kafka监控之topic的lag情况监控
需求描述:lag(滞后)是kafka消费队列性能监控的重要指标,lag的值越大,表示kafka的堆积越严重。本篇文章将使用python脚本+influxdb+grafana的方式对kafka的offset、logsiz和lag这三个参数进行监控,并以图形化的方式进行展现。
架构描述:使用python收集kafka的相关信息并存储到influxdb里;配置grafana,将influxdb里的数据以图形化的方式展现出来。
一,准备工作
1,kafka,influxdb,grafana的安装(在此不详细描述,默认为阅读文章的各位对这三样工具的使用是熟悉的)
2,查询kafka消费状态的命令/kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181。本篇文章也将以此条命令输出的信息作为基础编写脚本。
#/kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181
Group Topic Pid Offset logSize Lag Owner
group1 topicname1 0 978337806 978390228 52422 none
group1 topicname1 1 978337840 978390295 52455 none
group1 topicname1 2 978263557 978316052 52495 none
group1 topicname1 3 978307075 978359597 52522 none
group1 topicname1 4 978337803 978390358 52555 none
group1 topicname1 5 978337812 978390394 52582 none
说明:
group1 组名
topicname1 topic名
我们要用脚本取的,就是输出的这段内容的Offset logSize Lag这三个值,并将所有分片的这些值相加,从而获取单个topic的Offset logSize Lag的值,并将值输出到一个txt文件暂存。我这里使用一个shell脚本来取数据和一个python脚本来讲数据存储到influxdb中的方式来实现。
二,编写脚本提取Offset logSize Lag这三个值
1,给脚本创建一个独立的目录,里面会存放脚本和临时文件。
mkdir /usr/monitor
cd /usr/monitor
mkdir tmp
2,vim topic-collect.sh
#!/bin/bash
#txt文件命名规则:组-topic名字-检查项名字
source /etc/profile
/kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181 | awk '{print $4}' | grep -v Offset | awk '{sum+=$1}END{print sum}' > /usr/monitor/tmp/topic-group1-topicname1-Offset.txt
/kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181 | awk '{print $5}' | grep -v logSize | awk '{sum+=$1}END{print sum}' > /usr/monitor/tmp/topic-group1-topicname1-logSize.txt
/kafka_2.11-0.10.1.0/bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group group1 --topic topicname1 --zookeeper zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181 | awk '{print $6}' | grep -v Lag | awk '{sum+=$1}END{print sum}' > /usr/monitor/tmp/topic-group1-topicname1-Lag.txt
