爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架
什么是Scrapy
- 基于Twisted的异步处理框架
- 纯python实现的爬虫框架
- 基本结构:5+2框架,5个组件,2个中间件

5个组件:
- Scrapy Engine:引擎,负责其他部件通信 进行信号和数据传递;负责Scheduler、Downloader、Spiders、Item Pipeline中间的通讯信号和数据的传递,此组件相当于爬虫的“大脑”,是整个爬虫的调度中心
- Scheduler:调度器,将request请求排列入队,当引擎需要交还给引擎,通过引擎将请求传递给Downloader;简单地说就是一个队列,负责接收引擎发送过来的 request请求,然后将请求排队,当引擎需要请求数据的时候,就将请求队列中的数据交给引擎。初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取,同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如post请求的URL)
- Downloader:下载器,将引擎engine发送的request进行接收,并将response结果交还给引擎engine,再由引擎传递给Spiders处理
- Spiders:解析器,它负责处理所有responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器);同时也是入口URL的地方
- Item Pipeline:数据管道,就是我们封装去重类、存储类的地方,负责处理 Spiders中获取到的数据并且进行后期的处理,过滤或者存储等等。当页面被爬虫解析所需的数据存入Item后,将被发送到项目管道(Pipeline),并经过几个特定的次序处理数据,最后存入本地文件或存入数据库
2个中间件:
- Downloader Middlewares:下载中间件,可以当做是一个可自定义扩展下载功能的组件,是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。通过设置下载器中间件可以实现爬虫自动更换user-agent、IP等功能。
- Spider Middlewares:爬虫中间件,Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。自定义扩展、引擎和Spider之间通信功能的组件,通过插入自定义代码来扩展Scrapy功能。
Scrapy操作文档(中文的):https://www.osgeo.cn/scrapy/topics/spider-middleware.html
Scrapy框架的安装
cmd窗口,pip进行安装
pip install scrapy
Scrapy框架安装时常见的问题
