os、sys、json、subprocess模块
今日内容概要
1.os模块
2.sys模块
3.json模块
4.subprocess模块

今日内容详细
os模块
"""该模块主要是跟操作系统打交道"""
import os
1.创建目录(文件夹)
os.mkdir(r'aaa') # 使用相对路径 在当前执行文件所在的路径下创建一个aaa文件夹
os.mkdir(r'bbb/ccc') # 报错 mkdir 只能创建单极目录
os.makedirs(r'aaa') # 与mkdir一样
os.makedirs(r'bbb/ccc') # 可以创建多级目录
2.删除目录(文件夹)
os.rmdir(r'aaa') # 可以删除单级目录 只能删空的单极目录
os.removedirs(r'ccc') # 可以删除单级目录
os.removedirs(r'路径') # 删除目录之后如果外层的目录也是空的则继续删除
3.查看某个路径下所有的文件名称(文件,文件夹)
print(os.listdir())
print(os.listfir(r'/Users'))
4.删除文件,重命名文件
os.remove(r'a.txt')
os.rename(r'a.txt',r'aaa.txt')
5.获取当前路径,切换路径
print(os.getcwd())
os.chdir(r'/Users/jiboyuan')
print(os.getcwd())
6.软件开发目录规范 启动脚本兼容性操作
os.path.dirname(__file__) # 动态获取当前执行文件所在的绝对路径 D:\day21
os.path.dirname(os.path.dirname(__file__)) # 每嵌套一层就是往上切换一层 D:\
print(os.path.abspath(__file__)) # 动态获取当前执行文件自身的路径 # D:\day21\a.py
7.判断文件是否存在
print(os.path.exists(r'ATM')) # 打印结果为 True 判断所给的路径是否存在
print(os.path.exists(r'01 作业讲解.py')) # True 判断路径是否是一个文件夹
print(os.path.isdir(r'ATM')) # True 判断路径是否是一个文件夹
