使用 LOAD DATA LOCAL INFILE,sysbench 导数速度提升30%
最近给 sysbench 提了一个 feature(https://github.com/akopytov/sysbench/pull/450),支持通过 LOAD DATA LOCAL INFILE 命令导入压测数据。
下面我们来具体看看这个 feature 的使用方法和实现细节。
下载安装
下载支持 LOAD DATA LOCAL INFILE 命令的 sysbench 分支。
# yum -y install make automake libtool pkgconfig libaio-devel openssl-devel mysql-devel
# cd /usr/src/
# git clone https://github.com/slowtech/sysbench.git --branch feature-load-data
# cd sysbench/
# ./autogen.sh
# ./configure
# make -j
# make install
安装完成后,压测脚本默认会安装在 /usr/local/share/sysbench 目录下。
我们看看该目录的内容。
# ls /usr/local/share/sysbench/
bulk_insert.lua oltp_delete.lua oltp_point_select.lua oltp_read_write.lua oltp_update_non_index.lua select_random_points.lua tests
oltp_common.lua oltp_insert.lua oltp_read_only.lua oltp_update_index.lua oltp_write_only.lua select_random_ranges.lua
除了oltp_common.lua是个公共模块,其它每个lua脚本都对应一个测试场景。
使用方法
使用方法和 master 分支基本一致,主要是在 prepare 阶段新增了两个参数。
下面,我们看看 sysbench 压测 MySQL 的四个标准步骤:
1. prepare
生成压测数据。
sysbench oltp_read_write --mysql-host=10.0.20.4 --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-db=sbtest --tables=10 --table-size=1000000 --threads=10 --fast --csv-dir=/data/sysbench prepare
其中,
--tables :表的数量,默认是1。
--table-size :单表的大小,默认是10000。
--threads :并发线程数,默认是1。注意,导入时,单表只能使用一个线程。
oltp_read_write:脚本名。对应的是/usr/local/share/sysbench/oltp_read_write.lua。
这里也可指定脚本的绝对路径。
除此之外,这里还指定了新增的两个参数:
--fast:通过 LOAD DATA LOCAL INFILE 命令导入数据。不指定,则默认是使用 INSERT 命令导入数据。
--csv-dir:CSV 文件的存储路径。不指定,则默认是 /tmp。
如果使用的是 MySQL 8.0,在操作之前,需将 local_infile 设置为 ON,
否则,客户端在执行 LOAD DATA LOCAL INFILE 时会提示以下错误:
ERROR 3948 (42000): Loading local data is disabled; this must be enabled on both the client and server sides
在 MySQL 5.6,5.7 中无需修改,该参数默认为 OFF。
最后,再来说说测试场景。
oltp_read_write 用来压测 OLTP 场景。
在 sysbench 1.0 之前, 该场景是通过 oltp.lua 这个脚本来测试的。
不过该脚本在 sysbench 1.0 之后被废弃了,为了跟之前的版本兼容,该脚本放到了 /usr/local/share/sysbench/tests/include/oltp_legacy/ 目录下。
鉴于 oltp_read_write.lua 和 oltp.lua 两者的压测内容完全一致。
从 sysbench 1.0 开始,压测 OLTP 建议直接使用 oltp_read_write。
2. prewarm
预热。
