一文详解RocketMQ的存储模型
摘要:RocketMQ 优异的性能表现,必然绕不开其优秀的存储模型。
本文分享自华为云社区《终于弄明白了 RocketMQ 的存储模型》,作者:勇哥java实战分享。
RocketMQ 优异的性能表现,必然绕不开其优秀的存储模型 。
1 整体概览
首先温习下 RocketMQ 架构。
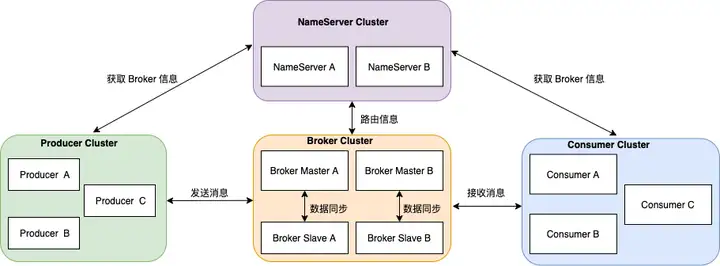
整体架构中包含四种角色 :
- Producer :消息发布的角色,Producer 通过 MQ 的负载均衡模块选择相应的 Broker 集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
- Consumer :消息消费的角色,支持以 push 推,pull 拉两种模式对消息进行消费。
- NameServer :名字服务是一个非常简单的 Topic 路由注册中心,其角色类似 Dubbo 中的 zookeeper ,支持 Broker 的动态注册与发现。
- BrokerServer :Broker 主要负责消息的存储、投递和查询以及服务高可用保证 。
本文的重点在于分析 BrokerServer 的消息存储模型。我们先进入 broker 的文件存储目录 。

消息存储和下面三个文件关系非常紧密:
1.数据文件 commitlog
消息主体以及元数据的存储主体 ;
2.消费文件 consumequeue
消息消费队列,引入的目的主要是提高消息消费的性能 ;
3.索引文件 index
索引文件,提供了一种可以通过 key 或时间区间来查询消息。
RocketMQ 采用的是混合型的存储结构,Broker 单个实例下所有的队列共用一个数据文件(commitlog)来存储。
生产者发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 commitlog 文件中。只要消息被刷盘持久化至磁盘文件 commitlog 中,那么生产者发送的消息就不会丢失。
Broker 端的后台服务线程会不停地分发请求并异步构建 consumequeue(消费文件)和 indexFile(索引文件)。
2 数据文件
RocketMQ 的消息数据都会写入到数据文件中, 我们称之为 commitlog 。
所有的消息都会顺序写入数据文件,当文件写满了,会写入下一个文件。

如上图所示,单个文件大小默认 1G , 文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表了第一个文件,起始偏移量为 0 ,文件大小为1 G = 1073741824。