print(os.path.isdir(r'01 作业讲解.py')) # False 判断路径是否是一个文件夹
print(os.path.isfile(r'ATM')) # False 判断路径是否是一个文件
print(os.path.isfile(r'01 作业讲解.py')) # True 判断路径是否是一个文件
8.拼接路径(极容易忽略)
base_dir = 'ATM'
exe_dir = '01 作业讲解.py'
"""拼接成py文件的路径"""
print(base_dir + '/' + exe_dir) # 路径分隔符在不同的系统下是不一样的 使用加号的话 兼容性极差 不推荐使用!!!
res = os.path.join(base_dir,exe_dir) #能够自动识别当前操作系统的分隔符
print(res)
9.获取文件大小(字节 bytes)
print(os.path.getsize(r'ATM')) # 128bytes
print(os.path.getsize(r'a.txt')) # 14bytes
sys模块
"""该模块主要跟python解释器打交道"""
import sys
1.列举当前执行文件所在的sys.path(掌握)
print(sys.path)
2.获取解释器版本信息(了解)
print(sys.version)
3.获取平台信息(了解)
print(sys.platform)
4.自定义命令行操作
print(sys.argv)
"""
cmd终端可以使用windows+r并输入cmd唤起
也可以在pycharm直接使用快捷方式Terminal
模拟cmd并自动切换到当前执行文件所在的路径下
"""
json模块
"""json模块是一个序列化模块 主要用于跨语言传输数据""" 1.json格式数据是不同编程语言之间数据交互的媒介
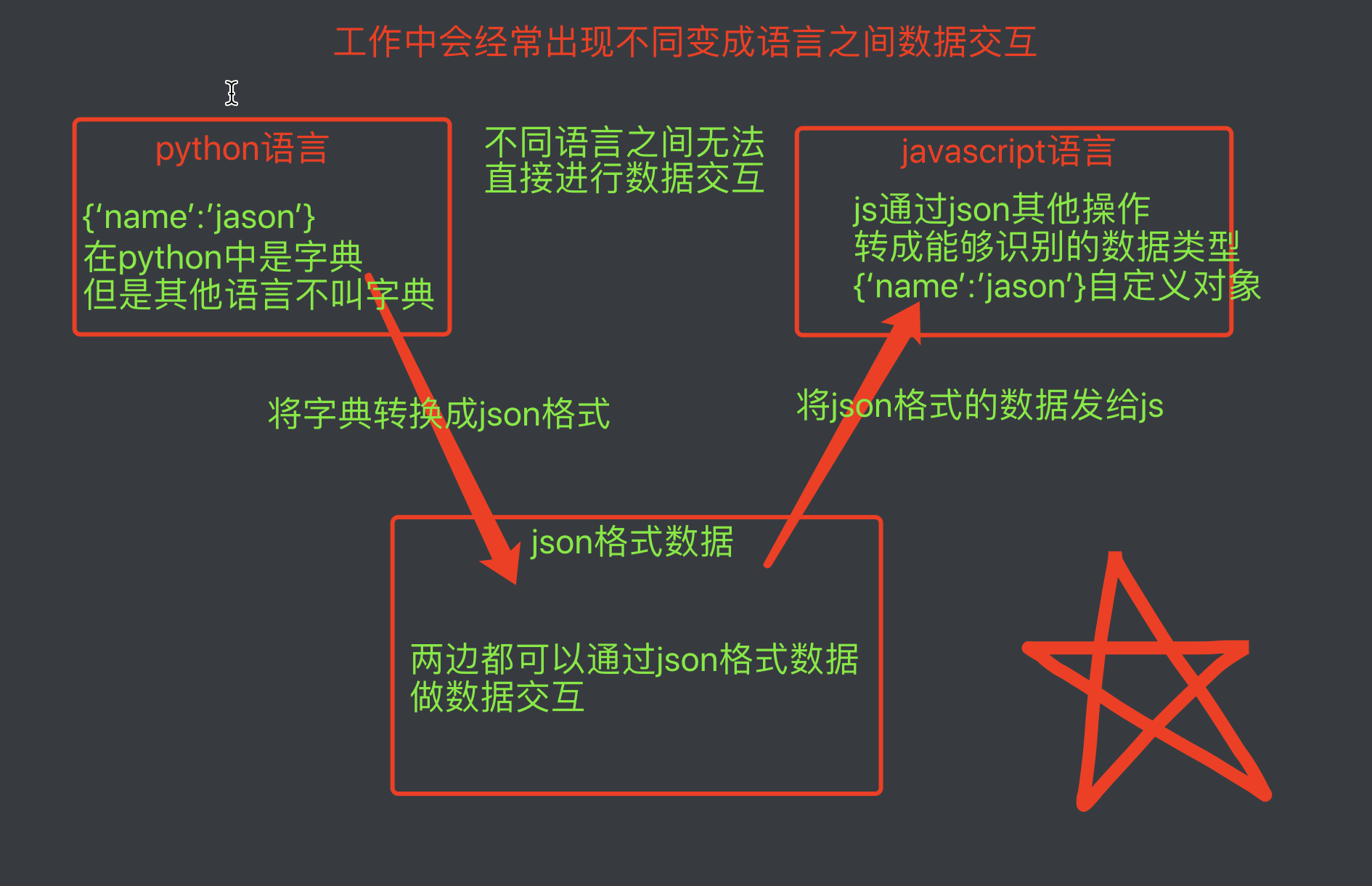
2.json格式数据的具体特征
结论1中有一个小细节: 数据基于网络传输肯定是二进制格式
在python中bytes类型的数据可以直接看成是二进制数据
python中哪些数据可以转成bytes类型 (通过编码encode())
