基于DFA算法实现的敏感词过滤
本文转自浅析敏感词过滤算法(C++),自己也在其基础上根据自己的情况做了一点修改。
https://blog.csdn.net/u012755940/article/details/51689401?utm_source=app
为了提高查找效率,这里将敏感词用树形结构存储,每个节点有一个map成员,其映射关系为一个string对应一个WordNode。
比如敏感词库里面有枪手、手枪这几个词,读入后就变成了如下图所示的树状结构。
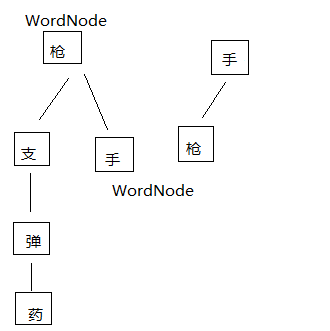
STL::map是按照operator<比较判断元素是否相同,以及比较元素的大小,然后选择合适的位置插入到树中。
下面主要实现了WordNode类,进行节点的插入以及查询。
WordNode.h
#ifndef __WORDNODE_H__
#define __WORDNODE_H__ #define PACE 1 #include <string>
#include <map>
#include <stdio.h> class CWordNode
{
public:
CWordNode(std::string character);
CWordNode(){ m_character = ""; };
~CWordNode();
std::string getCharacter() const{ return m_character; };
CWordNode* findChild(std::string& nextCharacter);
CWordNode* insertChild(std::string& nextCharacter);
private:
friend class CWordTree;
typedef std::map<std::string, CWordNode> _TreeMap;
typedef std::map<std::string, CWordNode>::iterator _TreeMapIterator; std::string m_character;
_TreeMap m_map;
CWordNode* m_parent;
}; #endif
WordNode.cpp
#include "WordNode.h" using namespace std; CWordNode::~CWordNode()
{ } CWordNode::CWordNode(std::string character)
{
if (character.size() == PACE)
{
m_character.assign(character);
}
} CWordNode* CWordNode::findChild(std::string& nextCharacter)
{
_TreeMapIterator TreeMapIt = m_map.find(nextCharacter);
if (TreeMapIt == m_map.end())
{
return NULL;
}
else
{
return &TreeMapIt->second;
}
} CWordNode* CWordNode::insertChild(std::string& nextCharacter)
{
if (!findChild(nextCharacter))
{
m_map.insert(pair<std::string, CWordNode>(nextCharacter, CWordNode(nextCharacter)));
return &(m_map.find(nextCharacter)->second);
}
return NULL;
}
另外,
#define PACE 1这里的PACE原本是2,因为一个GBK汉字占两个字符,而且原文中也说了如果需要考虑英文或中英文结合的情况,将PACE改为1。
不过我试过之后,觉得不管是中文、英文还是中英文,PACE为 1 都适用,结果都没错,只不过中文的情况下每个节点的string都不再是一个完整的汉字,而是汉字的一个字符。
接下来实现这个tree,在建立WordNode树时,以parent为根节点建立,一开始parent为m_emptyRoot,然后keyword按照规则添加到树中,假设一开始m_emptyRoot为空,keyword为”敏感词”,则会以”敏感词”为一条分支建立成为一颗树枝’敏’->’感’->’词’,此后,若想再添加”敏感度”,由于”敏感词”与”敏感度”的前两个字相同,则会在’敏’->’感’->’词’的基础上,从字’感’开始新生长出一颗分支,即’敏’->’感’->’度’,这两颗分支共用’敏’->’感’。
下面代码实现了WordTree类,进行树的构成及查询。
WordTree.h
#ifndef __WORDTREE_H__
#define __WORDTREE_H__ #include "WordNode.h" class CWordTree
{
public:
CWordTree();
~CWordTree(); int nCount;
CWordNode* insert(std::string &keyWord);
CWordNode* insert(const char* keyword);
CWordNode* find(std::string& keyword);
private:
CWordNode m_emptyRoot;
int m_pace;
CWordNode* insert(CWordNode* parent, std::string& keyword);
CWordNode* insertBranch(CWordNode* parent, std::string& keyword);
CWordNode* find(CWordNode* parent, std::string& keyword);
}; #endif // __WORDTREE_H__
WordTree.cpp
