的地方,他是怎么“RollingFile”的,这里给个我测试的截图:(这里你可以把 <SizeBasedTriggeringPolicy size="50MB"/>这里的size改成2MB,要生成50MB的日志还是比较慢的。为了方便观察么!然后把Console的ThresholdFilter的level设置成error这样的较高级别,不然控制台输出东西太多了)
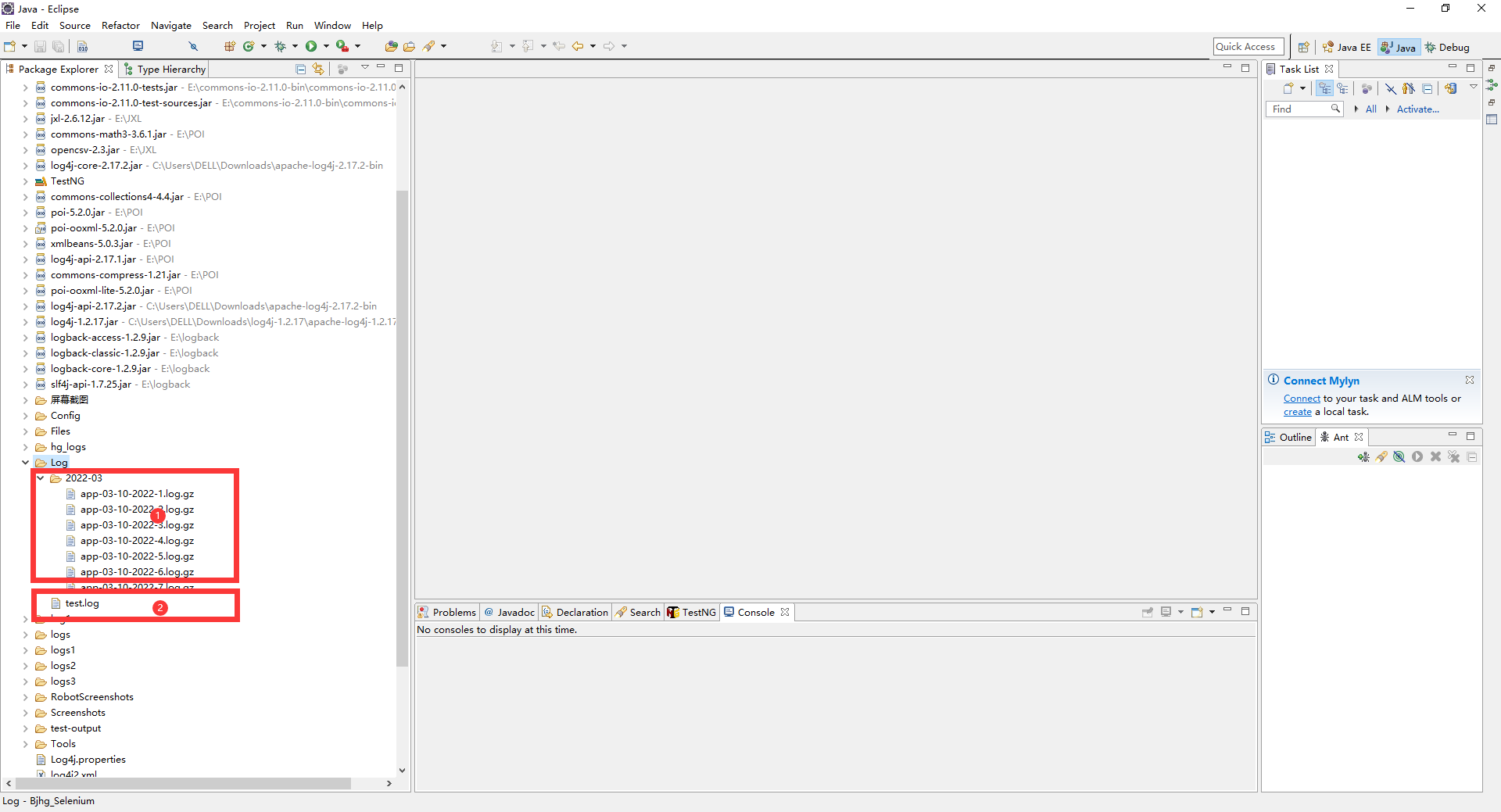
从上图可以看出:
第一部分是File这个appender生成的日志文件,你会发现你运行很多次,这个文件中的日志是被覆盖的。
第二部分是RollingFile 这个appender生成的配置文件,可以发现,默认建立的是app.log这个日志,每次超过2MB的时候,就会生成对应年-月的文件夹,和制定命名格式的log文件,而且是压缩成gz格式文件,打开资源管理器发现这个文件只有11KB,解压后就是2MB。
5.小结
好了,时间也不早了,今天就分享和讲解到这里,希望对您有所帮助,感谢您耐心地阅读!
《手把手教你》系列基础篇(八十八)-java+ selenium自动化测试-框架设计基础-Log4j 2实现日志输出-下篇(详解教程)的更多相关文章
- 《手把手教你》系列基础篇(八十七)-java+ selenium自动化测试-框架设计基础-Log4j 2实现日志输出-上篇(详解教程)
1.简介 Apache Log4j 是一个非常古老的日志框架,并且是多年来最受欢迎的日志框架. 它引入了现代日志框架仍在使用的基本概念,如分层日志级别和记录器. 2015 年 8 月 5 日,该项目管 ...
- 《手把手教你》系列基础篇(七十三)-java+ selenium自动化测试-框架设计基础-TestNG实现启动不同浏览器(详解教程)
1.简介 上一篇文章中,从TestNg的特点我们知道支持变量,那么我们这一篇就通过变量参数来启动不同的浏览器进行自动化测试.那么如何实现同时启动不同的浏览器对脚本进行测试,且听宏哥娓娓道来. 2.项目 ...