找不到win32api模块----windows系统中常见
pip install pypiwin32
创建Scrapy爬虫项目
新建项目
scrapy startproject xxx项目名称
实例:
scrapy startproject tubatu_scrapy_project
项目目录
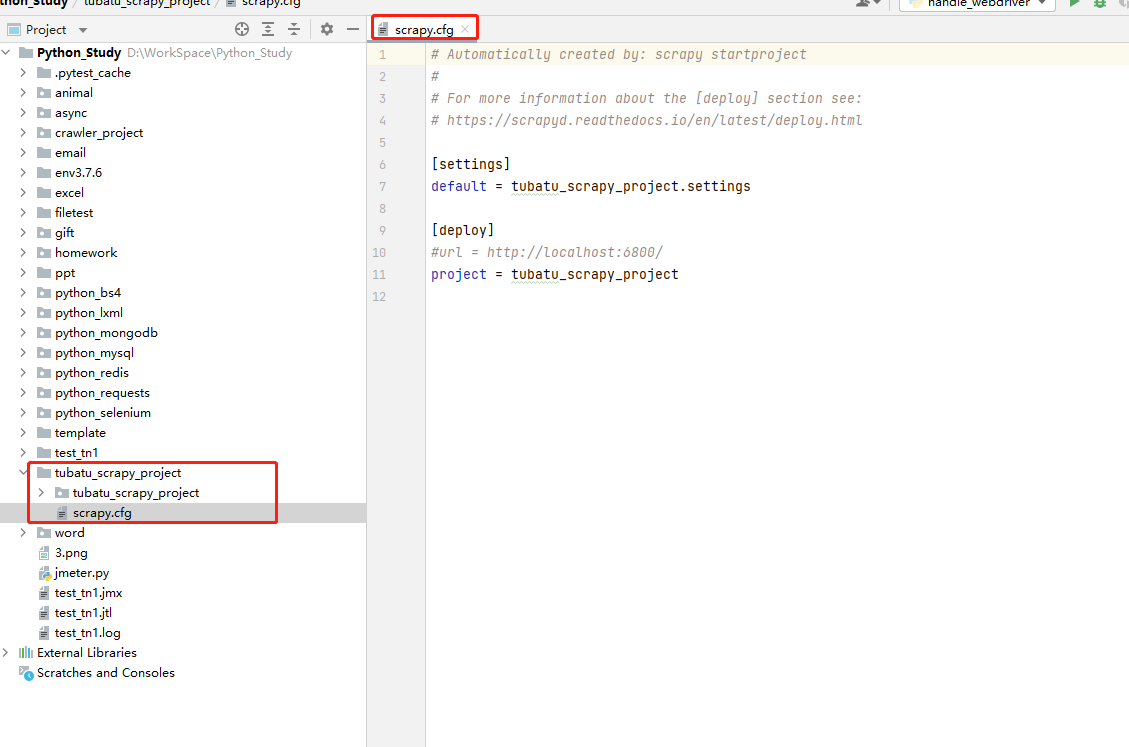
scrapy.cfg:项目的配置文件,定义了项目配置文件的路径等配置信息
- 【settings】:定义了项目的配置文件的路径,即./tubatu_scrapy_project/settings文件
- 【deploy】:部署信息
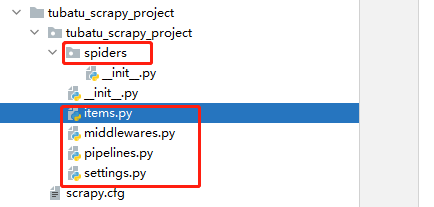
- items.py:就是我们定义item数据结构的地方;也就是说我们想要抓取哪些字段,所有的item定义都可以放到这个文件中
- pipelines.py:项目的管道文件,就是我们说的数据处理管道文件;用于编写数据存储,清洗等逻辑,比如将数据存储到json文件,就可以在这边编写逻辑
- settings.py:项目的设置文件,可以定义项目的全局设置,比如设置爬虫的 USER_AGENT ,就可以在这里设置;常用配置项如下:
- ROBOTSTXT_OBEY :是否遵循ROBTS协议,一般设置为False
- CONCURRENT_REQUESTS :并发量,默认是32个并发
- COOKIES_ENABLED :是否启用cookies,默认是False
- DOWNLOAD_DELAY :下载延迟
- DEFAULT_REQUEST_HEADERS :默认请求头
- SPIDER_MIDDLEWARES :是否启用spider中间件
- DOWNLOADER_MIDDLEWARES :是否启用downloader中间件
- 其他详见链接
- spiders目录:包含每个爬虫的实现,我们的解析规则写在这个目录下,即爬虫的解析器写在这个目录下
- middlewares.py:定义了 SpiderMiddleware和DownloaderMiddleware 中间件的规则;自定义请求、自定义其他数据处理方式、代理访问等
自动生成spiders模板文件
cd到spiders目录下,输出如下命令,生成爬虫文件:
scrapy genspider 文件名 爬取的地址

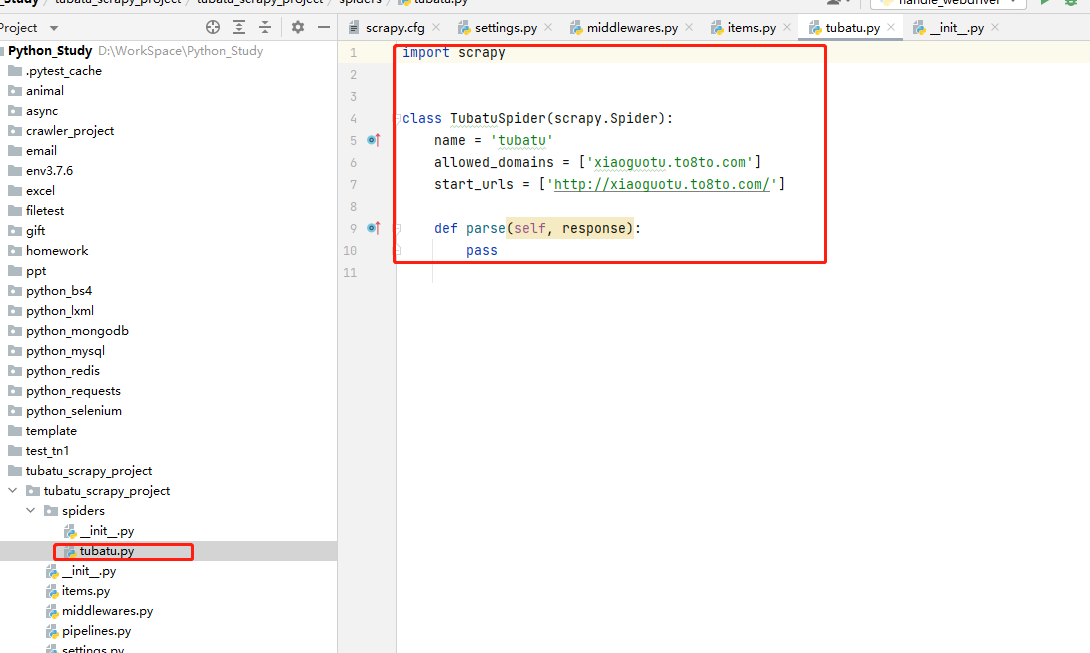
运行爬虫
方式一:cmd启动
cd到spiders目录下,执行如下命令,启动爬虫:
scrapy crawl 爬虫名
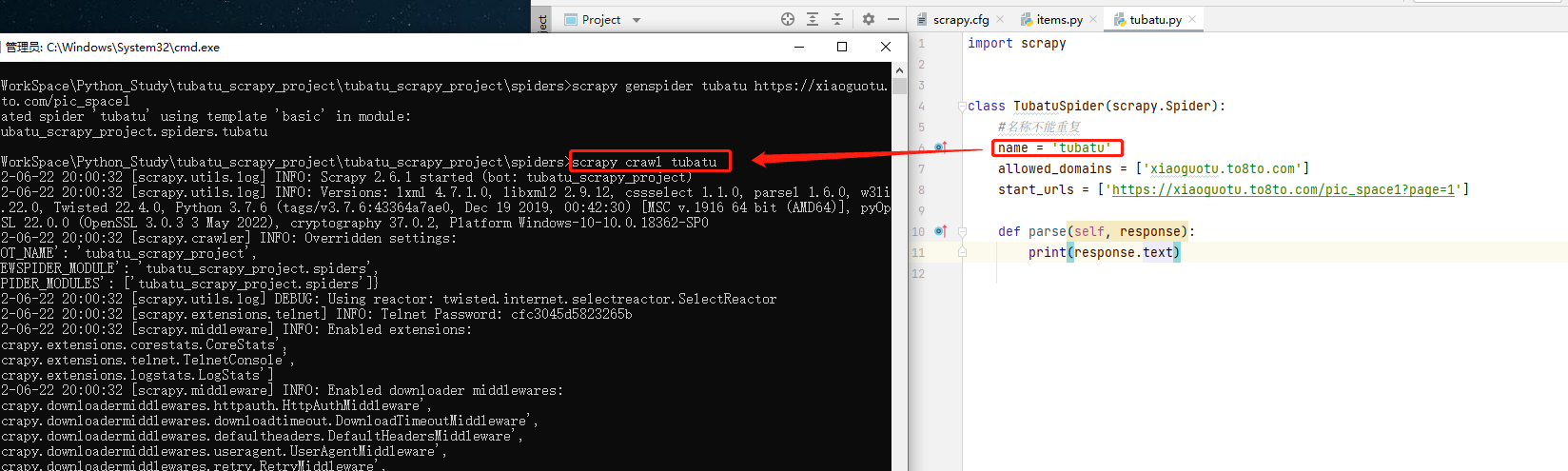
方式二:py文件启动
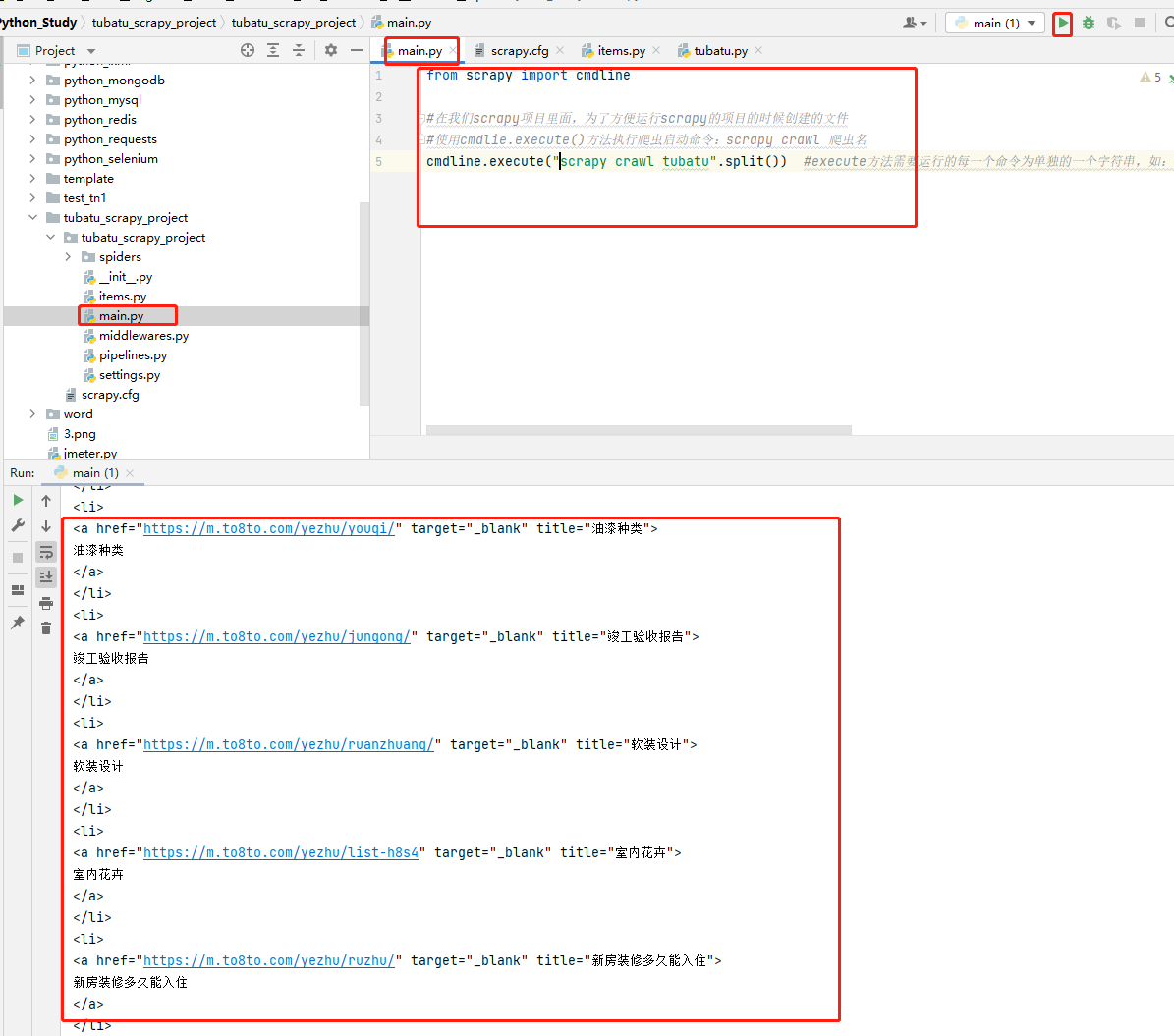
在项目下创建main.py文件,创建启动脚本,执行main.py启动文件,代码示例如下:
