深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛。
本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现。
1. StepLR
- 按固定的训练epoch数进行学习率衰减。
- 举例说明:
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
在上述例子中,每30个epochs衰减十倍学习率。
- 计算公式和pytorch计算代码如下:
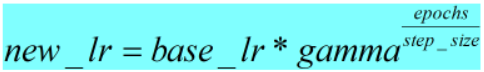
def _get_closed_form_lr(self):
return [base_lr * self.gamma ** (self.last_epoch // self.step_size)
for base_lr in self.base_lrs]
- pytorch调用及相关参数:
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)
optimizer:表示使用的优化器;
step_size:表示学习率调整步长;
gamma:表示学习率衰减乘法因子,默认:0.1;
last_epoch:表示上一个epoch数,默认:-1,此时学习率的值为初始学习率;
verbose:表示是否每次更新都输出一次学习率的值,默认:False。
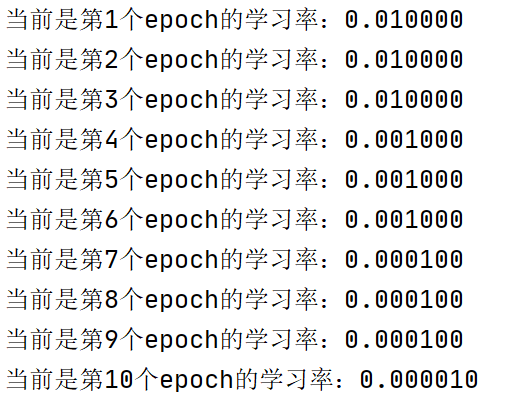
- 代码示例及结果展示:
lr_scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=3,gamma=0.1,last_epoch=-1)
设置10个epoch时,输出训练过程中的学习率如下:
2. MultiStepLR
- 当epoch数达到固定数值进行学习率衰减。
- 举例说明:
# milestones=[30,80]
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
在上述例子中,当epoch达到milestones中的数值时进行学习率衰减。
- 计算公式和pytorch计算代码如下:

其中bisect_right函数表示epoch数插入milestones中列表的位置,
例如:milstones=[2,5,8]
last_epoch==1→bisect_right(milestones,last_epoch)=0;
last_epoch==3→bisect_right(milestones,last_epoch)=1;
last_epoch==6→bisect_right(milestones,last_epoch)=2;
def _get_closed_form_lr(self):
milestones = list(sorted(self.milestones.elements()))
return [base_lr * self.gamma ** bisect_right(milestones, self.last_epoch)
for base_lr in self.base_lrs]
- pytorch调用及相关参数:
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
milestones:一个关于epoch索引的列表,当epoch值达到列表中的数值时进行学习率衰减。
其他参数相同。
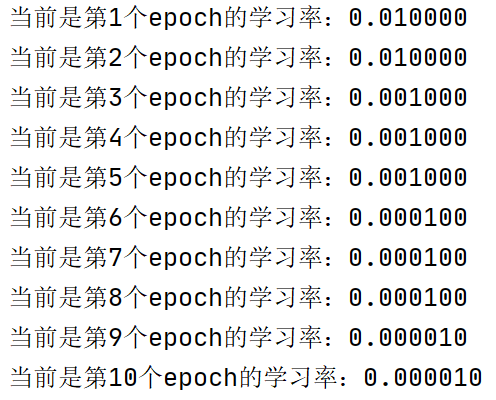
- 代码示例及结果展示:
lr_scheduler=torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=[2,5,8],gamma=0.1,last_epoch=-1)
3. ExponentialLR
- 根据当前epoch进行学习率衰减
- 计算公式和pytorch计算代码如下:
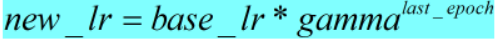
def _get_closed_form_lr(self):
return [base_lr * self.gamma ** self.last_epoch
for base_lr in self.base_lrs]
- pytorch调用及相关参数:
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1, verbose=False)
- 代码示例及结果展示:
lr_scheduler=torch.optim.lr_scheduler.ExponentialLR(optimizer,gamma=0.1,last_epoch=-1)

4. linearLR
- 在epoch数达到total_iters数值之前,使用线性改变乘法因子衰减学习率。
- 计算公式和pytorch计算代码如下:

def _get_closed_form_lr(self):
return [base_lr * (self.start_factor +
(self.end_factor - self.start_factor) * min(self.total_iters, self.last_epoch) / self.total_iters)
for base_lr in self.base_lrs]
- pytorch调用及相关参数:
torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=0.3333333333333333, end_factor=1.0, total_iters=5, last_epoch=- 1, verbose=False)
start_factor: 在第一个epoch中乘以base_lr的数值,默认1/3;
end_factor:在线性变化过程结束时乘以base_lr的数值,默认:1;
total_iters:乘法因子达到1的迭代次数,默认:5。
- 举例说明:
lr_scheduler = LinearLR(optimizer, start_factor=0.5, total_iters=4)
base_lr=0.05
# epoch == 0→lr = base_lr * start_factor = 0.05 * 0.5=0.025;
# epoch == 1→lr = 0.05 * (0.5 + 0.5 * 0.25) = 0.3125;
......