其中txt是用来存储计算各分片之和的值的文件。对TXT文件名进行规范化管理会让后期增加监控十分方便清晰。
3,vim kafka-lag-collect.py #这是一个python写的脚本,用来将数据存储到influxdb中,在此之前在influxdb中建立对应的库,在这里用到的库的名称是elkDB
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import time
import urllib2
import urllib
import json #Read the file
f = open('/usr/monitor/tmp/topic-group1-topicname1-Offset.txt')
Offset_sum = f.read()
f.close()
f = open('/usr/monitor/tmp/topic-group1-topicname1-logSize.txt')
logSize_sum = f.read()
f.close()
f = open('/usr/monitor/tmp/topic-group1-topicname1-Lag.txt')
Lag_sum = f.read()
f.close() dbreqdata = "group1,topic=topicname1,type=Offset value="+str(Offset_sum)+\
"\ngroup1,topic=topicname1,type=logSize value="+str(logSize_sum)+\
"\ngroup1,topic=topicname1,type=Lag value="+str(Lag_sum)
print dbreqdata
dbrequrl = "http://127.0.0.1:8086/write?db=elkDB"
dbreq= urllib2.Request(url = dbrequrl,data =dbreqdata)
print dbreq
urllib2.urlopen(dbreq)
4,脚本写完后给脚本增加一下可执行权限
chmod +x kafka-lag-collect.py
chmod +x topic-collect.sh
5,试着执行一下topic-collect.sh看能否执行成功
./topic-collect.sh
如果能执行成功的话,可以看到/usr/monitor/tmp/topic-group1-topicname1-Offset.txt里面已经有计算出来的offset总和了
6,试着执行一下kafka-lag-collect.py看能否执行成功
./kafka-lag-collect.py
如果能执行成功的话,就可以在influxdb里看到新建的表和相关数据了。
7,让topic-collect.sh脚本调用kafka-lag-collect.py脚本,这样可以避免添加两条crontab定时任务
echo "/usr/monitor/kafka-lag-collect.py" >> topic-collect.sh
8,添加定时任务,让脚本可以每分钟收集一次信息到influxdb
crontab -e
* * * * * /usr/monitor/topic-collect.sh
三,配置grafana展现数据
1,配置grafana数据源

2,新建图表
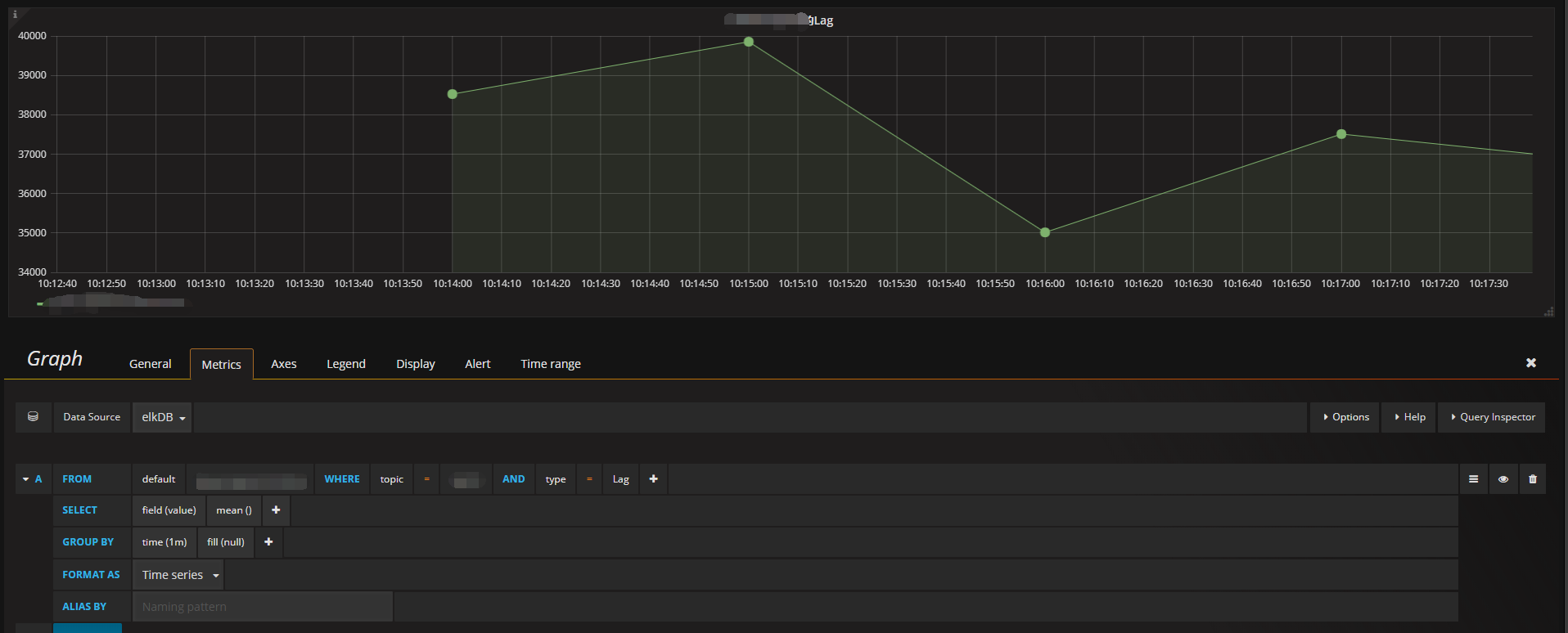
至此,就可以在grafana上看到监控的lag状态了。
kafka监控之topic的lag情况监控的更多相关文章
- 001使用smokeping监控idc机房网络质量情况
最近工作比较忙,也没有时间写博客,看到好友芮峰云最近一直在写博客,所以也手痒了,就先把之前的一些积累下来的文章分享给大家. 本文是介绍如何的使用smokeping来监控idc机房的网络质量情况,从监控 ...
- 限制UITextView的字数和字数监控,表情异常的情况和禁用表情
限制UITextView的字数和字数监控,表情异常的情况和禁用表情 3523FD80CC4350DE0AE7F89A8532B9A8.png 因为字数占一个字符,表情占两个字符.你要是限制15个字 ...