code-爬虫文件
import scrapy class TubatuSpider(scrapy.Spider):
#名称不能重复
name = 'tubatu'
#允许爬虫去抓取的域名
allowed_domains = ['xiaoguotu.to8to.com']
#项目启动之后要启动的爬虫文件
start_urls = ['https://xiaoguotu.to8to.com/pic_space1?page=1'] #默认的解析方法
def parse(self, response):
print(response.text)
code-启动文件
from scrapy import cmdline #在我们scrapy项目里面,为了方便运行scrapy的项目的时候创建的文件
#使用cmdlie.execute()方法执行爬虫启动命令:scrapy crawl 爬虫名
cmdline.execute("scrapy crawl tubatu".split()) #execute方法需要运行的每一个命令为单独的一个字符串,如:cmdline.execute(['scrapy', 'crawl', 'tubatu']),所以如果命令为一整个字符串时,需要split( )进行分割;#
code-运行结果
示例项目
爬取土巴兔装修网站信息。将爬取到的数据存入到本地MongoDB数据库中;
下图为项目机构,标蓝的文件就是此次code的代码
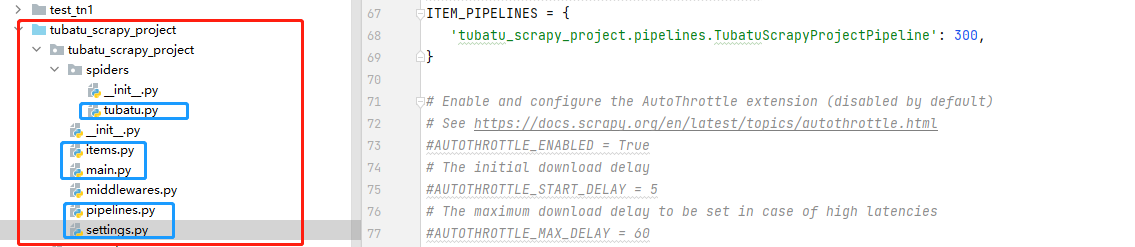
tubatu.py
1 import scrapy
2 from tubatu_scrapy_project.items import TubatuScrapyProjectItem
3 import re
4
5 class TubatuSpider(scrapy.Spider):
6
7 #名称不能重复
8 name = 'tubatu'
9 #允许爬虫去抓取的域名,超过这个目录就不允许抓取
10 allowed_domains = ['xiaoguotu.to8to.com','wx.to8to.com','sz.to8to.com']
11 #项目启动之后要启动的爬虫文件
12 start_urls = ['https://xiaoguotu.to8to.com/pic_space1?page=1']
13
14
15 #默认的解析方法
16 def parse(self, response):
17 # response后面可以直接使用xpath方法
18 # response就是一个Html对象
19 pic_item_list = response.xpath("//div[@class='item']")
20 for item in pic_item_list[1:]:
