Pytorch_第八篇_深度学习 (DeepLearning) 基础 [4]---欠拟合、过拟合与正则化
深度学习 (DeepLearning) 基础 [4]---欠拟合、过拟合与正则化
Introduce
在上一篇“深度学习 (DeepLearning) 基础 [3]---梯度下降法”中我们介绍了梯度下降的主要思想以及优化算法。本文将继续学习深度学习的基础知识,主要涉及:
- 欠拟合和过拟合
- 正则化
以下均为个人学习笔记,若有错误望指出。
欠拟合和过拟合
要理解欠拟合和过拟合,我们需要先清楚一对概念,即偏差和方差。
偏差和方差是深度学习中非常有用的一对概念,尤其是可以帮助我们理解模型的欠拟合和过拟合。
- 偏差:模型对于训练集的拟合能力,通俗理解来说,偏差代表模型能够正确预测训练集的程度(也就是说,模型在训练集上表现出的精度)。偏差越高代表模型在训练集上的精度越低。
- 方差:模型对于除训练集之外其他数据的预测能力,即泛化能力。通俗理解来说,方差代表模型能够正确预测测试集的程度(也就是说,模型在测试集上表现出的精度)。方差越高代表模型在各测试集上的精度明显低于训练集上的精度。
理解了偏差和方差的概念之后,那模型欠拟合和过拟合又是什么呢?
- 欠拟合:对应于高偏差的情况,即模型不能很好地拟合训练数据,在训练集上的预测精度很低。如下图所示(蓝色线为预测的模型,可以发现并不能很好滴拟合训练数据):
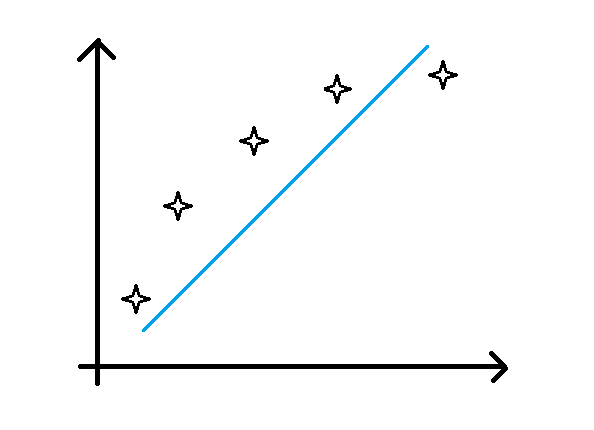
过拟合:对应于高方差的情况,即模型虽然在训练集上的精度很高,但是在测试集上的表现确差强人意。这是由于模型过度拟合了训练集,将训练集特有的性质当成了所有数据集的一般性质,导致其在其他数据集上的泛化能力特别差。如下图所示(蓝色线为预测的模型,可以发现似乎过度拟合了训练数据):

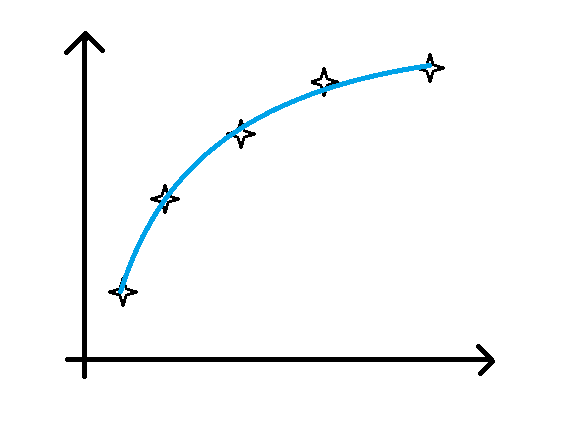
正确模型的拟合曲线如下图所示(与上面欠拟合和过拟合的曲线图对比,可以更好地帮助我们理解欠拟合和过拟合):
在理解了模型欠拟合和过拟合的概念之后,如果我们在训练模型的过程中遇到了这两类问题,我们怎么解决呢?
解决欠拟合:
(1) 使用更复杂的网络结构,如增加隐藏层数目,隐藏层结点数等。(因为神经网络如果层数和节点数足够的话,是可以模拟任何函数的)
(2) 训练更长时间,即增加神经网络模型的参数更新次数。(更新次数不够可能使得模型还没找到合适的参数使损失最小化,降低了模型精度)
(3) 使用其他更合适的神经网络架构,如前馈神经网络、卷积神经网络(CNN)、循环神经网络(RNN)、深度信念网络(DBN)等等(后续将进一步学习各种类型的神经网络);
解决过拟合:
(1) 使用更多的训练数据。(若是我们能把当前领域内所有的训练数据都拿来学习个够,那么我们的模型还会在这个领域的数据上表现差吗?不可能的,对吧!)