主要是将磁盘中的数据加载到内存中。
sysbench oltp_read_write --mysql-host=10.0.20.4 --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-db=sbtest --tables=10 --table-size=1000000 --threads=10 prewarm
3. run
压测。
sysbench oltp_read_write --mysql-host=10.0.20.4 --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-db=sbtest --tables=10 --table-size=1000000 --threads=10 --time=600 --report-interval=10 run
其中,
- --time :压测时间,不指定,则默认是10s。
- --report-interval=10 :每10s输出一次压测结果,默认为0,不输出。
4. cleanup
清理数据。
sysbench oltp_read_write --mysql-host=10.0.20.4 --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-db=sbtest --tables=10 cleanup
这里只需指定 --tables ,sysbench 会串行执行 DROP TABLE IF EXISTS sbtest 操作。
导入速度对比
下面对比了不同 tables(表的数量),table_size(表的大小),threads (并发线程数)下,LOAD 和 INSERT 操作所需的时间。
每个配置都会测试三次,LOAD 和 INSERT 操作交叉执行。
测试过程中,设置了 --create_secondary=false,不会创建二级索引,所以这里衡量的只是导入时间。
测试实例是甲骨文云上的 MDS (MySQL Database Service)。
配置相当强悍:16 OCPU(OCPU 是物理 CPU 核数,对应的逻辑 CPU 是 32 核),512G 内存,高性能块存储。
在测试的过程中,为了减轻磁盘 IO 的影响,将 sync_binlog 调整为了0。
下面我们看看测试结果。
+--------+------------+---------+---------------+-----------------+-------------------------------+
| tables | table_size | threads | load_avg_time | insert_avg_time | load_avg_time/insert_avg_time |
+--------+------------+---------+---------------+-----------------+-------------------------------+
| 1 | 10000000 | 1 | 58.03 | 82.95 | 0.70 |
| 2 | 10000000 | 1 | 117.52 | 169.00 | 0.70 |
| 2 | 10000000 | 2 | 68.85 | 100.60 | 0.68 |
| 5 | 10000000 | 1 | 299.60 | 438.74 | 0.68 |
| 5 | 10000000 | 2 | 197.91 | 286.54 | 0.69 |
| 5 | 10000000 | 5 | 86.36 | 119.60 | 0.72 |
| 10 | 10000000 | 1 | 605.15 | 881.70 | 0.69 |
| 10 | 10000000 | 2 | 364.71 | 521.02 | 0.70 |
| 10 | 10000000 | 5 | 175.49 | 247.98 | 0.71 |
| 10 | 10000000 | 10 | 111.43 | 162.84 | 0.68 |
| 20 | 10000000 | 1 | 1242.61 | 1775.17 | 0.70 |
| 20 | 10000000 | 2 | 755.31 | 1034.03 | 0.73 |
| 20 | 10000000 | 5 | 357.45 | 520.80 | 0.69 |
| 20 | 10000000 | 10 | 228.05 | 333.27 | 0.68 |
| 20 | 10000000 | 20 | 194.97 | 299.55 | 0.65 |
