linux之Deamon进程创建及其进程exit,_exit,return之间的区别
chdir("/")
umask(0)
int fd = open("/dev/console", O_RDWR);
#include <unistd.h>int daemon(int nochdir, int noclose);
ret = daemon(0,0)
#include <unistd.h>void _exit(int status);
#include <stdlib.h>void exit(int status);
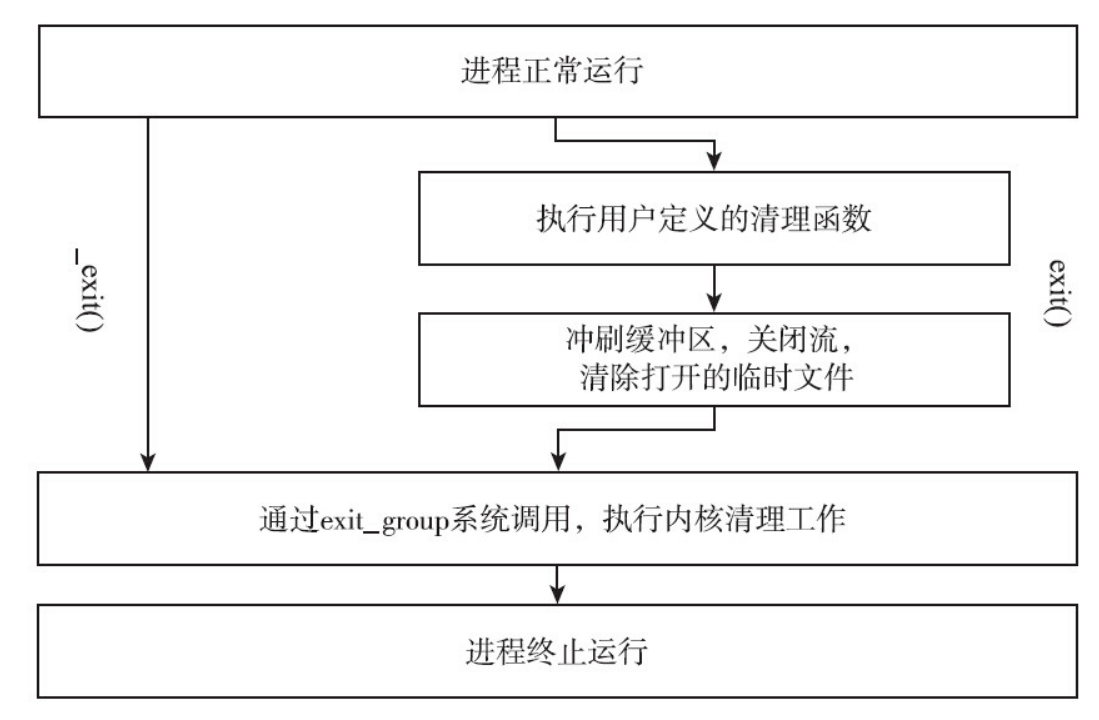
#include <stdio.h>#include <stdlib.h>#include <unistd.h>void foo(){fprintf(stderr,"foo says bye.\n");}void bar(){fprintf(stderr,"bar says bye.\n");}int main(int argc, char **argv){atexit(foo);atexit(bar);fprintf(stdout,"Oops ... forgot a newline!");sleep(2);if (argc > 1 && strcmp(argv[1],"exit") == 0)exit(0);if (argc > 1 && strcmp(argv[1],"_exit") == 0)_exit(0);return 0;- }
manu@manu-hacks:exit$ ./test exit //调用exit结束,输出了缓冲区的字符bar says bye.foo says bye.Oops ... forgot a newline!manu@manu-hacks:exit$ //调用return 输出了缓冲区字符manu@manu-hacks:exit$manu@manu-hacks:exit$ ./testbar says bye.foo says bye.Oops ... forgot a newline!manu@manu-hacks:exit$ //直接调用_exit没有输出缓冲区的字符manu@manu-hacks:exit$manu@manu-hacks:exit$ ./test _exitmanu@manu-hacks:~/code/self/c/exit$
linux之Deamon进程创建及其进程exit,_exit,return之间的区别的更多相关文章
- ASP.NET Core Linux下为 dotnet 创建守护进程(必备知识)
前言 在上篇文章中介绍了如何在 Docker 容器中部署我们的 asp.net core 应用程序,本篇主要是怎么样为我们在 Linux 或者 macOs 中部署的 dotnet 程序创建一个守护进程 ...