当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。
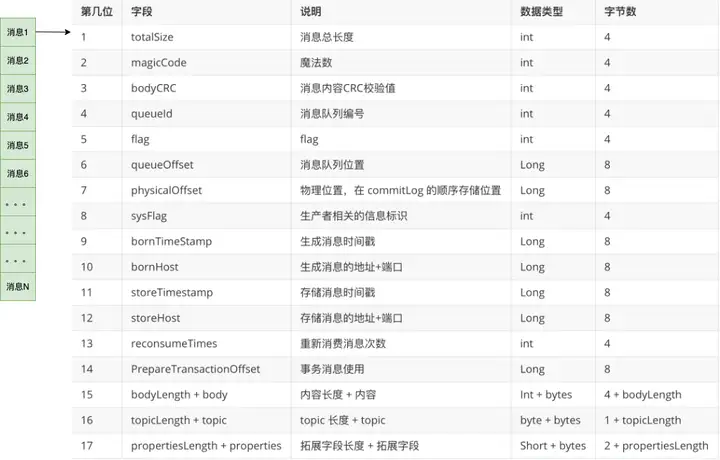
从上图中,我们可以看到消息是一条一条写入到文件,每条消息的格式是固定的。
这样设计有三点优势:
1、顺序写
磁盘的存取速度相对内存来讲并不快,一次磁盘 IO 的耗时主要取决于:寻道时间和盘片旋转时间,提高磁盘 IO 性能最有效的方法就是:减少随机 IO,增加顺序 IO 。
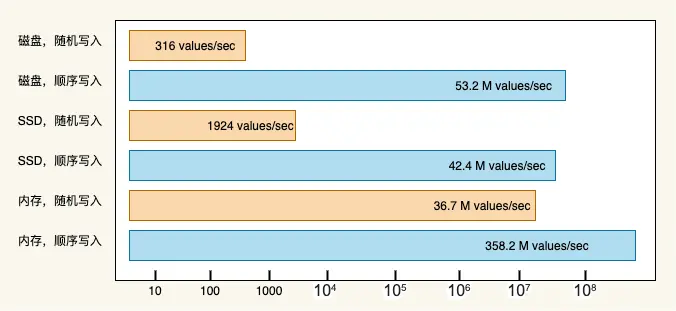
《 The Pathologies of Big Data 》这篇文章指出:内存随机读写的速度远远低于磁盘顺序读写的速度。磁盘顺序写入速度可以达到几百兆/s,而随机写入速度只有几百 KB /s,相差上千倍。
2、快速定位
因为消息是一条一条写入到 commitlog 文件 ,写入完成后,我们可以得到这条消息的物理偏移量。
每条消息的物理偏移量是唯一的, commitlog 文件名是递增的,可以根据消息的物理偏移量通过二分查找,定位消息位于那个文件中,并获取到消息实体数据。
3、通过消息 offsetMsgId 查询消息数据
消息 offsetMsgId 是由 Broker 服务端在写入消息时生成的 ,该消息包含两个部分:
- Broker 服务端 ip + port 8个字节;
- commitlog 物理偏移量 8个字节 。
我们可以通过消息 offsetMsgId ,定位到 Broker 的 ip 地址 + 端口 ,传递物理偏移量参数 ,即可定位该消息实体数据。
3 消费文件
在介绍 consumequeue 文件之前, 我们先温习下消息队列的传输模型-发布订阅模型 , 这也是 RocketMQ 当前的传输模型。
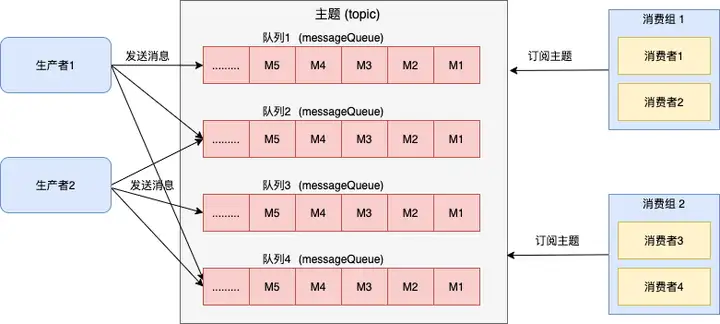
发布订阅模型具有如下特点:
- 消费独立:相比队列模型的匿名消费方式,发布订阅模型中消费方都会具备的身份,一般叫做订阅组(订阅关系),不同订阅组之间相互独立不会相互影响。
- 一对多通信:基于独立身份的设计,同一个主题内的消息可以被多个订阅组处理,每个订阅组都可以拿到全量消息。因此发布订阅模型可以实现一对多通信。
因此,rocketmq 的文件设计必须满足发布订阅模型的需求。
那么仅仅 commitlog 文件是否可以满足需求吗 ?