21 info = {}
22 # 这里有一个点不要丢了,是说明在当前Item下面再次使用xpath
23 # 返回的不仅仅是xpath定位中的text()内容,需要再过滤;返回如:[<Selector xpath='.//div/a/text()' data='0元搞定设计方案,限名额领取'>] <class 'scrapy.selector.unified.SelectorList'>
24 # content_name = item.xpath('.//div/a/text()')
25
26 #使用extract()方法获取item返回的data信息,返回的是列表
27 # content_name = item.xpath('.//div/a/text()').extract()
28
29 #使用extract_first()方法获取名称,数据;返回的是str类型
30 #获取项目的名称,项目的数据
31 info['content_name'] = item.xpath(".//a[@target='_blank']/@data-content_title").extract_first()
32
33 #获取项目的URL
34 info['content_url'] = "https:"+ item.xpath(".//a[@target='_blank']/@href").extract_first()
35
36 #项目id
37 content_id_search = re.compile(r"(\d+)\.html")
38 info['content_id'] = str(content_id_search.search(info['content_url']).group(1))
39
40 #使用yield来发送异步请求,使用的是scrapy.Request()方法进行发送,这个方法可以传cookie等,可以进到这个方法里面查看
41 #回调函数callback,只写方法名称,不要调用方法
42 yield scrapy.Request(url=info['content_url'],callback=self.handle_pic_parse,meta=info)
43
44 if response.xpath("//a[@id='nextpageid']"):
45 now_page = int(response.xpath("//div[@class='pages']/strong/text()").extract_first())
46 next_page_url="https://xiaoguotu.to8to.com/pic_space1?page=%d" %(now_page+1)
47 yield scrapy.Request(url=next_page_url,callback=self.parse)
48
49