| 30 | 10000000 | 1 | 1901.68 | 2826.83 | 0.67 |
| 30 | 10000000 | 2 | 1134.81 | 1574.98 | 0.72 |
| 30 | 10000000 | 5 | 542.96 | 771.31 | 0.70 |
| 30 | 10000000 | 10 | 347.53 | 515.04 | 0.67 |
| 30 | 10000000 | 20 | 302.60 | 475.71 | 0.64 |
| 30 | 10000000 | 30 | 320.94 | 453.42 | 0.71 |
+--------+------------+---------+---------------+-----------------+-------------------------------+
结果中,
load_avg_time 是 LOAD 命令的平均执行时间。
insert_avg_time 是 INSERT 命令的平均执行时间。
最后一列是两者的比值。
可以看到,相同配置下,LOAD 命令的平均执行时间只有 INSERT 的 70% 。
下面,我们看看 tables = 30, table_size = 10000000 时,命令的执行时间与并发线程数之间的关系。
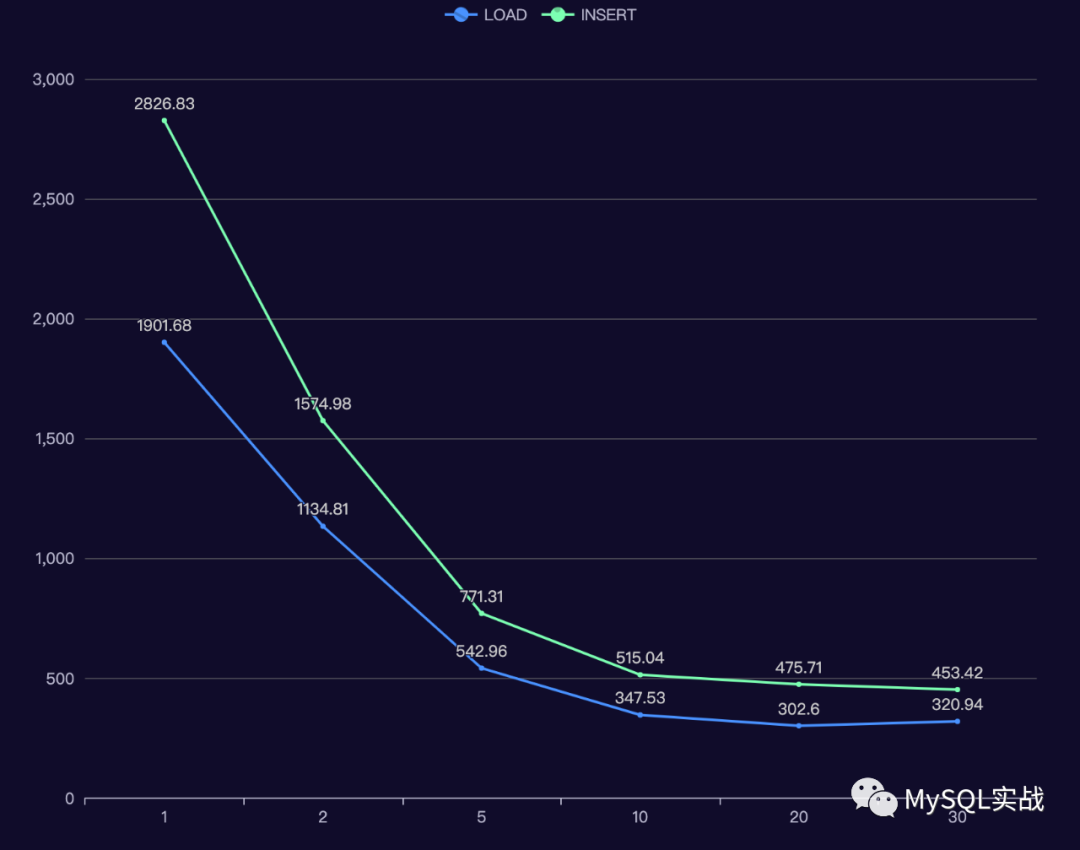
可以看到,
并发数小于等于 5 时,随着并发线程数的增加,导入时间基本上是同比例下降。
当并发数超过 10 时,增加并发数带来的收益并不明显,甚至,LOAD 命令在 30 线程下的导入时间比 20 线程还高。
实现细节
主要修改了两个文件:
oltp_common.lua
lua 脚本的公共模块文件,位于源码包的 src/lua 目录下。
prepare的处理逻辑就是在这个文件中定义的。
我们直接看看新增代码的逻辑。
local f
-- 如果命令行中指定了 --fast,则打开一个文件。
if (sysbench.opt.fast) then
f = assert(io.open(string.format("/%s/sbtest%d",sysbench.opt.csv_dir,table_num),'w'))
end for i = 1, sysbench.opt.table_size do c_val = get_c_value()
pad_val = get_pad_value() if (sysbench.opt.auto_inc) then
if (sysbench.opt.fast) then
-- 构造字符串,字段与字段之间用逗号隔开,\n是换行符。
query = string.format("%d,%s,%s\n",
sysbench.rand.default(1, sysbench.opt.table_size),
c_val, pad_val)
else
query = string.format("(%d, '%s', '%s')",
sysbench.rand.default(1, sysbench.opt.table_size),
c_val, pad_val) end
else
if (sysbench.opt.fast) then
query = string.format("%d,%d,%s,%s\n",
i,
sysbench.rand.default(1, sysbench.opt.table_size),
c_val, pad_val)
else
query = string.format("(%d, %d, '%s', '%s')",
i,
sysbench.rand.default(1, sysbench.opt.table_size),
c_val, pad_val)
end
end
-- 将构造的字符串写入到文件中
if (sysbench.opt.fast) then
f:write(query)
else
con:bulk_insert_next(query)
end end if (sysbench.opt.fast) then f:close()
local column_name
if (sysbench.opt.auto_inc) then
column_name="k, c, pad"
else
column_name="id, k, c, pad"
end
-- 通过 LOAD DATA LOCAL INFILE 命令导入数据
query = string.format("LOAD DATA LOCAL INFILE '/%s/sbtest%d' " ..
