Pytorch实战学习(七):高级CNN
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Advanced CNN
一、GoogLeNet
Inception Module:而为了减少代码的冗余,将由(卷积(Convolution),池化(Pooling)、全连接(Softmax)以及连接(Other))四个模块所组成的相同的部分,封装成一个类/函数。
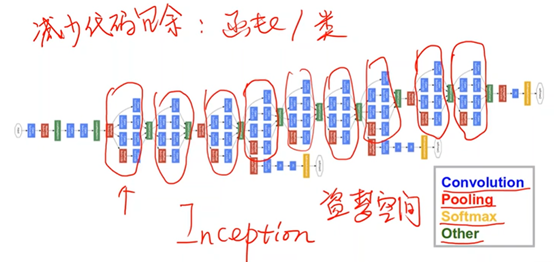
1、Inception Module
以卷积核大小(kernel_size)为例,虽然无法具体确定某问题中所应使用的卷积核的大小。但是往往可以有几种备选方案,因此在这个过程中,可以利用这样的网络结构,来将所有的备选方案进行计算,并在后续计算过程中增大最佳方案的权重,以此来达到确定超参数以及训练网络的目的。
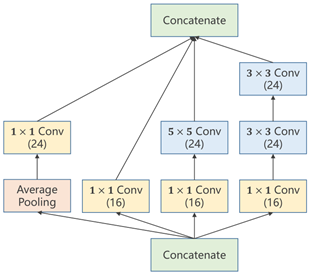
最后每个张量沿着通道拼接(Concatenate)在一起时,要保证图像宽度、高度必须相同,通道可以不同
①Average Pooling:均值池化,需要手动设定padding以及stride来保持图像大小(W&H)不变
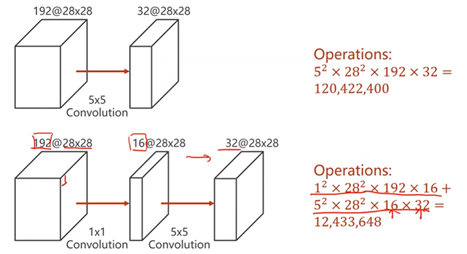
②1×1 Conv:个数取决于输入张量的通道数,用于改变通道数量
2、1×1 Conv
在1x1卷积中,每个通道的每个像素需要与卷积中的权重进行计算,得到每个通道的对应输出,再进行求和得到一个单通道的总输出,以达到信息融合的目的。即将同一像素位置的多个通道信息整合在同位置的单通道上。
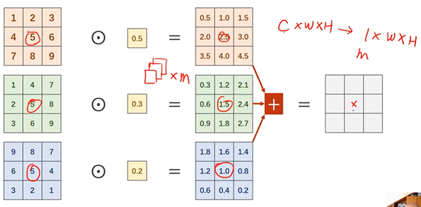
1x1卷积:减少计算量
3、Inception Module代码实现
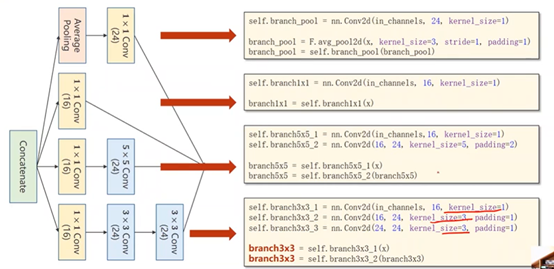
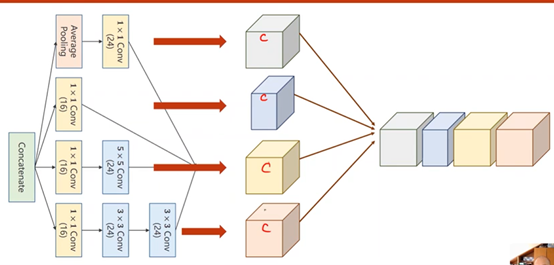
沿着通道进行拼接,dim设为1(batch-0、channel-1、weight-2、hight-3)

定义一个Inception Module

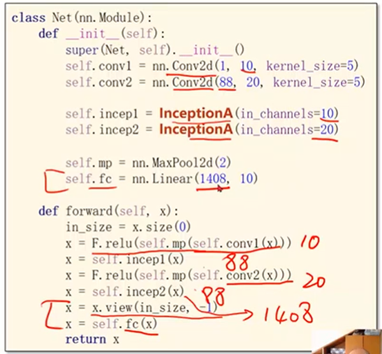
经过Inception模块输出的通道数:24*3+16=88
4、完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # prepare dataset batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) # design model using class class InceptionA(torch.nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2) self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1) self.branch_pool = torch.nn.Conv2d(in_channels, 24, kernel_size=1) def forward(self, x):