# epoch ≥ 4→lr = base_lr * end_factor = 0.05(当epoch数等于total_iters时,min(self.total_iters, self.last_epoch) / self.total_iters = 1)
5. ConstantLR
- 在epoch数达到total_iters数值之前,使用常数因子衰减学习率。
- 计算公式和pytorch计算代码如下:
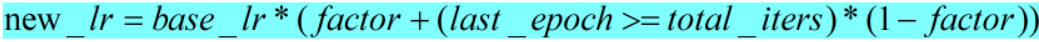
def _get_closed_form_lr(self):
return [base_lr * (self.factor + (self.last_epoch >= self.total_iters) * (1 - self.factor))
for base_lr in self.base_lrs]
- pytorch调用及相关参数:
torch.optim.lr_scheduler.ConstantLR(optimizer, factor=0.3333333333333333, total_iters=5, last_epoch=- 1, verbose=False)
factor:在epoch达到total_iters之前,学习率乘以的常数因子,默认1/3;
total_iters:衰减学习率的步数。
- 举例说明:
lr_scheduler = ConstantLR(self.opt, factor=0.5, total_iters=4)
base_lr = 0.05
# epoch == 0 → lr = base_lr * (factor + 0 * (1-factor)) = 0.05 * 0.5 = 0.025
......
# epoch == 4 → lr = base_lr * (factor + 1 - factor) = 0.05
6. LambdaLR
- 使用lambda定义的函数衰减学习率。
- 计算公式和pytorch计算代码如下:
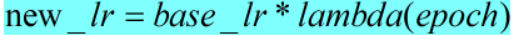
def get_lr(self):
if not self._get_lr_called_within_step:
warnings.warn("To get the last learning rate computed by the scheduler, "
"please use `get_last_lr()`.") return [base_lr * lmbda(self.last_epoch)
for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs)]
- pytorch调用及相关参数:
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
lr_lambda:当给定epoch数,计算乘法因子的函数(可以自己定义)
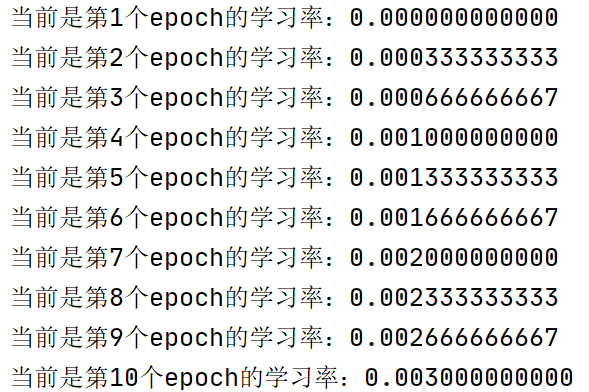
- 代码示例及结果展示:
lr_scheduler=torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda=lambda epoch:epoch/30 )
7. MultiplicativeLR
- 同样是使用了与epoch有关的lambda函数,与LambdaLR不同的地方在于,它是对old_lr更新。
- 计算公式和pytorch计算代码如下:
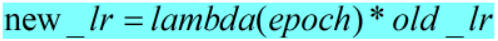
def get_lr(self):
if not self._get_lr_called_within_step:
warnings.warn("To get the last learning rate computed by the scheduler, "
"please use `get_last_lr()`.", UserWarning) if self.last_epoch > 0:
return [group['lr'] * lmbda(self.last_epoch)
for lmbda, group in zip(self.lr_lambdas, self.optimizer.param_groups)]
else:
return [group['lr'] for group in self.optimizer.param_groups]
- pytorch调用及相关参数:
torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
8.CosineAnnealingLR
- 模拟余弦退火曲线调整学习率
- 计算公式和pytorch计算代码如下:
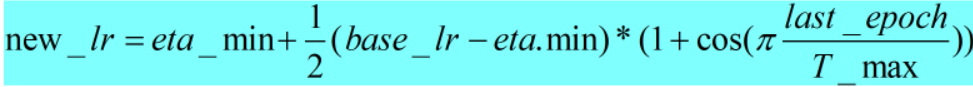
def _get_closed_form_lr(self):
return [self.eta_min + (base_lr - self.eta_min) *
(1 + math.cos(math.pi * self.last_epoch / self.T_max)) / 2
for base_lr in self.base_lrs]
- pytorch调用及相关参数:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1, verbose=False)
T_max:最大迭代次数,一次学习率周期的迭代次数。
eta_min:最小学习率,默认:0。
- 代码示例及结果展示:
lr_scheduler=torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max=3,eta_min=0)
base_lr=0.01

当epoch是T_max的奇数倍时,学习率会下降到最小值eta_min。
9. ChainedScheduler
- 可以调用其他学习率调整策略。
