torch& tensorflow
#torch
import torch
import torch.nn as nn
import torch.nn.functional as F class Net(nn.Module): def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features net = Net()
print(net) params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weigh input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)

vgg
#从keras.model中导入model模块,为函数api搭建网络做准备
from tensorflow.keras import Model
from tensorflow.keras.layers import Flatten,Dense,Dropout,MaxPooling2D,Conv2D,BatchNormalization,Input,ZeroPadding2D,Concatenate
from tensorflow.keras import *
from tensorflow.keras import regularizers #正则化
from tensorflow.keras.optimizers import RMSprop #优化选择器
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.python.keras.utils import np_utils #数据处理
(X_train,Y_train),(X_test,Y_test)=mnist.load_data()
X_test1=X_test
Y_test1=Y_test
X_train=X_train.reshape(-1,28,28,1).astype("float32")/255.0
X_test=X_test.reshape(-1,28,28,1).astype("float32")/255.0
Y_train=np_utils.to_categorical(Y_train,10)
Y_test=np_utils.to_categorical(Y_test,10)
print(X_train.shape)
print(Y_train.shape)
print(X_train.shape) def vgg16():
x_input = Input((28, 28, 1)) # 输入数据形状28*28*1
# Block 1
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(x_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x) # Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x) # Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x) # Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x) # Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x) #BLOCK 6
x=Flatten()(x)
x=Dense(256,activation="relu")(x)
x=Dropout(0.5)(x)
x = Dense(256, activation="relu")(x)
x = Dropout(0.5)(x)
#搭建最后一层,即输出层
x = Dense(10, activation="softmax")(x)
# 调用MDOEL函数,定义该网络模型的输入层为X_input,输出层为x.即全连接层
model = Model(inputs=x_input, outputs=x)