(2) 为模型添加正则化模块 (regularization)。(对于正则化概念以及为什么正则化能解决过拟合问题,在本文后续进行介绍)
(3) 使用其他更合适的神经网络架构。
对于以上策略一般的思考顺序,不论是欠拟合还是过拟合,当我们遇到了,都是优先考虑能不能使用上述中讲到的 (1) 和 (2) 来解决。如果不行的话再考虑 (3),因为重构一个神经网络的话相对于其他解决方法开销比较大。
正则化
直观理解:正则化是用来防止模型过拟合的一种方法,其做法是通过在模型损失函数中加入一项正则项,使得其在训练数据拟合损失和模型复杂度中达到一种权衡。
通常加入正则化的损失函数为如下形式:
\]
其中第一项为模型原本的损失函数,第二项
为正则化项,w为权值参数矩阵。若q=1,则为我们常用的L1正则化;若q=2,则为我们常用的L2正则化。
理解了正则化概念以及加入正则化的损失函数的形式之后,回归到一个更重要的问题,即为什么正则化能够防止模型过拟合呢?以下分别从三个角度来理解正则化在模型训练中的作用。
(1) 从模型拟合曲线的函数形式来看
为了回答上述问题,我们需要先理解过拟合情况下学习出来的拟合函数是什么样子的。可以看到上述过拟合部分的拟合曲线图(emm,就是扭来扭去的那张),图中的数据点实际上只需要一个二次函数就能够很好拟合了。但是从图中来看,过拟合情况下学习到的函数,肯定是大于二次的高次函数了。 假设该过拟合得到的函数为p次函数,如下所示:
\]
实际上正确的拟合函数为二次函数,如下所示:
\]
我们可以发现,要是我们能够更新权值参数w,使得w中的w0、w1和w2非0,而其余的权值均为0的话,我们是可以得到一个能够比较好地拟合上述曲线的模型的。而正则化就是起到上述这个作用(让一些不必要的权值参数为0),从而来防止模型过拟合的。
(2) 从神经网络模型的复杂度来看
现在回过头来看上述对于正则化的直观理解,里面有讲到模型复杂度,那模型复杂度是什么呀?我们可以将其通俗理解成权值参数的个数,因为网络的权值参数越多代表着神经网络更庞大(拥有更多的层和更多的节点以及更多的边),自然而然模型就更复杂了(如果网络中某条边的权重w为0的话,那这条边不就没了嘛,那模型不就更简单一些了嘛,这就是正则化要做的事吧,以上为个人理解)。
(3) 从加了正则化项的损失函数来看
现在再来看上述加入正则化的损失函数的一般形式,第一项为原本的损失函数,第二项为正则化项。以下分为两点来进行分析:
- 假设没有添加正则化项的话,模型训练的结果会使得损失函数尽可能小,也就是说使得模型拟合训练样本集的能力最大化,这就可能导致模型将训练样本集的一些特殊性质当成数据的普遍性质,使得模型泛化能力差,从而导致过拟合现象。
- 假设添加了正则项,正则项起到什么作用了?首先我们的目标是最小化损失函数,从某种程度上也需要最小化正则项,而由上述L1、L2正则项的形式来看,最小化正则项无非是把其中的某些不重要的权值参数wi设置为0,或者设置一个比较小的值。因此从这个层面上来理解,正则化也是通过将某些不重要权值参数设置为0来防止过拟合的。
需要说明的是:虽然L1正则化和L2正则化都可以防止模型过拟合,但是L1正则化相比于L2正则化会更容易产生稀疏权值矩阵(也就是说,权值矩阵中更多的权值为0)。至于原因,由于个人能力问题,可能解释不太清楚,可以参考知乎问题--L1 相比于 L2 为什么容易获得稀疏解?
Pytorch_第八篇_深度学习 (DeepLearning) 基础 [4]---欠拟合、过拟合与正则化的更多相关文章
- Pytorch_第六篇_深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数
深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [1]---监督学习和无监督学习 ...
- Pytorch_第七篇_深度学习 (DeepLearning) 基础 [3]---梯度下降
深度学习 (DeepLearning) 基础 [3]---梯度下降法 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数" ...
- Pytorch_第五篇_深度学习 (DeepLearning) 基础 [1]---监督学习与无监督学习
深度学习 (DeepLearning) 基础 [1]---监督学习与无监督学习 Introduce 学习了Pytorch基础之后,在利用Pytorch搭建各种神经网络模型解决问题之前,我们需要了解深度 ...