- pytorch调用及相关参数:
torch.optim.lr_scheduler.ChainedScheduler(schedulers)
schedules:设置的其他学习率调整策略,可以是一个包含多个学习率调整策略的列表。
- 代码示例及结果:
scheduler1 = ConstantLR(self.opt, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(self.opt, gamma=0.9)
lr_scheduler = ChainedScheduler([scheduler1, scheduler2])
schedules里的学习率调整策略同时使用
base_lr = 1
# lr = 0.09 if epoch == 0 (先使用scheduler2策略得到lr = 0.9;再使用scheduler1策略得到最终new_lr = 0.09)
# lr = 0.081 if epoch == 1
# lr = 0.729 if epoch == 2
# lr = 0.6561 if epoch == 3
# lr = 0.59049 if epoch >= 4
10.SequentialLR
- 与ChainedScheduler在每一个epoch中同时调用schedules中的学习率策略不同的是,SequentialLR针对epoch按顺序调用schedules中的学习率策略。
- pytorch调用及相关参数:
torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers, milestones, last_epoch=- 1, verbose=False)
- 代码示例及结果:
scheduler1 = ConstantLR(self.opt, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(self.opt, gamma=0.9)
lr_scheduler = SequentialLR(optimizer, schedulers=[scheduler1, scheduler2], milestones=[2])
base_lr = 1
# lr = 0.1 if epoch == 0
# lr = 0.1 if epoch == 1
# lr = 0.9 if epoch == 2
# lr = 0.81 if epoch == 3
# lr = 0.729 if epoch == 4
epoch<milestones,调用scheduler1学习率调整策略,epoch≥milestones,调用scheduler2学习率调整策略。
11.ReduceLROnPlateau
- 当训练指标不再改进时,调整学习率。
- pytorch调用及相关参数:
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
mode:有min、max两种模式,在 min 模式下,当指标的数量停止减少时(如loss),学习率将减少; 在max模式下,当指标的数量停止增加时(如accuracy),学习率将减少,默认值:min;
factor:学习率减少的倍数,new_lr = old_lr * factor,默认:0.1;
patience:指标没有提升的epoch数,之后降低学习率。例如,patience = 2,会忽略前 2 个没有改善的 epoch,并且只有在第 3 个 epoch 之后指标仍然没有改善的情况下降低 学习率。 默认值:10。
threshold:衡量新的最佳阈值,只关注重大变化。 默认值:1e-4。
threshold_mode:有rel、abs两种模式,
cooldown:在 学习率减少后恢复正常操作之前要等待的 epoch 数。 默认值:0。
min_lr:标量或标量列表。学习率的下限。 默认值:0。
eps:应用于 学习率的最小衰减。 如果新旧 学习率之间的差异小于 eps,则忽略更新。 默认值:1e-8。
- 代码示例及结果:
lr_scheduler=torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode='min',patience=2,cooldown=2)

第一个epoch是初始学习率;
设置patience = 2,即指标在经历3个epoch后仍然没有提升,衰减学习率,new_lr = old_lr * factor(0.1),如图中第4个epoch时开始衰减学习率;
设置cooldown = 2,即衰减学习率后有2个epoch的cooldown时期(5、6epoch),在cooldown时期不进行patience阶段的epoch计数;
cooldown时期结束恢复patience阶段epoch计数(图中从第7个epoch开始计数,在第10个epoch学习率衰减)。
12.CyclicLR
- 根据循环学习策略设置学习率。(每训练一个batch,更新一次学习率)
- 在《 Cyclical Learning Rates for Training Neural Networks》这篇文章中有详细描述。
- pytorch调用及相关参数:
torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=- 1, verbose=False)
base_lr:初始学习率,循环中的学习率下边界;
max_lr:每个参数组在循环中的上层学习率边界。从功能上讲,它定义了周期幅度 (max_lr - base_lr)。任何周期的 lr 是 base_lr 和一些幅度缩放的总和;因此 max_lr 实际上可能无法达到,具体取决于缩放函数。
step_size_up:在一个周期增加的一半中训练迭代的次数。默认值:2000;
step_size_down:循环减半中的训练迭代次数。如果 step_size_down 为 None,则设置为 step_size_up。默认值:None;