# 查看网络模型的摘要
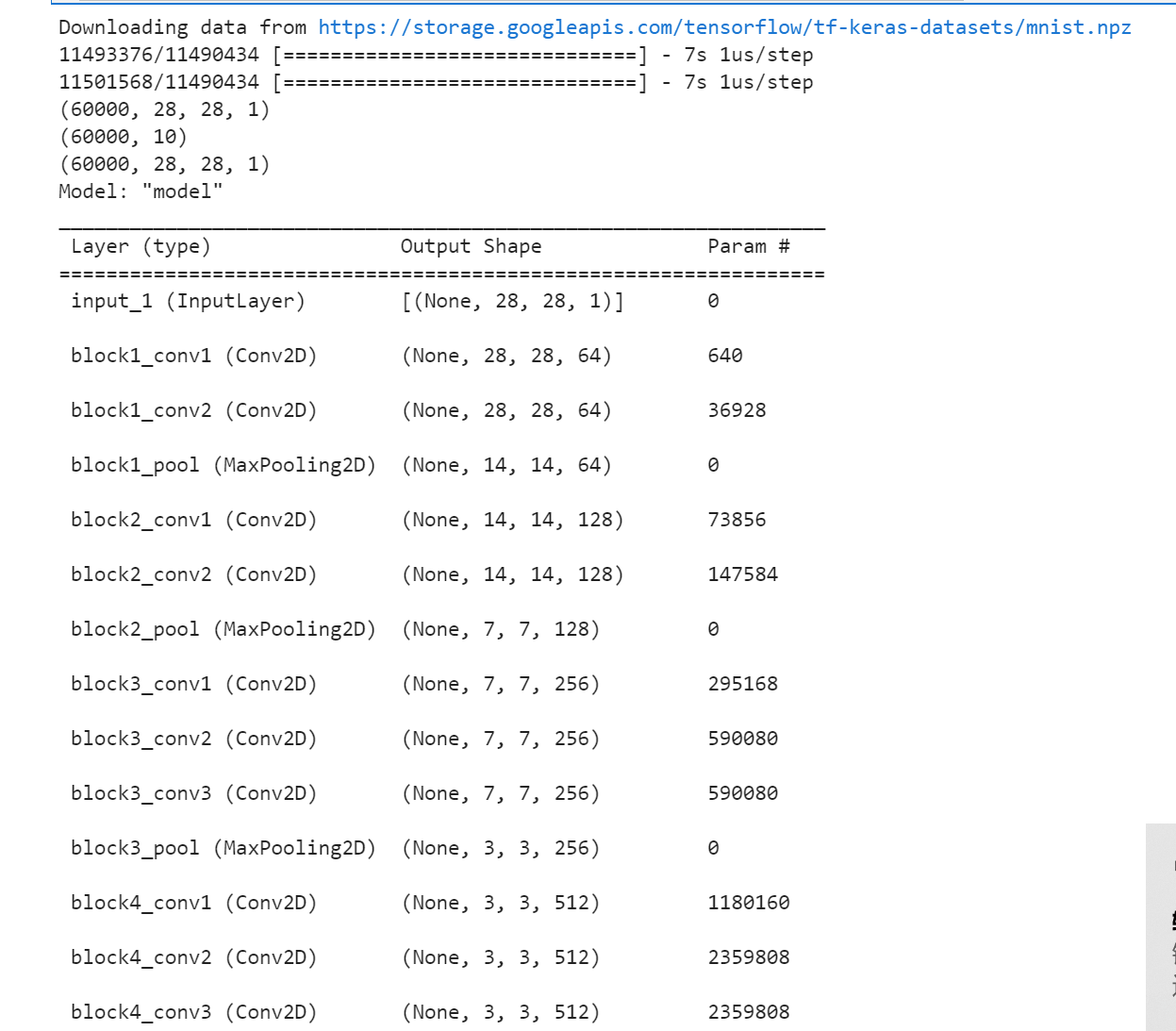
model.summary()
return model model=vgg16()
optimizer=RMSprop(lr=1e-4)
model.compile(loss="binary_crossentropy",optimizer=optimizer,metrics=["accuracy"])
#训练加评估模型
n_epoch=4
batch_size=128
def run_model(): #训练模型
training=model.fit(
X_train,
Y_train,
batch_size=batch_size,
epochs=n_epoch,
validation_split=0.25,
verbose=1
)
test=model.evaluate(X_train,Y_train,verbose=1)
return training,test
training,test=run_model()
print("误差:",test[0])
print("准确率:",test[1]) def show_train(training_history,train, validation):
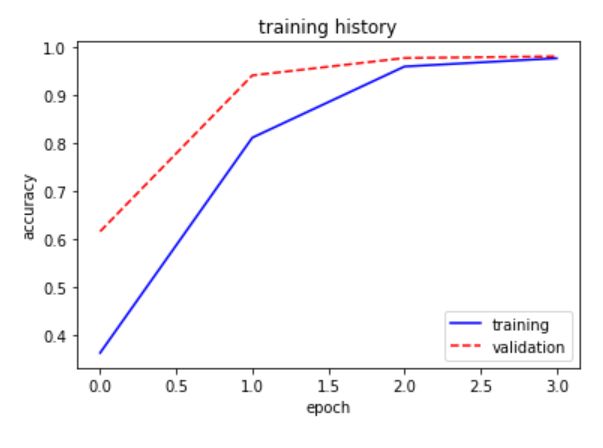
plt.plot(training.history[train],linestyle="-",color="b")
plt.plot(training.history[validation] ,linestyle="--",color="r")
plt.title("training history")
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.legend(["training","validation"],loc="lower right")
plt.show()
show_train(training,"accuracy","val_accuracy") def show_train1(training_history,train, validation):
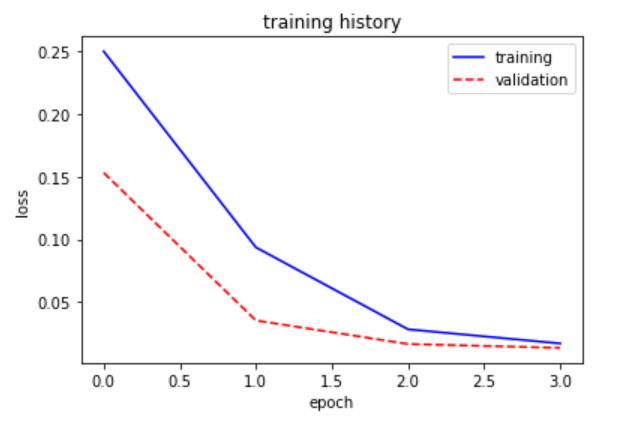
plt.plot(training.history[train],linestyle="-",color="b")
plt.plot(training.history[validation] ,linestyle="--",color="r")
plt.title("training history")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend(["training","validation"],loc="upper right")
plt.show()
show_train1(training,"loss","val_loss") prediction=model.predict(X_test)
def image_show(image):
fig=plt.gcf() #获取当前图像
fig.set_size_inches(2,2) #改变图像大小
plt.imshow(image,cmap="binary") #显示图像
plt.show()
def result(i):
image_show(X_test1[i])
print("真实值:",Y_test1[i])
print("预测值:",np.argmax(prediction[i]))
result(0)
result(1)



torch& tensorflow的更多相关文章
- Tutorial: Implementation of Siamese Network on Caffe, Torch, Tensorflow
Tutorial: Implementation of Siamese Network with Caffe, Theano, PyTorch, Tensorflow Updated on 2018 ...