假如有一个 consumerGroup 消费者,订阅主题 my-mac-topic ,因为 commitlog 包含所有的消息数据,查询该主题下的消息数据,需要遍历数据文件 commitlog , 这样的效率是极其低下的。
进入 rocketmq 存储目录,显示见下图:
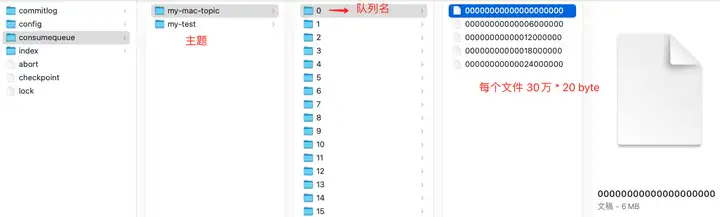
- 消费文件按照主题存储,每个主题下有不同的队列,图中 my-mac-topic 有 16 个队列 ;
- 每个队列目录下 ,存储 consumequeue 文件,每个 consumequeue 文件也是顺序写入,数据格式见下图。
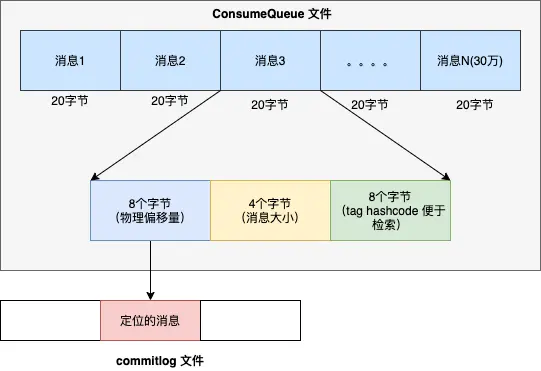
每个 consumequeue 包含 30 万个条目,每个条目大小是 20 个字节,每个文件的大小是 30 万 * 20 = 60万字节,每个文件大小约5.72M 。和 commitlog 文件类似,consumequeue 文件的名称也是以偏移量来命名的,可以通过消息的逻辑偏移量定位消息位于哪一个文件里。
消费文件按照主题-队列来保存 ,这种方式特别适配发布订阅模型。
消费者从 broker 获取订阅消息数据时,不用遍历整个 commitlog 文件,只需要根据逻辑偏移量从 consumequeue 文件查询消息偏移量 , 最后通过定位到 commitlog 文件, 获取真正的消息数据。
这样就可以简化消费查询逻辑,同时因为同一主题下,消费者可以订阅不同的队列或者 tag ,同时提高了系统的可扩展性。
4 索引文件
每个消息在业务层面的唯一标识码要设置到 keys 字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过 topic、key 来查询这条消息内容,以及消息被谁消费。
由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。
//订单Id
String orderId = "1234567890";
message.setKeys(orderId);
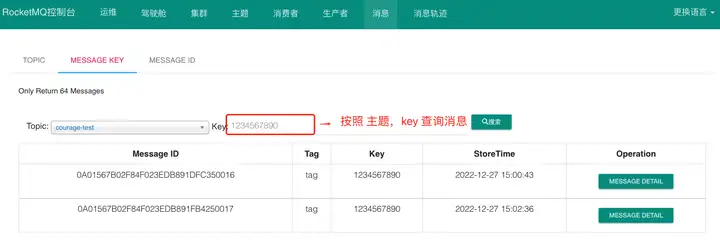
从开源的控制台中根据主题和 key 查询消息列表:
进入索引文件目录 ,如下图所以:
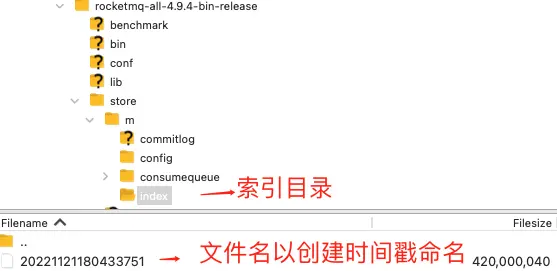
索引文件名 fileName 是以创建时的时间戳命名的,固定的单个 IndexFile 文件大小约为 400 M 。
IndexFile 的文件逻辑结构类似于 JDK 的 HashMap 的数组加链表结构。
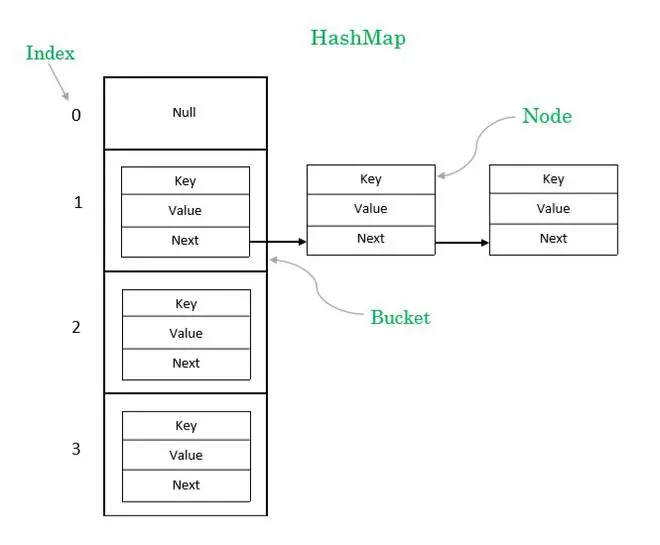