"""只有字符串可以""" # 由上述推论可知 json格式数据 本质应该属于字符串类型
# 双引号是json格式数据独有的标志符号!!!
import json
d = {'username':'jason','pwd':123}
print(d, type(d)) # {'username': 'jason', 'pwd': 123} <class 'dict'>
res = json.dumps(d)
print(res, type(res)) # {"username": "jason", "pwd": 123} <class 'str'>
print(str(d),type(str(d))) # {'username': 'jason', 'pwd': 123} <class 'str'>
d = {"username":"jason","pwd":123}
print(d) # {'username': 'jason', 'pwd': 123} 不是json格式
res1 = '{"username":"jason","pwd":123}'
print(res1) # {"username":"jason","pwd":123} 算json格式
json模块具体操作
1. json.dumps() 序列化
将python数据类型转换成json格式字符串
d = {'username':'jason','pwd':123}
res = json.dumps(d)
print(res, type(res)) # json格式字符串
'''假设将该字符串基于网络发给了另外一个python程序'''
# 先将bytes类型转换成字符串
2. json.loads() 反序列化
将json格式字符串转换成对应的数据类型
encode_str = res.encode('utf8')
json_str = encode_str.decode('utf8')
print(json_str,type(json_str))
res1 = json.loads(json_str)
print(res1, type(res1)) # {'username': 'jason', 'pwd': 123} <class 'dict'>
# 如果不能理解跨语言传输的作用 那么权且理解下面的操作即可
d = {'username': 'jason', 'pwd': 123}
# 将上述字典写入文件
with open(r'a.txt','w',encoding='utf8') as f:
# f.write(d)
# f.write(str(d))
# f.write(json.dumps(d))
json.dump(d, f)
# 将文件内容获取出来
with open(r'a.txt','r',encoding='utf8') as f:
# data = f.read()
# res = json.loads(data)
# print(res, type(res))
data = json.load(f)
print(data, type(data))
"""
如果json模块需要配合文件一起使用的话 有固定的方法
json.dump()
将其他数据类型直接写入文件(自动转json格式字符串)
json.load()
将文件数据直接转成对应的数据类型(自动反序列化)
"""
# 强调:不是所有的数据类型都支持序列化
"""
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+--------------+
| list, tuple | array |
+-------------------+--------------+
| str | string |
+-------------------+--------------+
| int, float | number |
+-------------------+--------------+
| True | true |
+-------------------+--------------+
| False | false |
+-------------------+--------------+
| None | null |
+-------------------+--------------+
"""
pickle模块
# 基本不用
因为它不支持跨语言传输 只能识别python代码
'''直接忽略 不用掌握'''
subprocess模块
import subprocess
# ls在终端的意思就是查看当前路径下所有的文件名称
res = subprocess.Popen('ls',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
print('stdout',res.stdout.read().decode('utf8')) # 获取正确命令执行之后的结果
print('stderr',res.stderr.read().decode('utf8')) # 获取错误命令执行之后的结果
"""
该模块可以实现远程操作其他计算机的功能
动态获取命令执行并返回结果
eg:类似于Xshell软件的功能
"""

os、sys、json、subprocess模块的更多相关文章
- 模块random+os+sys+json+subprocess
模块random+os+sys+json+subprocess 1. random 模块 (产生一个随机值) import random 1 # 随机小数 2 print(random.rando ...
- os、json、sys、subprocess模块
os模块 import os 1.创建目录(文件夹) os.mkdir(r'a') # 相对路径 只能创建单级目录 os.makedirs(r'a\b') # 可以创建单级和多及目录 2.删除目录 o ...
- 7.18 collection time random os sys 序列化 subprocess 等模块
collection模块 namedtuple 具名元组(重要) 应用场景1 # 具名元组 # 想表示坐标点x为1 y为2 z为5的坐标 from collections import namedtu ...
- python之os与json&pickle模块
一.os模块 简单概述一下os模块就是与操作系统交互的一个接口 import os #os.getcwd() print(os.getcwd()) # 获取到当前工作目录 # 运行结果:E:\pyt ...