- torch 入门
torch 入门1.安装环境我的环境mac book pro 集成显卡 Intel Iris不能用 cunn 模块,因为显卡不支持 CUDA2.安装步骤: 官方文档 (1).git clone htt ...
- 学习Data Science/Deep Learning的一些材料
原文发布于我的微信公众号: GeekArtT. 从CFA到如今的Data Science/Deep Learning的学习已经有一年的时间了.期间经历了自我的兴趣.擅长事务的探索和试验,有放弃了的项目 ...
- pytorch使用不完全文档
1. 利用tensorboard看loss: tensorflow和pytorch环境是好的的话,链接中的logger.py拉到自己的工程里,train.py里添加相应代码,直接能用. 关于环境,小小 ...
- CS231n 2016 通关 第一章-内容介绍
第一节视频的主要内容: Fei-Fei Li 女神对Computer Vision的整体介绍.包括了发展历史中的重要事件,其中最为重要的是1959年测试猫视觉神经的实验. In 1959 Harvar ...
- 深度学习框架caffe/CNTK/Tensorflow/Theano/Torch的对比
在单GPU下,所有这些工具集都调用cuDNN,因此只要外层的计算或者内存分配差异不大其性能表现都差不多. Caffe: 1)主流工业级深度学习工具,具有出色的卷积神经网络实现.在计算机视觉领域Caff ...
- Torch,Tensorflow使用: Ubuntu14.04(x64)+ CUDA8.0 安装 Torch和Tensorflow
系统配置: Ubuntu14.04(x64) CUDA8.0 cudnn-8.0-linux-x64-v5.1.tgz(Tensorflow依赖) Anaconda 1. Torch安装 Torch是 ...
- 一图看懂深度学习框架对比----Caffe Torch Theano TensorFlow
Caffe Torch Theano TensorFlow Language C++, Python Lua Python Python Pretrained Yes ++ Yes ++ Yes ...
- tensorflow,torch tips
apply weightDecay,L2 REGULARIZATION_LOSSES weights = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIAB ...
- 关于类型为numpy,TensorFlow.tensor,torch.tensor的shape变化以及相互转化
https://blog.csdn.net/zz2230633069/article/details/82669546 2018年09月12日 22:56:50 一只tobey 阅读数:727 1 ...
随机推荐
- SSM框架学习-AOP学习笔记
一.AOP入门简介 AOP(Aspect Oriented Programming)面向切面编程,是一种编程范式,可以知道开发者如何组织程序结构 作用:在不惊动原始设计的基础上为其进行功能增强.(无侵 ...
- RocketMQ 5.0 vs 4.9.X 图解架构对比
本文作者:李伟,Apache RocketMQ Committer,RocketMQ Python客户端项目Owner ,Apache Doris Contributor,腾讯云数据库开发工程师. 0 ...
- obj对象数据归类整理
两个字段根据id对应整理 <!doctype html> <html lang="en"> <head> <meta charse ...
- JSTL 报错 TagLibraryValidator
今天想要在 JSP 页面上用 JSTL 简化操作,发现导入 jstl.standard 包报错了.我是按照菜鸟上的教程来的.我的 Tomcat 版本是 10.0,之后发现 10.0 版本的 Tomca ...
- 《话糙理不糙》之如何在学习openfoam时避免坑蒙拐骗
今天开启一个单独的系列 <话糙理不糙> - 谁要和你说学openfoamC++基础不重要,那就是放氨气,非常误人 这就好比没读过外国文献的人和你说不需要学专业英语一样 谜底就在谜面里,程序 ...
- vue中如何在子组件添加类似于watch属性监听父组件数据,数据变化时子组件做出相应的动作
首先:我们需要在父组件中标签中定义一个 ref="parentObjVue" 其次:我们在子组件中,通过 var tmp=this.$refs.parentObjVue找到父组件 ...
- latex table \ref{}编号混乱
解决:\lable{}要紧放在\caption{}下 点击查看代码 \begin{table} ... \caption{Table A} \label{TableA} ... \end{table}
- Java--Comparable接口实现,控制数组和列表的排序
实现Comparable 接口,可以获得的排序方法有 列表排序 Collections.sort(); 数组排序 Arrays.sort(); sort()方法中的参数是可以获取排序索引的对象或者按照 ...
- UE4启动顺序
GameMode PlayerController Actor Level gameMode , playerController控制pawn , 激活默认相机active camera , getP ...
- ubuntu18 电脑重启后登录后无法进入桌面
ubuntu18 电脑重启后登录后无法进入桌面 应该是ubuntu桌面管理器gdm3和nvidia驱动冲突导致的 解决办法: 首先卸载已有的nvidia驱动 注意:在下载完驱动后,此时电脑没有驱动文件 ...