mode:包含三种{triangular, triangular2, exp_range} ,如果 scale_fn 不是 None,则忽略此参数。默认值:“triangular”;
gamma:‘exp_range’ 缩放函数中的常数:gamma**(cycle iterations)默认值:1.0;
scale_fn:由单个参数 lambda 函数定义的自定义缩放策略,其中 0 <= scale_fn(x) <= 1 for all x >= 0。如果指定,则忽略“mode”。默认值:None;
scale_mode:{‘cycle’, ‘iterations’}。定义是否在cycle number或cycle iterations (training iterations since start of cycle)上评估 scale_fn。默认值:cycle;
cycle_momentum:如果为真,则动量与“base_momentum”和“max_momentum”之间的学习率成反比。默认值:True;
base_momentum: 循环中的动量下边界,默认值:0.8;
max_monmentum:循环中的动量上边界,默认值:0.9;
- 官方代码及示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.01, max_lr=0.1)
data_loader = torch.utils.data.DataLoader(...)
for epoch in range(10):
for batch in data_loader:
train_batch(...)
scheduler.step()
13.OneCycleLR
- 根据循环学习策略设置学习率。(每训练一个batch,更新一次学习率)
- 相关文章《Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates》
- pytorch调用及相关参数:
torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy='cos', cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25.0, final_div_factor=10000.0, three_phase=False, last_epoch=- 1, verbose=False)
max_lr:在循环中的上层学习率边界;
total_steps:循环总步数。如果此处未提供值,则必须通过提供 epochs 和 steps_per_epoch 的值来推断。默认值:None;
epochs:训练的epochs;
steps_per_epoch:每个 epoch 训练的步数;
pct_start:提高学习率所花费的周期百分比(in number of steps)。默认值:0.3;
anneal_strategy:{‘cos’, ‘linear’} 指定退火策略:“cos”表示余弦退火,“linear”表示线性退火。默认值:'cos';
div_factor:通过 initial_lr = max_lr/div_factor 确定初始学习率 默认值:25;
final_div_factor:通过 min_lr = initial_lr/final_div_factor 确定最小学习率 默认值:1e4;
three_phase:如果为 True,则使用计划的第三阶段根据“final_div_factor”消除学习率,而不是修改第二阶段(前两个阶段将关于“pct_start”指示的步骤对称)。
- 官方代码及示例:
data_loader = torch.utils.data.DataLoader(...)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, steps_per_epoch=len(data_loader), epochs=10)
for epoch in range(10):
for batch in data_loader:
train_batch(...)
scheduler.step()
14.CosineAnnealingWarmRestarts
- 和余弦退火类似,多了warmrestart操作。
- pytorch调用及相关参数:
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=- 1, verbose=False)
T_0:第一次restart的迭代次数;
T_mult:在一次restar后,因子增加:math:`T_{i};
eta_min:最小学习率,默认值:0。
- 官方代码及示例:
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0, T_mult)
iters = len(dataloader)
for epoch in range(20):
for i, sample in enumerate(dataloader):
inputs, labels = sample['inputs'], sample['labels']
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step(epoch + i / iters)
参考及引用:
1.https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
2.https://zhuanlan.zhihu.com/p/352744991
3.https://blog.csdn.net/qyhaill/article/details/103043637
深度学习训练过程中的学习率衰减策略及pytorch实现的更多相关文章
- 【腾讯Bugly干货分享】深度学习在OCR中的应用
本文来自于腾讯bugly开发者社区,未经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/5809bb47cc5e52161640c5c8 Dev Club 是一个交流移动 ...