#include "WordTree.h" CWordTree::CWordTree()
:nCount(0)
{ } CWordTree::~CWordTree()
{
} CWordNode* CWordTree::insert(std::string &keyWord)
{
return insert(&m_emptyRoot, keyWord);
} CWordNode* CWordTree::insert(const char* keyWord)
{
std::string wordstr(keyWord);
return insert(wordstr);
} CWordNode* CWordTree::insert(CWordNode* parent, std::string& keyWord)
{
if (keyWord.size() == 0)
{
return NULL;
}
std::string firstChar = keyWord.substr(0, PACE);
CWordNode* firstNode = parent->findChild(firstChar);
if (firstNode == NULL)
{
return insertBranch(parent, keyWord);
}
std::string restChar = keyWord.substr(PACE, keyWord.size());
return insert(firstNode, restChar);
} CWordNode* CWordTree::find(std::string& keyWord)
{
return find(&m_emptyRoot, keyWord);
} CWordNode* CWordTree::find(CWordNode* parent, std::string& keyWord)
{
std::string firstChar = keyWord.substr(0, PACE);
CWordNode* firstNode = parent->findChild(firstChar);
if (firstNode == NULL)
{
nCount = 0;
return NULL;
}
std::string restChar = keyWord.substr(PACE, keyWord.size());
if (firstNode->m_map.empty())
{
return firstNode;
}
if (keyWord.size() == PACE)
{
return NULL;
}
nCount++;
return find(firstNode, restChar);
} CWordNode* CWordTree::insertBranch(CWordNode* parent, std::string& keyWord)
{
std::string firstChar = keyWord.substr(0, PACE);
CWordNode* firstNode = parent->insertChild(firstChar);
if (firstNode != NULL)
{
std::string restChar = keyWord.substr(PACE, keyWord.size());
if (!restChar.empty())
{
return insertBranch(firstNode, restChar);
}
}
return NULL;
}
最后就是利用上述的Tree来实现敏感词过滤,WordFilter::censor(string &source) 函数用来进行敏感词过滤,source即输入的字符串,如果source包含敏感词,则用“**”替代掉。
WordFilter::load(const char* filepath) 函数通过文件载入敏感词,并构建WordTree,这里我用的是txt文件。
下面实现了WordFilter类。
WordFilter.h
#ifndef __WORDFILTER_H__
#define __WORDFILTER_H__ #include "WordTree.h"
#include "base/CCRef.h" USING_NS_CC; class CWordFilter : public Ref
{
public:
~CWordFilter();
bool loadFile(const char* filepath);
bool censorStr(std::string &source);
bool censorStrWithOutSymbol(const std::string &source);
static CWordFilter* getInstance();
static void release();
private:
std::string string_To_UTF8(const std::string & str);
std::string UTF8_To_string(const std::string & str);
CWordFilter();
static CWordFilter* m_pInstance;
CWordTree m_WordTree;
}; #endif // __WORDFILTER_H__
WordFilter.cpp
#include "WordFilter.h"
#include <ctype.h>
#include <algorithm>
#include <iostream>
#include <fstream>
#include <istream> using namespace std; USING_NS_CC; CWordFilter* CWordFilter::m_pInstance = nullptr;
CWordFilter::CWordFilter()
{
} CWordFilter::~CWordFilter()