"INTO TABLE sbtest%d FIELDS TERMINATED BY ',' LINES TERMINATED BY '\\n' " ..
"(%s)", sysbench.opt.csv_dir,table_num,table_num,column_name)
-- 为了提升导入速度,这里在会话级别禁用了 unique_checks 和 foreign_key_checks
con:query("SET unique_checks = 0")
con:query("SET foreign_key_checks = 0")
con:query(query)
else
con:bulk_insert_done()
end
drv_mysql.c
MySQL 驱动文件,位于源码包的 src/drivers/mysql 目录下。
在 MySQL 8.0 中,即使将服务端的 local_infile 设置为 ON,通过 mysql 客户端执行 LOAD DATA LOCAL INFILE 时,还是会报错。
mysql> LOAD DATA LOCAL INFILE '/data/sysbench/sbtest1' INTO TABLE sbtest1 FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' (k, c, pad);
ERROR 2068 (HY000): LOAD DATA LOCAL INFILE file request rejected due to restrictions on access.
解决方法:
将 mysql 客户端的 local-infile 设置为 ON。
# mysql --local-infile=on
但在 sysbench 的 MySQL 驱动文件中,却没有这个选项。
好在 sysbench 使用的也是 C API,我们可以直接通过 mysql_options() 函数开启MYSQL_OPT_LOCAL_INFILE。
if (args.use_local_infile)
{
DEBUG("mysql_options(%p, %s, %d)",con, "MYSQL_OPT_LOCAL_INFILE", args.use_local_infile);
mysql_options(con, MYSQL_OPT_LOCAL_INFILE, &args.use_local_infile);
}
为什么 LOAD DATA INFILE 快?
LOAD DATA INFILE 之所以比 INSERT 快,主要原因有以下几点:
无需解析 SQL 语句。
一次会读取多个数据块。
对于空表,操作期间会禁用所有非唯一索引。
存储引擎会先缓存一些数据,达到一定数量后才批量插入( MyISAM 和 Aria 存储引擎支持该行为)。
对于空表,某些事务引擎(如 Aria)不会在事务日志中记录插入的数据。
为什么不用记录呢?因为如果需要回滚,只需执行 TRUNCATE 操作即可。
这里说的 Aria 是 MariaDB 中的一个存储引擎,主要用来替代 MyISAM 存储引擎。
总结
相同配置下,LOAD 命令的平均执行时间只有 INSERT 的 70% 。
tables 和 table_size 一定时,在一定范围内,增加线程数能显著降低导入时间。
在实际工作中,如果要导入的 CSV 文件很大,建议使用 MySQL Shell 中的 util.importTable。
该命令在底层实现上使用的也是 LOAD DATA LOCAL INFILE,只不过它会将单个文件切割成多个 chunk 并行导入。
相对来说,导入速度更快,也不会产生大事务。
参考资料
How to Quickly Insert Data Into MariaDB
使用 LOAD DATA LOCAL INFILE,sysbench 导数速度提升30%的更多相关文章
- [MySQL]load data local infile向MySQL数据库中导入数据时,无法导入和字段不分离问题。
利用load data将文件中的数据导入数据库表中的时候,遇到了两个问题. 首先是load data命令无法执行的问题: 命令行下输入load data local infile "path ...
- Load data local infile 实验报告
1.实验内容: 利用SQL语句“load data local infile”将“pet.txt”文本文件中的数据导入到mysql中 (pet表在数据库menagerie中) 2.实验过程及结果: ( ...
- MySQL使用LOAD DATA LOCAL INFILE报错
在windows系统的MySQL8.0中尝试执行以下语句时报错 mysql> LOAD DATA LOCAL INFILE '/path/filename' INTO TABLE tablena ...