branch1x1 = self.branch1x1(x) branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5) branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3) branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool) outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1 class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16 self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应
self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应 self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408, 10) def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x) return x model = Net()
## Device—选择是用GPU还是用CPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device) # construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad() outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step() running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0 def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total)) if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()

二、ResNet (残差网络)
1、解决梯度消失问题
梯度消失:由于在梯度计算的过程中是用的反向传播,所以需要利用链式法则来进行梯度计算,是一个累乘的过程。若每一个地方梯度都是小于1的,累乘之后的总结果应趋近于0,ω不会再进行进一步的更新
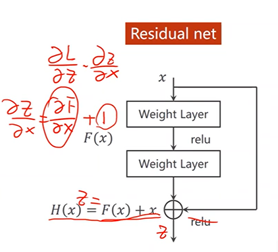
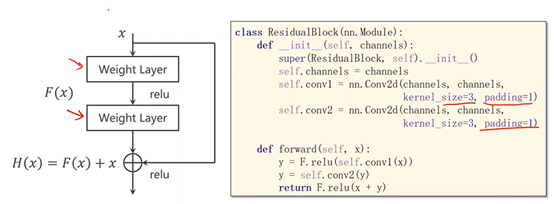
2、跳连接,H(x) = F(x) + x,张量维度必须一样,加完后再激活。不要做pooling,张量的维度会发生变化。
若存在梯度消失现象,即存在某一层网络中的对x求偏导趋近于0
通过加入一个x会使得在方向传播过程中,传播的梯度会保持在1左右,即对x求偏导趋近于1如此,离输入较近的层也可以得到充分的训练。
3、Residual Block
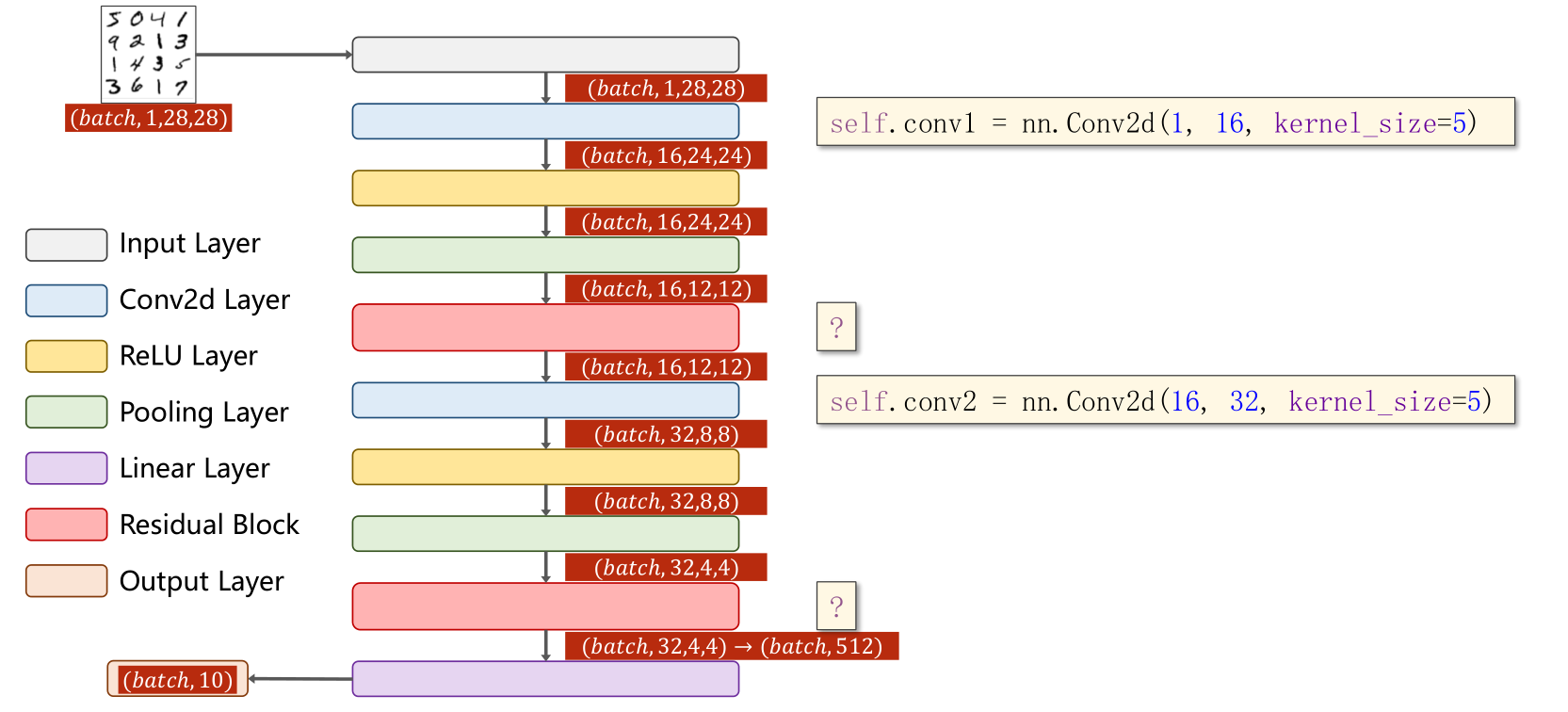
实现 Residual Block,要确保输入和输出维度大小完全一样(等宽等高等通道数)
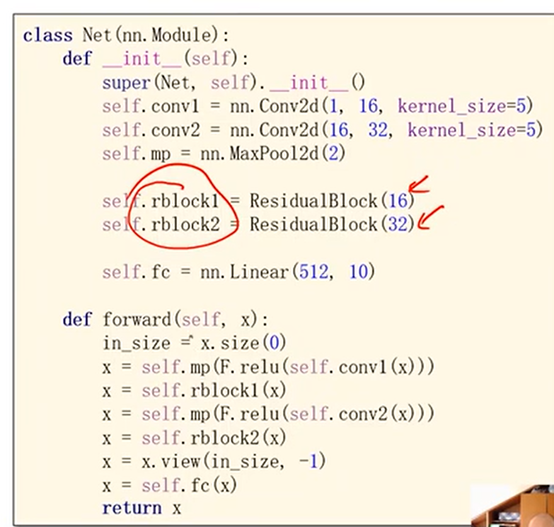
先是1个卷积层(conv,maxpooling,relu),然后Residual Block模块,接下来又是一个卷积层(conv,mp,relu),然后Residual Block模块模块,最后一个全连接层(fc)。
4、完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # prepare dataset batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) # design model using class class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
#为了保证 输入和输出 维度相同
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1) def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
# H(x) = F(x) + x,加完以后再Relu
return F.relu(x + y) class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5) # 88 = 24x3 + 16 self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32) self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(512, 10) # 暂时不知道1408咋能自动出来的 def forward(self, x):
in_size = x.size(0) x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x) x = x.view(in_size, -1)
x = self.fc(x)
return x model = Net()
## Device—选择是用GPU还是用CPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device) # construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad() outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step() running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0 def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total)) if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()

Pytorch实战学习(七):高级CNN的更多相关文章
- nginx学习七 高级数据结构之动态数组ngx_array_t
1 ngx_array_t结构 ngx_array_t是nginx内部使用的数组结构.nginx的数组结构在存储上与大家认知的C语言内置的数组有相似性.比方实际上存储数据的区域也是一大块连续的内存. ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 深度学习之PyTorch实战(1)——基础学习及搭建环境
最近在学习PyTorch框架,买了一本<深度学习之PyTorch实战计算机视觉>,从学习开始,小编会整理学习笔记,并博客记录,希望自己好好学完这本书,最后能熟练应用此框架. PyTorch ...