- Pytorch_第十篇_卷积神经网络(CNN)概述
卷积神经网络(CNN)概述 Introduce 卷积神经网络(convolutional neural networks),简称CNN.卷积神经网络相比于人工神经网络而言更适合于图像识别.语音识别等任 ...
- (zhuan) 126 篇殿堂级深度学习论文分类整理 从入门到应用
126 篇殿堂级深度学习论文分类整理 从入门到应用 | 干货 雷锋网 作者: 三川 2017-03-02 18:40:00 查看源网址 阅读数:66 如果你有非常大的决心从事深度学习,又不想在这一行打 ...
- 2020年深度学习DeepLearning技术实战班
深度学习DeepLearning核心技术实战2020年01月03日-06日 北京一.深度学习基础和基本思想二.深度学习基本框架结构 1,Tensorflow2,Caffe3,PyTorch4,MXNe ...
- 深度学习DeepLearning核心技术理论与实践
深度学习DeepLearning核心技术开发与应用时间地点:2019年11月01日-04日(北京) 联系人杨老师 电话(同微信)17777853361
- 2020年12月18号--21号 人工智能(深度学习DeepLearning)python、TensorFlow技术实战
深度学习DeepLearning(Python)实战培训班 时间地点: 2020 年 12 月 18 日-2020 年 12 月 21日 (第一天报到 授课三天:提前环境部署 电脑测试) 一.培训方式 ...
- 深度学习DeepLearning技术实战(12月18日---21日)
12月线上课程报名中 深度学习DeepLearning(Python)实战培训班 时间地点: 2020 年 12 月 18 日-2020 年 12 月 21日 (第一天报到 授课三天:提前环境部署 电 ...
随机推荐
- scala 数据结构(十一):流 Stream、视图 View、线程安全的集合、并行集合
1 流 Stream stream是一个集合.这个集合,可以用于存放无穷多个元素,但是这无穷个元素并不会一次性生产出来,而是需要用到多大的区间,就会动态的生产,末尾元素遵循lazy规则(即:要使用结果 ...
- 创建MongoDB副本集教程
今天有时间搞了一下mongoDB的副本集,遇到好多坑,写下此文,方便日后查阅! 本教程是在windows环境下安装测试的(我是本机一台 + 两台虚拟机) 本机:10.53.8.159 虚拟机一:10. ...
- DEX文件解析--6、dex文件字段和方法定义解析
一.前言 前几篇文章链接: DEX文件解析---1.dex文件头解析 DEX文件解析---2.Dex文件checksum(校验和)解析 DEX文件解析--3. ...
- react中实现可拖动div
把拖动div功能用react封装成class,在页面直接引入该class即可使用. title为可拖动区域.panel为要实现拖动的容器. 优化了拖动框超出页面范围的情况,也优化了拖动太快时鼠标超出可 ...
- 少儿编程:python趣味编程第二课,如何在pygame中写文字
python趣味编程第二课:本文仅针对8-16岁的青少年,所以流程是按如何去教好中小学生走的,并不适合成人找工作学习,因为进度也是按照青少年走的 大家好,我是C大叔,上一篇文章已经跟大家介绍了一款开发 ...
- python如何编写win程序
python可以编写win程序.win程序的格式是exe,下面我们就来看一下使用python编写exe程序的方法. 编写好python程序后py2exe模块即可将其打包为exe程序. 实际操作过程: ...
- DJANGO-天天生鲜项目从0到1-005-FastDFS与Nginx打造自定义文件存储系统
本项目基于B站UP主‘神奇的老黄’的教学视频‘天天生鲜Django项目’,视频讲的非常好,推荐新手观看学习 https://www.bilibili.com/video/BV1vt41147K8?p= ...
- 前端css 同级元素 设置不同样式 :first-child :nth-child() 的操作收藏
说明:最近在写前端vue 调样式的时候遇到了一个问题 同一个div下对多个同级别的<span>标签进行 边距设置 <div class="shuju-div"& ...
- vue学习(十三) 删除对象数组中的某个元素
//html <div id="app"> //v-for循环就不写了 每一条数据最后都有一个删除的超链 .prevent阻止默认的跳转行为 只执行点击事件 <a ...
- ~~并发编程(十一):GIL全局解释锁~~
进击のpython ***** 并发编程--GIL全局解释锁 这小节就是有些"大神"批判python语言不完美之处的开始 这一节我们要了解一下Cpython的GIL解释器锁的工作机 ...