索引文件主要由 Header、Slot Table (默认 500 万个条目)、Index Linked List(默认最多包含 2000万个条目)三部分组成 。
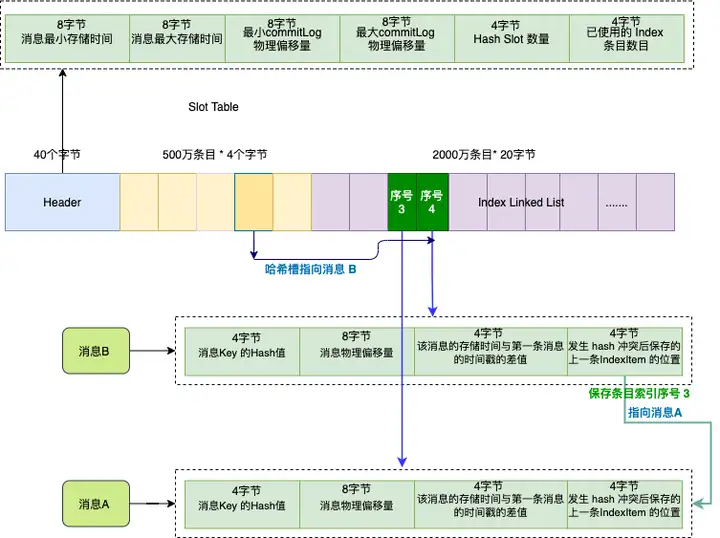
假如订单系统发送两条消息 A 和 B , 他们的 key 都是 “1234567890” ,我们依次存储消息 A , 消息 B 。
因为这两个消息的 key 的 hash 值相同,它们对应的哈希槽(深黄色)也会相同,哈希槽会保存的最新的消息 B 的索引条目序号 , 序号值是 4 ,也就是第二个深绿色条目。
而消息 B 的索引条目信息的最后 4 个字节会保存上一条消息对应的索引条目序号,索引序号值是 3 , 也就是消息 A 。
5 写到最后
Databases are specializing – the “one size fits all” approach no longer applies ------ MongoDB设计哲学
RocketMQ 存储模型设计得非常精巧,笔者觉得每种设计都有其底层思考,这里总结了三点 :
- 完美适配消息队列发布订阅模型 ;
- 数据文件,消费文件,索引文件各司其职 ,同时以数据文件为核心,异步构建消费文件 + 索引文件这种模式非常容易扩展到主从复制的架构;
- 充分考虑业务的查询场景,支持消息 key ,消息 offsetMsgId 查询消息数据。也支持消费者通过 tag 来订阅主题下的不同消息,提升了消费者的灵活性。
一文详解RocketMQ的存储模型的更多相关文章
- 一文详解Hexo+Github小白建站
作者:玩世不恭的Coder时间:2020-03-08说明:本文为原创文章,未经允许不可转载,转载前请联系作者 一文详解Hexo+Github小白建站 前言 GitHub是一个面向开源及私有软件项目的托 ...
- epoll原理详解及epoll反应堆模型
本文转载自epoll原理详解及epoll反应堆模型 导语 设想一个场景:有100万用户同时与一个进程保持着TCP连接,而每一时刻只有几十个或几百个TCP连接是活跃的(接收TCP包),也就是说在每一时刻 ...
- Java网络编程和NIO详解3:IO模型与Java网络编程模型
Java网络编程和NIO详解3:IO模型与Java网络编程模型 基本概念说明 用户空间与内核空间 现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32 ...
- Web存储使用详解(本地存储、会话存储)
Web存储使用详解(本地存储.会话存储)1,Web存储介绍HTML5的Web存储功能是让网页在用户计算机上保存一些信息.Web存储又分为两种:(1)本地存储,对应 localStorage 对象.用于 ...