50 def handle_pic_parse(self,response):
51 tu_batu_info = TubatuScrapyProjectItem()
52 #图片的地址
53 tu_batu_info["pic_url"]=response.xpath("//div[@class='img_div_tag']/img/@src").extract_first()
54 #昵称
55 tu_batu_info["nick_name"]=response.xpath("//p/i[@id='nick']/text()").extract_first()
56 #图片的名称
57 tu_batu_info["pic_name"]=response.xpath("//div[@class='pic_author']/h1/text()").extract_first()
58 #项目的名称
59 tu_batu_info["content_name"]=response.request.meta['content_name']
60 # 项目id
61 tu_batu_info["content_id"]=response.request.meta['content_id']
62 #项目的URL
63 tu_batu_info["content_url"]=response.request.meta['content_url']
64 #yield到piplines,我们通过settings.py里面启用,如果不启用,将无法使用
65 yield tu_batu_info
items.py
1 # Define here the models for your scraped items
2 #
3 # See documentation in:
4 # https://docs.scrapy.org/en/latest/topics/items.html
5
6 import scrapy
7
8
9 class TubatuScrapyProjectItem(scrapy.Item):
10 # define the fields for your item here like:
11 # name = scrapy.Field()
12
13 #装修名称
14 content_name=scrapy.Field()
15 #装修id
16 content_id = scrapy.Field()
17 #请求url
18 content_url=scrapy.Field()
19 #昵称
20 nick_name=scrapy.Field()
21 #图片的url
22 pic_url=scrapy.Field()
23 #图片的名称
24 pic_name=scrapy.Field()
piplines.py
1 # Define your item pipelines here