{
} CWordFilter* CWordFilter::getInstance()
{
if (m_pInstance == NULL)
{
m_pInstance = new CWordFilter();
}
return m_pInstance;
} void CWordFilter::release()
{
if (m_pInstance)
{
delete m_pInstance;
}
m_pInstance = NULL;
} bool CWordFilter::loadFile(const char* filepath)
{
ifstream infile(filepath, ios::in); if (!infile)
{
return false;
}
else
{
string read;
while (getline(infile, read))
{
#if (CC_TARGET_PLATFORM == CC_PLATFORM_ANDROID || CC_TARGET_PLATFORM == CC_PLATFORM_IOS)
string s;
s = read.substr(0, read.length() - 1);
m_WordTree.insert(s);
#else
m_WordTree.insert(read);
#endif
}
} infile.close();
return true;
} bool CWordFilter::censorStr(string &source)
{
int lenght = source.size();
for (int i = 0; i < lenght; i += 1)
{
string substring = source.substr(i, lenght - i);
if (m_WordTree.find(substring) != NULL)
{
source.replace(i, (m_WordTree.nCount + 1), "**");
lenght = source.size();
return true;
}
}
return false;
} bool CWordFilter::censorStrWithOutSymbol(const std::string &source)
{
string sourceWithOutSymbol; int i = 0;
while (source[i] != 0)
{
if (source[i] & 0x80 && source[i] & 0x40 && source[i] & 0x20)
{
int byteCount = 0;
if (source[i] & 0x10)
{
byteCount = 4;
}
else
{
byteCount = 3;
}
for (int a = 0; a < byteCount; a++)
{
sourceWithOutSymbol += source[i];
i++;
}
}
else if (source[i] & 0x80 && source[i] & 0x40)
{
i += 2;
}
else
{
i += 1;
}
}
return censorStr(sourceWithOutSymbol);
}
这里说明一点,本人是做Cocos2d-x手游客户端开发的,程序是要移植到安卓或者iOS平台上。当逐行读取txt文件中的敏感词并构成树的时候,getline(infile, read)函数得到的read字符串后面带有结束符,比如“枪手\0”,这时跟我们需要检测的字符串“…枪手…”就明显不符合,这是检测不出来的。这种情况我现在只知道在安卓或者iOS平台存在,而在windows环境下VS中是不会出现这种问题的。所以我对读取到的字符串做了处理,把最后一个字符也就是结束符去掉,再进行下一步操作。
而我使用的是lua,lua发送给C++的字符串都是用utf-8编码的,所以再去除字符串的时候并不能简答的使用(a & 0x80)来判断
基于DFA算法实现的敏感词过滤的更多相关文章
- DFA算法之内容敏感词过滤
DFA 算法是通过提前构造出一个 树状查找结构,之后根据输入在该树状结构中就可以进行非常高效的查找. 设我们有一个敏感词库,词酷中的词汇为:我爱你我爱他我爱她我爱你呀我爱他呀我爱她呀我爱她啊 那么就可 ...
- Java实现敏感词过滤 - IKAnalyzer中文分词工具
IKAnalyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包. 官网: https://code.google.com/archive/p/ik-analyzer/ 本用例借助 I ...
- 基于DFA算法、RegExp对象和vee-validate实现前端敏感词过滤
面临敏感词过滤的问题,最简单的方案就是对要检测的文本,遍历所有敏感词,逐个检测输入的文本是否包含指定的敏感词. 很明显上面这种实现方法的检测时间会随着敏感词库数量的增加而线性增加.系统会因此面临性能和 ...
- web系统安全运营之基础- 基于DFA算法的高性能的敏感词,脏词的检测过滤算法类(c#).
[概述]做好一个web系统的安全运维,除了常规的防注入,防入侵等,还有一个检测并过滤敏感词,脏词.. 这件事做得不好,轻则导致一场投诉或纠纷,重则导致产品被勒令关闭停运. 废话少说,先看下代码,可以 ...
- java实现敏感词过滤(DFA算法)
小Alan在最近的开发中遇到了敏感词过滤,便去网上查阅了很多敏感词过滤的资料,在这里也和大家分享一下自己的理解. 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxo ...
- Java实现敏感词过滤 - DFA算法
Java实现DFA算法进行敏感词过滤 封装工具类如下: 使用前需对敏感词库进行初始化: SensitiveWordUtil.init(sensitiveWordSet); package cn.swf ...