- 深度学习在 CTR 中应用
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:高航 一. Wide&&Deep 模型 首先给出Wide && Deep [1] 网络结构: 本质上 ...
- 【AI in 美团】深度学习在OCR中的应用
AI(人工智能)技术已经广泛应用于美团的众多业务,从美团App到大众点评App,从外卖到打车出行,从旅游到婚庆亲子,美团数百名最优秀的算法工程师正致力于将AI技术应用于搜索.推荐.广告.风控.智能调度 ...
- 中文译文:Minerva-一种可扩展的高效的深度学习训练平台(Minerva - A Scalable and Highly Efficient Training Platform for Deep Learning)
Minerva:一个可扩展的高效的深度学习训练平台 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2015-12-1 声明 ...
- 【深度学习】CNN 中 1x1 卷积核的作用
[深度学习]CNN 中 1x1 卷积核的作用 最近研究 GoogLeNet 和 VGG 神经网络结构的时候,都看见了它们在某些层有采取 1x1 作为卷积核,起初的时候,对这个做法很是迷惑,这是因为之前 ...
- MLPerf结果证实至强® 可有效助力深度学习训练
MLPerf结果证实至强 可有效助力深度学习训练 核心与视觉计算事业部副总裁Wei Li通过博客回顾了英特尔这几年为提升深度学习性能所做的努力. 目前根据英特尔 至强 可扩展处理器的MLPerf结果显 ...
- (转)理解YOLOv2训练过程中输出参数含义
最近有人问起在YOLOv2训练过程中输出在终端的不同的参数分别代表什么含义,如何去理解这些参数?本篇文章中我将尝试着去回答这个有趣的问题. 刚好现在我正在训练一个YOLOv2模型,拿这个真实的例子来讨 ...
- 理解YOLOv2训练过程中输出参数含义
原英文地址: https://timebutt.github.io/static/understanding-yolov2-training-output/ 最近有人问起在YOLOv2训练过程中输出在 ...
- java web应用调用python深度学习训练的模型
之前参见了中国软件杯大赛,在大赛中用到了深度学习的相关算法,也训练了一些简单的模型.项目线上平台是用java编写的web应用程序,而深度学习使用的是python语言,这就涉及到了在java代码中调用p ...
随机推荐
- Unreal ListView使用篇
应用 ListView,在Unreal UI界面开发中用途非常广泛,基本只要你使用列表,就得需要用ListView.比如排行榜100个列表,界面上只需要显示出10个,我们肯定不能生成100个ui实例, ...
- 图解AI数学基础 | 概率与统计
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/83 本文地址:http://www.showmeai.tech/article-det ...
- java宝典笔记(一)
第四章java基础知识 4.1基本概念 一.java优点 1.面向对象(封装.继承.多态) 2.可移植性.平台无关,一次编译,到处运行.Windows,Linux,macos等.java为解释性语言, ...
- python语法:注释
Python语法:注释 python语言中的注释是来帮助程序员理解并读懂代码内容的文字.当然,注释不仅在python语言中是这个作用,在其他语言中也几乎一样. python注释的生成方式 所有演示 ...
- Pandas:plot相关函数
0.注意事项 及 各种错误 1)绘制bar图时,如果出现重复的x值被合并到一个情况(导致X轴应该显示内容有缺失),可能是由于Pandas版本太低: 2)无法设置中文title,在代码中加入两句话: p ...
- Matplotlib:Python三维绘图
1.创建三维坐标轴对象Axes3D 创建Axes3D主要有两种方式,一种是利用关键字projection='3d'来实现,另一种是通过从mpl_toolkits.mplot3d导入对象Axes3D来实 ...
- C#集合,字典的运用
三个题解释所有 using System;using System.Collections.Generic;using System.Linq;using System.Text;using Syst ...
- CLR的GC工作模式介绍(Workstation和Server)
CLR的核心功能之一就是垃圾回收(garbage collection),关于GC的基本概念本文不在赘述.这里主要针对GC的两种工作模式展开讨论和研究. Workstaction模式介绍 该模式设计的 ...
- 微信小程序商品发布
<!--pages/good/good.wxml--> <!--商品发布--> <form bindsubmit="formSubmit"> & ...
- go1.18泛型的简单尝试
今天golang终于发布了1.18版本,这个版本最大的一个改变就是加入了泛型.虽然没有在beta版本的时候尝试泛型,但是由于在其他语言的泛型经验,入手泛型不是件难事~ 官方示例 Tutorial: G ...