2 #
3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting
4 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
5
6
7 # useful for handling different item types with a single interface
8 from itemadapter import ItemAdapter
9
10 from pymongo import MongoClient
11
12 class TubatuScrapyProjectPipeline:
13
14 def __init__(self):
15 client = MongoClient(host="localhost",
16 port=27017,
17 username="admin",
18 password="123456")
19 mydb=client['db_tubatu']
20 self.mycollection = mydb['collection_tubatu']
21
22 def process_item(self, item, spider):
23 data = dict(item)
24 self.mycollection.insert_one(data)
25 return item
settings.py

main.py
1 from scrapy import cmdline
2
3 #在我们scrapy项目里面,为了方便运行scrapy的项目的时候创建的文件
4 #使用cmdlie.execute()方法执行爬虫启动命令:scrapy crawl 爬虫名
5 cmdline.execute("scrapy crawl tubatu".split()) #execute方法需要运行的每一个命令为单独的一个字符串,如:cmdline.execute(['scrapy', 'crawl', 'tubatu']),所以如果命令为一整个字符串时,需要split( )进行分割;#
爬虫(9) - Scrapy框架(1) | Scrapy 异步网络爬虫框架的更多相关文章
- greenev —— Python 异步网络服务框架
greenev是一个基于greenlet协程,事件驱动,非阻塞socket模型的Python网络服务框架,它使得可以编写同步的代码,却得到异步执行的优点. 本项目受到gevent, openresty ...
- Android之封装好的异步网络请求框架
1.简介 Android中网络请求一般使用Apache HTTP Client或者采用HttpURLConnection,但是直接使用这两个类库需要写大量的代码才能完成网络post和get请求,而使 ...