- 一文详解 Linux 系统常用监控工一文详解 Linux 系统常用监控工具(top,htop,iotop,iftop)具(top,htop,iotop,iftop)
一文详解 Linux 系统常用监控工具(top,htop,iotop,iftop) 概 述 本文主要记录一下 Linux 系统上一些常用的系统监控工具,非常好用.正所谓磨刀不误砍柴工,花点时间 ...
- 一文详解 OpenGL ES 3.x 渲染管线
OpenGL ES 构建的三维空间,其中的三维实体由许多的三角形拼接构成.如下图左侧所示的三维实体圆锥,其由许多三角形按照一定规律拼接构成.而组成圆锥的每一个三角形,其任意一个顶点由三维空间中 x.y ...
- 一文详解Redis键过期策略
摘要:Redis采用的过期策略:惰性删除+定期删除. 本文分享自华为云社区<Redis键过期策略详解>,作者:JavaEdge. 1 设置带过期时间的 key # 时间复杂度:O(1),最 ...
- 一文详解 WebSocket 网络协议
WebSocket 协议运行在TCP协议之上,与Http协议同属于应用层网络数据传输协议.WebSocket相比于Http协议最大的特点是:允许服务端主动向客户端推送数据(从而解决Http 1.1协议 ...
- 博文推荐|多图详解 Apache Pulsar 消息存储模型
关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ...
- 1.3w字,一文详解死锁!
死锁(Dead Lock)指的是两个或两个以上的运算单元(进程.线程或协程),都在等待对方停止执行,以取得系统资源,但是没有一方提前退出,就称为死锁. 1.死锁演示 死锁的形成分为两个方面,一个是使用 ...
随机推荐
- liunx文件定期本地备份、异地备份、删除备份脚本
导航 一.背景二.依赖功能介绍三.本地备份脚本四.异地备份脚本五.定期删除备份六.github脚本地址 - - - - - - - - - - 分割线 - - - - - - - - - - 一.背景 ...
- Oracle索引和事务
1. 什么是索引?有什么用? 1)索引是数据库对象之一,用于加快数据的检索,类似于书籍的目录.在数据库中索引可以减少数据库程序查询结果时需要读取的数据量,类似于在书籍中我们利用索引可以不用翻阅整本书即 ...
- 项目管理构建工具——Maven(高阶篇)
项目管理构建工具--Maven(高阶篇) 我们在之前的文章中已经基本了解了Maven,但也仅仅只止步于了解 Maven作为我们项目管理构建的常用工具,具备许多功能,在这篇文章中我们来仔细介绍 分模块开 ...
- __g is not defined
新手小白学习小程序开发遇到的问题以及解决方法 文章目录 1.出现的问题 2.解决的方法 1.出现的问题 2.解决的方法 删除app.json中的 "lazyCodeLoading" ...
- 齐博X1-栏目的调用2
fun('sort@fathers',$fid,'cms') 获取上层多级栏目这样的,比如我们现在所属第三级栏目,现在可以利用这个函数获取第二级和第一级的栏目,当然自身也会被调用出来,所以此函数用的 ...
- python(牛客)试题解析1 - 入门级
导航: 一.NC103 反转字符串 二.NC141 判断是否为回文字符串 三.NC151 最大公约数 四.NC65 斐波那契数列 - - - - - - - - - - 分-割-线 - - - - - ...
- ahk精简自用
;9:03 2022/8/20 自用 #NoEnv #Warn #SingleInstance Force ;设工作目录为桌面 SetWorkingDir %A_Desktop% ;托盘提示必须放在热 ...
- Nginx反向代理实现Tomcat+Jpress和halo
一.利用Nginx反向代理Jpress+Tomcat 1.环境准备 服务器 IP地址 作用 系统版本 Proxy代理服务器 10.0.0.101 负载均衡Nginx Web服务器 Ubuntu2004 ...
- 元数据Metadata到底有什么用
什么是元数据 元数据Metadata很简单,是关于数据的数据.这就意味着是数据的描述和上下文.他有助于组织和发现理解数据. 举例: 1张照片中除了照片本身还是,照片的时间日期,大小,格式相机设置,地理 ...
- htaccess如何配置隐藏index.php文件
<IfModule mod_rewrite.c> Options +FollowSymlinks -Multiviews RewriteEngine On RewriteCond %{RE ...