- Shell高级编程视频教程-跟着老男孩一步步学习Shell高级编程实战视频教程
Shell高级编程视频教程-跟着老男孩一步步学习Shell高级编程实战视频教程 教程简介: 本教程共71节,主要介绍了shell的相关知识教程,如shell编程需要的基础知识储备.shell脚本概念介 ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
- (转)跟着老男孩一步步学习Shell高级编程实战
原文:http://oldboy.blog.51cto.com/2561410/1264627/ 跟着老男孩一步步学习Shell高级编程实战 原创作品,允许转载,转载时请务必以超链接形式标明文章 原 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- 参考《深度学习之PyTorch实战计算机视觉》PDF
计算机视觉.自然语言处理和语音识别是目前深度学习领域很热门的三大应用方向. 计算机视觉学习,推荐阅读<深度学习之PyTorch实战计算机视觉>.学到人工智能的基础概念及Python 编程技 ...
- 【新生学习】深度学习与 PyTorch 实战课程大纲
各位20级新同学好,我安排的课程没有教材,只有一些视频.论文和代码.大家可以看看大纲,感兴趣的同学参加即可.因为是第一次开课,大纲和进度会随时调整,同学们可以随时关注.初步计划每周两章,一个半月完成课 ...
- Maven实战(七,八)——经常使用Maven插件介绍
我们都知道Maven本质上是一个插件框架,它的核心并不运行不论什么详细的构建任务,全部这些任务都交给插件来完毕,比如编译源代码是由maven-compiler-plugin完毕的.进一步说,每一个任务 ...
随机推荐
- Vue15 v-for和key的作用及原理
部分转自https://blog.csdn.net/cun_king/article/details/120714227 1 v-for指令 1.1 简介 用于遍历. 当在组件中使用 v-for 时, ...
- Three.js 进阶之旅:物理效果-碰撞和声音 💥
摘要 本文内容主要汇总如何在 Three.js 创建的 3D 世界中添加物理效果,使其更加真实.所谓物理效果指的是对象会有重力,它们可以相互碰撞,施加力之后可以移动,而且通过铰链和滑块还可以在移动过程 ...
- nodejs 环境变量配置
1.下载 下载地址: https://nodejs.org/zh-cn/download/ 2.安装 安装一直下一步即可,建议安装路径不要包含中文 3.环境变量配置 1)右键[我的电脑],点击[属性] ...
- Windows下x86和x64平台的Inline Hook介绍
前言 我在之前研究文明6的联网机制并试图用Hook技术来拦截socket函数的时候,熟悉了简单的Inline Hook方法,但是由于之前的方法存在缺陷,所以进行了深入的研究,总结出了一些有关Windo ...
- osx使用alfred集成有道查词
概述 使用 mac 的同学应该经常会使用 alfred 这个软件, 主要能随时能够通过一个快键键打开查询窗口, 方便的搜索或打开软件, 文件等等, 同时也可以集成脚本方便实现其它的功能. 在日常使用的 ...
- [USACO17JAN]Promotion Counting P
题目大意 大小为 \(n\) 以 \(1\) 为根的树,点带权,求每个子树内大于本点的点的数量 \(1 \le n \le 10^5,1 \le p_i \le 10^9\) 题解 一眼静态链分治,然 ...
- vue-element-admin 怎么改后端 可以调跳过登录并且发送接口请求
1.找到根目录的 vue.config.js 添加 proxy 内容 注释掉mock 2.清空 .env.development 里的 VUE_APP_BASE_API 路径 3.user.js 方 ...
- HC-SR501人体红外传感器使用说明
1. 模块为全自动感应,当人进入其感应范围则输出高电平,人离开感应范围则自动延时关闭高电平,输出低电平. 2. 传感器有两种触发方式(可通过跳线进行选择):第一种不可重复触发方式,即感应输出高电平后, ...
- winform应用程序
1.winform桌面应用程序是一种智能的客户端技术,我们可以使用winform应用程序帮助我们获得信息或者传输信息等 2.属性 Names:在后台要获得前台的控件对象,需要使用Name属性 Visi ...
- Spring随意总结
Spring框架的优点 1.使用Spring的IOC容器,将对象之间的依赖关系交给Spring,降低组件之间的耦合性,让我们更专注于应用逻辑 2.可以提供众多服务,事务管理,WS等. 3.AOP的很好 ...