- 学到了林海峰,武沛齐讲的Day22-完 os sys json pickle shelve XML re
__ file__ ===== 文件路径 os.path.dirname( 路径 )=======到上一层目录 os sys
- python之常见模块(time,datetime,random,os,sys,json,pickle)
目录 time 为什么要有time模块,time模块有什么用?(自己总结) 1. 记录某一项操作的时间 2. 让某一块代码逻辑延迟执行 时间的形式 时间戳形式 格式化时间 结构化时间 时间转化 总结: ...
- python基础四(json\os\sys\random\string模块、文件、函数)
一.文件的修改 文件修改的两种思路: 1.把文件内容拿出来,做修改后,清空原来文件的内容,然后把修改过的文件内容重新写进去. 步骤: 1.打开文件:f=open('file','a+') #必须用a ...
- Day 17 time,datetime,random,os,sys,json,pickle
time模块 1.作用:打印时间,需要时间的地方,暂停程序的功能 时间戳形式 time.time() # 1560129555.4663873(python中从1970年开始计算过去了多少秒) 格式化 ...
- Python第十一天 异常处理 glob模块和shlex模块 打开外部程序和subprocess模块 subprocess类 Pipe管道 operator模块 sorted函数 os模块 hashlib模块 platform模块 csv模块
Python第十一天 异常处理 glob模块和shlex模块 打开外部程序和subprocess模块 subprocess类 Pipe管道 operator模块 sorted函 ...
- oldboy edu python full stack s22 day16 模块 random time datetime os sys hashlib collections
今日内容笔记和代码: https://github.com/libo-sober/LearnPython/tree/master/day13 昨日内容回顾 自定义模块 模块的两种执行方式 __name ...
随机推荐
- 拓扑排序 python
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1.给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] , ...
- Xgboost的基本使用
import xgboost as xgb from sklearn.model_selection import train_test_split import pandas as pd data ...
- NET 中反射的用法
1. 反射的学习 A.反射的定义 B.反射举例 namespace Com.Meteor.Interface { public interface IHelper { void Query(); ...
- .net为程序集签名之.pfx文件
项目中误删了.pfx证书文件,导致项目无法启动. 以为很快就能在网上找到解决方案,应该没关系,不过找了半个小时,都没有有效的解决办法,搜出来很多.pfx文件是一个证书文件,里面存储公钥和私钥,对于我要 ...
- SQL Server 2008安全加固手册
1.身份鉴别 1.1避免使用空密码和弱口令 要求:应对登录操作系统和数据库系统的用户进行身份标识和鉴别. 目的:操作系统和数据库系统管理用户身份鉴别信息应具有不易被冒用的特点,口令应有复杂度要求并定期 ...
- gofs使用教程-基于golang的开源跨平台文件同步工具
概述 gofs是基于golang开发的一款开箱即用的跨平台文件同步工具,开源地址如下:https://github.com/no-src/gofs,欢迎点个Star或者提交Issue和PR,共同进步! ...
- Oracle SQL Developer.exe双击启动错误信息dll未找到
下载地址:https://www.oracle.com/tools/downloads/sqldev-downloads.html 官网相应的解决方法已经说明了
- websocket使用nginx代理后连接频繁打开和关闭
前几天开发了一个功能,使用websocket向前台发送消息,与前端联调时一切正常,但是发布到环境出现如下报错: 发现404,无法找到连接,突然想到环境上是走nginx代理的,应该是nginx没有配置代 ...
- Java 中的 ReadWriteLock 是什么?
读写锁是用来提升并发程序性能的锁分离技术的成果.
- 杭电OJ 1248 不死族巫妖王 完全背包问题 字节跳动 研发岗编程原题
转载至:https://blog.csdn.net/ssdut_209/article/details/51557776 Problem Description不死族的巫妖王发工资拉,死亡骑士拿到一张 ...