- 浅谈MySQL load data local infile细节 -- 从源码层面
相信大伙对mysql的load data local infile并不陌生,今天来巩固一下这里面隐藏的一些细节,对于想自己动手开发一个mysql客户端有哪些点需要注意的呢? 首先,了解一下流程: 3个 ...
- MySQL用Load Data local infile 导入部分数据后中文乱码
今天在两台MySQL服务器之间导数据,因为另一个MySQL服务器是测试用的,差一个月的数据,从现有MySQL服务器select到一个文件,具体语句是: select * from news where ...
- Java不写文件,LOAD DATA LOCAL INFILE大批量导入数据到MySQL的实现(转)
MySQL使用load data local infile 从文件中导入数据比insert语句要快,MySQL文档上说要快20倍左右.但是这个方法有个缺点,就是导入数据之前,必须要有文件,也就是说从文 ...
- load data local infile
发财 基本语法:load data [low_priority] [local] infile '文件名称' [replace替换策略 | ignore忽略策略]into table 表名称[fiel ...
- JDBC使用MYSQL的LOAD DATA LOACAL INFILE和LOAD DATA INFILE
MYSQL的LOAD方法都必须建立在mysql服务允许使用该命令的情况下: 开启该命令的方法: 1.在实例对应的my.cnf(windows为my.ini)中添加一行local-infile=1(默认 ...
- Mybatis拦截器 mysql load data local 内存流处理
Mybatis 拦截器不做解释了,用过的基本都知道,这里用load data local主要是应对大批量数据的处理,提高性能,也支持事务回滚,且不影响其他的DML操作,当然这个操作不要涉及到当前所lo ...
随机推荐
- git使用命令行保留原分支迁移代码仓库
有些时候我们需要对git仓库中的项目进行一些迁移,如从a账号迁移到b账号下,从github平台迁移到内部的gitlab平台等.一般平台会自带 migrate 或者 import 的功能,可以很方便的进 ...
- 空间插值生物X适宜性分析
1 前言 这期博主将根据示例大概讲一下插值分析. 2 问题阐述 根据要求,完成以下操作: (1)请就以上条件确定此地区适合X的生活范围,并制作专题图.专题图内容要求以地形和水系作为背景,且给出适宜区域 ...
- 超详细GoodSync11.2.7.8单机、两个服务器之间的文件同步使用教程
GoodSync安装教程 第一步:双机GoodSync_v11.2.7.8.exe文件 链接:https://pan.baidu.com/s/16FVater4f9vu07QiGGIK9A 提取码:b ...
- Superset安装部署操作
目录 1.安装Miniconda 1.下载Miniconda 2.安装 3.开启一个新的shell窗口 4.设置新窗口不自动开启conda 2.创建Python3.7环境 1.配置国内镜像 2.常用命 ...
- SpringMVC解决前端传来的中文字符乱码问题
以前乱码问题通过过滤器解决,而SpringMVC给我们提供了一个过滤器,可以在web.xml中添加以下配置 修改了xml文件需要重启服务器! <!--配置解决中文乱码过滤器--> < ...
- Github使用指南(学习中随时更新)
注册好一个账号后先创建一个仓库 点击"Create repository"创建一个版本库 填好带*号的必填项,选择是要公开仓库还是私人使用,勾选自动添加README选项 READM ...
- docker知识点扫盲
最近给部门同事培训docker相关的东西,把我的培训内容总结下,发到博客园上,和大家一起分享.我的培训思路是这样的 首先讲解docker的安装.然后讲下docker的基本的原理,最后讲下docker的 ...
- java线程池源码分析
我们在关闭线程池的时候会使用shutdown()和shutdownNow(),那么问题来了: 这两个方法又什么区别呢? 他们背后的原理是什么呢? 线程池中线程超过了coresize后会怎么操作呢? 为 ...
- django模板之forloop
在django的模板中,有forloop这一模板变量,颇似php Smarty中的foreach.customers, Smarty foreach如下: {foreach name=customer ...
- 使用 Spring 通过什么方式访问 Hibernate?
在 Spring 中有两种方式访问 Hibernate:控制反转 Hibernate Template 和 Callback.继承 HibernateDAOSupport 提供一个 AOP 拦截器.