- ASP.ENT Core Linux 下 为 donet创建守护进程(转载)
原文地址:http://www.cnblogs.com/savorboard/p/dotnetcore-supervisor.html 前言 在上篇文章中介绍了如何在 Docker 容器中部署我们的 ...
- 进程基本-进程创建,僵尸进程,exec系列函数
Linux系统中,进程的执行模式划分为用户模式和内核模式,当进程运行于用户空间时属于用户模式,如果在用户程序运行过程中出现系统调用或者发生中断事件,就要运行操作系统(即核心)程序,进程的运行模式就变为 ...
- Win32进程创建、进程快照、进程终止用例
进程创建: 1 #include <windows.h> #include <stdio.h> int main() { // 创建打开系统自带记事本进程 STARTUPINF ...
- linux fork函数与vfork函数,exit,_exit区别
man vfork: NAME vfork - create a child process and block parent SYNOPSIS #include <sys/types.h> ...
- abort exit _exit return的区别
exit()函数导致子进程的正常退出,并且参数status&这个值将被返回给父进程.exit()应该是库函数.exit()函数其实是对_exit()函数的一种封装(库函数就是对系统调用的一种封 ...
- Linux编程中的坑——C++中exit和return的区别
今天遇到一个坑,折腾了一天才把这个坑填上,情况是这样的: 写了段代码,在main()函数中创建一个分离线程,结果这个线程什么都没干就直接挂掉了,代码长这样: int main() { 创建一个分离线程 ...
- exit()和return语句的区别
(1)exit用于结束正在运行的程序,exit函数将参数是返回给OS.而return是返回函数值并退出函数. (2)return是语言级别的,它表示了调用堆栈的返回:而exit是系统调用级别的,它表示 ...
- Linux软件安装包中devel与非devel包之间的区别
带devel(develop)的包,俗称开发包.功能上与普通包相同,但体积更大使用rpm -qi看看这两类包的区别: # rpm -qi glibc-devel-2.12-1.149.el6.x86_ ...
随机推荐
- 图解Disruptor框架(一):初识Ringbuffer
图解Disruptor框架(一):初识Ringbuffer 概述 1. 什么是Disruptor?为什么是Disruptor? Disruptor是一个性能十分强悍的无锁高并发框架.在JUC并发包中, ...
- python3 循环输出当前时间。
题目 暂停一秒输出(使用 time 模块的 sleep() 函数).循环输出当前时间. 代码: import time while True: time.sleep(1) print(time.str ...
- Linux 关于SELinux的命令及使用
1. 模式的设置 : 修改/etc/selinux/config文件中的SELINUX=”" 的值 ,然后重启.enforcing:强制模式,只要selinux不允许,就无法执行 permi ...
- android adb虚拟机对应的键盘命令
HOME Home button 主界面键 F2, PAGEUP Menu (Soft-Left) ...
- 【MySQL】MySQL基础
一.基本语法 [MySQL目录结构]●bin目录,存储可执行文件●data目录,存储数据文件●docs,文档●include目录,存储包含的头文件●lib目录,存储库文件●share,错误信息和字符集 ...
- Leetcode7--->Reverse Integer(逆转整数)
题目: 给定一个整数,求将该整数逆转之后的值: 举例: Example1: x = 123, return 321Example2: x = -123, return -321 解题思路: 在这里只用 ...
- [已解决] wordpress 修改 permalink 后 页面 404 问题
功能说明 为了利于SEO优化,我们需要将地址设置为永久链接,在层级不要太深的情况下实现伪静态页面的目的,例如wordpress 默认页面地址为: https://www.ryanzoe.top/?p= ...
- gdb调试手册 一 gdb概述
一 gdb概述 gdb调试器的目的是让你了解其他的程序在执行的时候发生了什么或者其他程序崩溃时正在做什么 gdb主要能够在运行中做四类事情(包括这些事情中的一些附加的事情)来帮助你获取bugs a 运 ...
- TensorFlow——深入MNIST
程序(有些不甚明白的地方改日修订): # _*_coding:utf-8_*_ import inputdata mnist = inputdata.read_data_sets('MNIST_dat ...
- match_parent, wrap_content, 和 fill_parent 区别联系
fill_parent -1 The view should be as big as its parent (minus padding). This constant is deprecat ...