- Kafka vs RocketMQ—— Topic数量对单机性能的影响-转自阿里中间件
引言 上一期我们对比了三类消息产品(Kafka.RabbitMQ.RocketMQ)单纯发送小消息的性能,受到了程序猿们的广泛关注,其中大家对这种单纯的发送场景感到并不过瘾,因为没有任何一个网站的业务 ...
- (二)Kafka动态增加Topic的副本(Replication)
(二)Kafka动态增加Topic的副本(Replication) 1. 查看topic的原来的副本分布 [hadoop@sdf-nimbus-perf ~]$ le-kafka-topics.sh ...
- kubernetes之监控Prometheus实战--prometheus介绍--获取监控(一)
Prometheus介绍 Prometheus是一个最初在SoundCloud上构建的开源监控系统 .它现在是一个独立的开源项目,为了强调这一点,并说明项目的治理结构,Prometheus 于2016 ...
- 转:JMeter监控内存及CPU ——plugin插件监控被测系统资源方法
JMeter监控内存及CPU ——plugin插件监控被测系统资源方法 jmeter中也可以监控服务器的CPU和内存使用情况,但是需要安装一些插件还需要在被监测服务器上开启服务. 1.需要的插件准备 ...
- Kafka动态增加Topic的副本
一.kafka的副本机制 由于Producer和Consumer都只会与Leader角色的分区副本相连,所以kafka需要以集群的组织形式提供主题下的消息高可用.kafka支持主备复制,所以消息具备高 ...
- Kafka vs RocketMQ—— Topic数量对单机性能的影响
引言 上一期我们对比了三类消息产品(Kafka.RabbitMQ.RocketMQ)单纯发送小消息的性能,受到了程序猿们的广泛关注,其中大家对这种单纯的发送场景感到并不过瘾,因为没有任何一个网站的业务 ...
- Kafka设计解析(十)Kafka如何创建topic
转载自 huxihx,原文链接 Kafka如何创建topic? 目录 一.命令行部分 二.后台逻辑部分 Kafka创建topic命令很简单,一条命令足矣: bin/kafka-topics. --re ...
随机推荐
- Flink处理函数实战之四:窗口处理
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 转化dataframe中一组序列为时间序列的方法-to_datetime()的最新用法
一.to_datetime()的最新用法: hs300_hf['date'] = pd.to_datetime(hs300_hf['date']) hs300_hf.set_index('date', ...
- FL Studio通道预设之采样预览
FL Studio采样预览栏在采样设置窗口的最底端,它能很好地显示 出载入采样的波形也可以将波形显示改为频谱显示.它里面显示出的是经过预处理效果栏处理后的波形或频谱图.我们在波形显示器下面还可以看到波 ...
- 缓存模式(Cache Aside、Read Through、Write Through、Write Behind)
目录 概览 Cache-Aside 读操作 更新操作 缓存失效 缓存更新 Read-Through Write-Through Write-Behind 总结 参考 概览 缓存是一个有着更快的查询速度 ...
- Spring MVC系列-(5) AOP
5 AOP 5.1 什么是AOP AOP(Aspect-Oriented Programming,面向切面编程),可以说是OOP(Object-Oriented Programing,面向对象编程)的 ...
- iOS程序内实现版本更新
最近这段时间刚把手头里面的两个项目交付出去,很想写点东西但又不想随随便便的写些抒情的文字,其实生活中的很多事情.成长的路上遇到的很多问题,并非简简单单的抱怨.埋怨,用一种激情悲昂的情绪去逃避.去发泄所 ...
- Contest 1445
A \(a\) 中第 \(i\) 小的配 \(b\) 中第 \(i\) 大的. 限制相同,这样配最平均. 时间复杂度 \(O\left(tn\log n\right)\). B 最终的一百名至少是第一 ...
- HTML的基本术语
一.HTML含义1.根据W3C定义,HTML全称Hyper Text Markup Language: 超文本标记语言,用于定义文档的内容结构,该语言书写的代码通常会被浏览器解析执行.二.css含义1 ...
- 领域设计:Entity与VO
本文探讨如下内容: 什么是状态 什么是标识 什么是Entity 什么是VO(ValueObject) 在设计中如何识别Entity和VO 要理解Entity和VO,需要先理解两个概念:「状态」和「标识 ...
- 使用 Jasypt 加密 Spring Boot 配置文件
一.添加依赖包 <dependency> <groupId>com.github.ulisesbocchio</groupId> <artifactId> ...