- 《手把手教你》系列基础篇(九十)-java+ selenium自动化测试-框架设计基础-Logback实现日志输出-中篇(详解教程)
1.简介 上一篇宏哥介绍是如何使用logback将日志输出到控制台中,但是如果需要发给相关人需要你拷贝出来,有时候由于控制台窗口的限制,有部分日志将会无法查看,因此我们还是需要将日志输出到文件中,因此 ...
- 《手把手教你》系列基础篇(八十)-java+ selenium自动化测试-框架设计基础-TestNG依赖测试-番外篇(详解教程)
1.简介 经过前边几篇知识点的介绍,今天宏哥就在实际测试中应用一下前边所学的依赖测试.这一篇主要介绍在TestNG中一个类中有多个测试方法的时候,多个测试方法的执行顺序或者依赖关系的问题.如果不用de ...
- 《手把手教你》系列基础篇(八十六)-java+ selenium自动化测试-框架设计基础-Log4j实现日志输出(详解教程)
1.简介 自动化测试中如何输出日志文件.任何软件,都会涉及到日志输出.所以,在测试人员报bug,特别是崩溃的bug,一般都要提供软件产品的日志文件.开发通过看日志文件,知道这个崩溃产生的原因,至少知道 ...
- 《手把手教你》系列基础篇(八十一)-java+ selenium自动化测试-框架设计基础-TestNG如何暂停执行一些case(详解教程)
1.简介 在实际测试过程中,我们经常会遇到这样的情况,开发由于某些原因导致一些模块进度延后,而你的自动化测试脚本已经提前完成,这样就会有部分模块测试,有部分模块不能进行测试.这就需要我们暂时不让一些t ...
- 《手把手教你》系列基础篇(八十三)-java+ selenium自动化测试-框架设计基础-TestNG测试报告-下篇(详解教程)
1.简介 其实前边好像简单的提到过测试报告,宏哥觉得这部分比较重要,就着重讲解和介绍一下.报告是任何测试执行中最重要的部分,因为它可以帮助用户了解测试执行的结果.失败点和失败原因.另一方面,日志记录对 ...
- 《手把手教你》系列技巧篇(三十四)-java+ selenium自动化测试-单选和多选按钮操作-中篇(详解教程)
1.简介 今天这一篇宏哥主要是讲解一下,如何使用list容器来遍历单选按钮.大致两部分内容:一部分是宏哥在本地弄的一个小demo,另一部分,宏哥是利用JQueryUI网站里的单选按钮进行实战. 2.d ...
- 《手把手教你》系列技巧篇(三十三)-java+ selenium自动化测试-单选和多选按钮操作-上篇(详解教程)
1.简介 在实际自动化测试过程中,我们同样也避免不了会遇到单选和多选的测试,特别是调查问卷或者是答题系统中会经常碰到.因此宏哥在这里直接分享和介绍一下,希望小伙伴或者童鞋们在以后工作中遇到可以有所帮助 ...
随机推荐
- ms17-010-永恒之蓝漏洞利用教程
实验环境:虚拟机:kali-linux windows 7 请自行下载安装 1.打开虚拟机 启动kali-linux 启动windows7(未装补丁) 2.获取IP地址(ifconfig ipconf ...
- 关于如何让写自然溢出hash的无辜孩子见祖宗这件事
关于如何让写自然溢出hash的无辜孩子见祖宗这件事 来源博客 这几天考试连着好几次被卡hash卡到死. 我谔谔,为什么连hash都要卡. 码力弱鸡什么时候才能站起来. 只需要任意两种字符,比如噫呜呜噫 ...
- loj2341「WC2018」即时战略(随机化,LCT/动态点分治)
loj2341「WC2018」即时战略(随机化,LCT/动态点分治) loj Luogu 题解时间 对于 $ datatype = 3 $ 的数据,explore操作次数只有 $ n+log n $ ...
- Spring Boot 中的监视器是什么?
Spring boot actuator 是 spring 启动框架中的重要功能之一.Spring boot 监视器可帮助您访问生产环境中正在运行的应用程序的当前状态.有几个指标必须在生产环境中进行检 ...
- ActiveMQ数据接收类型问题
一.问题描述 最近开发了一个工具,功能是监听ActiveMQ消息然后做相应的处理,本地自测没有问题,但是部署在现场出现如下报错: [WARN ] [2020-08-27 19:49:42] [org. ...
- Java 中的 LinkedList 是单向链表还是双向链表?
是双向链表,你可以检查 JDK 的源码.在 Eclipse,你可以使用快捷键 Ctrl + T, 直接在编辑器中打开该类.
- jsp页面学习之"javascript:void(0)"的使用
javascript:void(0) 仅仅表示一个死链接 如果是个# javascript:void(#),就会出现跳到顶部的情况,搜集了一下解决方法 1:<a href="####& ...
- Pycharm使用 Ctrl+滚轮 调整字体大小
首先,打开File中的Settings 然后,点开Editor内的General 最后,在3 指向的位置勾选:Change font size (Zoom)with Ctrl+Mouse Whel 这 ...
- 基于Vue实现关键词实时搜索高亮显示关键词
最近在做移动real-time-search于实时搜索和关键词高亮显示的功能,通过博客的方式总结一下,同时希望能够帮助到别人~~~ 如果不喜欢看文字的朋友我写了一个demo方便已经上传到了github ...
- Anaconda安装tensorflow和keras(gpu版,超详细)
本人配置:window10+GTX 1650+tensorflow-gpu 1.14+keras-gpu 2.2.5+python 3.6,亲测可行 一.Anaconda安装 直接到清华镜像网站下载( ...