- Linux企业级项目实践之网络爬虫(3)——设计自己的网络爬虫
网络抓取系统分为核心和扩展组件两部分.核心部分是一个精简的.模块化的爬虫实现,而扩展部分则包括一些便利的.实用性的功能.目标是尽量的模块化,并体现爬虫的功能特点.这部分提供简单.灵活的API,在基本不 ...
- 深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.contrib.rnn.MultiRNNCell(堆叠多层LSTM) 4.mlstm_cell.zero_state(state初始化) 5.mlstm_cell(进行LSTM求解)
问题:LSTM的输出值output和state是否是一样的 1. rnn.LSTMCell(num_hidden, reuse=tf.get_variable_scope().reuse) # 构建 ...
- Scrapy (网络爬虫框架)入门
一.Scrapy 简介: Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado) ...
- 网络爬虫值scrapy框架基础
简介 Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv.json等文件中. 首先我们安装Scrapy. 其可以应用在数据挖掘,信息处理或存储历史 ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- Scrapy 轻松定制网络爬虫(转)
网络爬虫(Web Crawler, Spider)就是一个在网络上乱爬的机器人.当然它通常并不是一个实体的机器人,因为网络本身也是虚拟的东西,所以这个“机器人”其实也就是一段程序,并且它也不是乱爬,而 ...
随机推荐
- jstl操作session
1.jstl操作session(添加.删除session中的值)
- postman4.15
测开培训笔记4.15 postman:很主流的API测试工具,也是在工作中使用很广泛的研发工具 queue 队列 先进先出的原则 列如:客户端有100个请求 服务端最多只能承受90个 其余都要排队进行 ...
- stm32F103RCT6使用FFT运算分析波形详解(非常新手)
最近学校电赛院队招新,出的招新题就是低频示波器的.之前一直没有弄懂FFT,借着这次机会实现了一下. FFT原理详解 FFT,就是快速傅里叶变换,这个操作能够将时域信号转化成频域信号,然后对信号进行分析 ...
- Mac 系统用mx master3遇到的问题
买 master3 之前上网看到的资料都是夸的不行,提到的问题也都是无足轻重,然而就我个人来说,在 Mac 下实际使用 master3 的感受很糟糕,写这篇文章分享一下遇到的问题,如果有想买的人看到这 ...
- 以rem为单位,数值较小,border-radius:50%部分浏览器渲染不圆方法
元素使用rem做单位且较小时,对于border-radius:50%在部分浏览器不圆解决方法: 1.将原来宽高扩大至两倍(.1rem --> .2rem),再使用transform:scale( ...
- Django学习——ajax发送其他请求、上传文件(ajax和form两种方式)、ajax上传json格式、 Django内置序列化(了解)、分页器的使用
1 ajax发送其他请求 1 写在form表单 submit和button会触发提交 <form action=""> </form> 注释 2 使用inp ...
- 使用client-go实现自定义控制器
使用client-go实现自定义控制器 介绍 我们已经知道,Service对集群之外暴露服务的主要方式有两种:NodePort和LoadBalancer,但是这两种方式,都有一定的缺点: NodePo ...
- 记一次百万行WPF项目代码的重构记录
此前带领小组成员主导过一个百万行代码上位机项目的重构工作,分析项目中存在的问题做了些针对性的优化,整个重构工作持续了一年半之久. 主要针对以下问题: 1.产品型号太多导致代码工程的分支太多,维护时会产 ...
- hive从入门到放弃(六)——常用文件存储格式
hive 存储格式有很多,但常用的一般是 TextFile.ORC.Parquet 格式,在我们单位最多的也是这三种 hive 默认的文件存储格式是 TextFile. 除 TextFile 外的其他 ...
- 好客租房17-jsx的样式处理
1行内样式-style <h1 style={{color:"red",backgroundColor:"skyblue"}}> jsx的样式处理 ...