- 敏感词过滤的算法原理之DFA算法
参考文档 http://blog.csdn.net/chenssy/article/details/26961957 敏感词.文字过滤是一个网站必不可少的功能,如何设计一个好的.高效的过滤算法是非常有 ...
- DFA和trie特里实现敏感词过滤(python和c语言)
今天的项目是与完成python开展,需要使用做关键词检查,筛选分类,使用前c语言做这种事情.有了线索,非常高效,内存小了,检查快. 到达python在,第一个想法是pip基于外观的c语言python特 ...
- 超强敏感词过滤算法第二版 可以忽略大小写、全半角、简繁体、特殊符号、HTML标签干扰
上一篇 发一个高性能的敏感词过滤算法 可以忽略大小写.全半角.简繁体.特殊符号干扰 改进主要有几点: 用BitArray取代Dictionary用空间换时间 性能进一步提升 大概会增加词库的 6k* ...
- 5分钟构建无服务器敏感词过滤后端系统(基于FunctionGraph)
摘要:开发者通过函数工作流,无需配置和管理服务器,以无服务器的方式构建应用,便能开发出一个弹性高可用的后端系统.托管函数具备以毫秒级弹性伸缩.免运维.高可靠的方式运行,极大地提高了开发和运维效率,减小 ...
随机推荐
- AD7793 ADC FPGA控制逻辑实现
AD7793简介 https://www.analog.com/media/en/technical-documentation/data-sheets/AD7792_7793.pdf 特点如下,有1 ...
- 力扣---1148. 文章浏览 I
Views 表:+---------------+---------+| Column Name | Type |+---------------+---------+| article_i ...
- IDEA新手使用教程【详解】
IDEA是一款功能强悍.非常好用的Java开发工具,近几年编程开发人员对IDEA情有独钟. Intellij Idea使用技巧总结 1.如何设置通过鼠标滑轮改变编辑器字体大小 2.如何设置自动导包功能 ...
- Ubuntu18.04中用CMake-gui安装OpenCV3.2.0和OpenCV_contrib-3.2.0
下载和添加依赖包1.首先更新 apt-get,在安装前最好先更新一下系统,不然有可能会安装失败.在终端输入: sudo apt-get update sudo apt-get upgrad ...
- C++练习2 强制类型转换
const可以把有关的数据定义为常量. const类型可以修饰:对象,指针,引用 使用const_cast为强制类型转换,将常量强制转换非常量. 1 #include <iostream> ...
- 安卓逆向 利用JEB进行动态调试断点 进行内购
1.第一步肯定是需要配置好,连接到模拟器 2.这个程序会弹出支付失败 所以我们搜索一下关键字 看到这里就很兴奋了 我们取JEB里面对这个方法进行断点 if eqz 等于0 这里 看到那个寄存器是v5 ...
- 详解神经网络基础部件BN层
摘要:在深度神经网络训练的过程中,由于网络中参数变化而引起网络中间层数据分布发生变化的这一过程被称为内部协变量偏移(Internal Covariate Shift),而 BN 可以解决这个问题. 本 ...
- [AI-ML]机器学习是什么?一起了解!(一)
机器学习 简单的说,机器学习是一种让计算机系统从数据中学习并自动改进的算法.通俗地说,机器学习就是让计算机从数据中"学习",并使用这些学习成果来做出决策或预测. 学术解释中,机器学 ...
- [EULAR文摘] 肢端MRI能否在未分化关节患者中甄别出RA患者
标签: EULAR文摘; 未分化关节炎; 病程演变; MRI;早期诊断 肢端MRI能否在未分化关节患者中甄别出RA患者 Nieuwenhuis WP, et al. EULAR 2015.Presen ...
- MRI病变能否预测已获临床缓解的早期RA未来放射学进展
MRI病变能否预测已获临床缓解的早期RA未来放射学进展 Tamai M, et al. EULAR 2015. Present ID: FRI0048. 原文 译文 FRI0048 MRI BONE ...