NVIDIA GPU Volta架构简述
NVIDIA GPU Volta架构简述
本文摘抄自英伟达Volta架构官方白皮书:https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/sc18-tesla-democratization-tech-overview-r4-web.pdf
SM
- Volta架构目前仅GV100支持
Volta architecture comprises a single variant: GV100.
- Volta的每个SM包含4个线程束调度器。每个调度单元处理一个线程束组,并有一组专用的算术指令单元。
Each Turing SM includes 4 warp-scheduler units.Each scheduler handles a static set of warps and issues to a dedicated set of arithmetic instruction units.
- 指令在两个周期内执行,调度器可以在每个周期发出独立的指令。而核心数学运算相关指令如FMA需要4个周期的延迟,相比之下,Pascal需要六个周期。
Instructions are performed over two cycles, and the schedulers can issue independent instructions every cycle. Dependent instruction issue latency for core FMA math operations is four clock cycles, like Volta, compared to six cycles on Pascal.
- Volta提供了64个fp32核心,32个fp64核心,64个int32核心和8个混合精度Tensor Cores。V100最多提供了84个SM。不同于Pascal,Volta包含了专用的fp32和int32核心,这意味着Volta支持同时执行fp32和int32运算。
Similar to GP100, the GV100 SM provides 64 FP32 cores and 32 FP64 cores. The GV100 SM additionally includes 64 INT32 cores and 8 mixed-precision Tensor Cores. GV100 provides up to 84 SMs. Unlike Pascal GPUs, the GV100 SM includes dedicated FP32 and INT32 cores. This enables simultaneous execution of FP32 and INT32 operations.
- Volta对线程束中的每个线程提供了独立线程调用,现在可以支持支持线程束内部的线程同步__syncwarp()。
The Volta architecture introduces Independent Thread Scheduling among threads in a warp. This feature enables intra-warp synchronization patterns previously unavailable and simplifies code changes when porting CPU code.
- Turing架构上编程需要注意如下几点
- 使用带_sync后缀的线程束指令 (__shfl*, __any, __all, and __ballot) 代替原有的
To avoid data corruption, applications using warp intrinsics (__shfl*, __any, __all, and __ballot) should transition to the new, safe, synchronizing counterparts, with the *_sync suffix.
- 在需要线程束同步的位置插入__syncwarp()指令
Applications that assume reads and writes are implicitly visible to other threads in the same warp need to insert the new __syncwarp() warp-wide barrier synchronization instruction between steps where data is exchanged between threads via global or shared memory.
- 使用__syncthreads()指令时需要确保线程块中的所有线程必须都能达到此位置
Applications using __syncthreads() or the PTX bar.sync (and their derivatives) in such a way that a barrier will not be reached by some non-exited thread in the thread block must be modified to ensure that all non-exited threads reach the barrier.
- 与Pascal 架构相同,Volta支持最多64个线程束并行执行。
The maximum number of concurrent warps per SM remains the same as in Pascal (i.e., 64)
8.与Pascal 架构相同,Turing架构每SM拥有64k个32-bit寄存器,每个线程最多可使用255个寄存器,每SM支持最多32个线程块驻留,每SM的共享内存大小为96KB。
The register file size is 64k 32-bit registers per SM.
The maximum registers per thread is 255.
The maximum number of thread blocks per SM is 32.
Shared memory capacity per SM is 96KB, similar to GP104, and a 50% increase compared to GP100.
Tensor Cores
- 每个Tensor Core执行矩阵乘加操作:D = AxB + C,其中矩阵ABCD都是4x4大写,矩阵AB为fp16浮点数,矩阵CD可fp16或fp32。
Each Tensor Core performs the following operation: D = AxB + C, where A, B, C, and D are 4x4 matrices. The matrix multiply inputs A and B are FP16 matrices, while the accumulation matrices C and D may be FP16 or FP32 matrices.
- 在CUDA层面,线程束接口假设16x16矩阵分配到了线程束中32个线程。
At the CUDA level, the warp-level interface assumes 16x16 size matrices spanning all 32 threads of the warp.
- GV100的每个HBM2堆栈和4堆栈最多使用8个存储芯片,最大支持32GB的GPU内存,其中HBM2理论内存带宽高达900GB/s。
GV100 uses up to eight memory dies per HBM2 stack and four stacks, with a maximum of 32 GB of GPU memory.A faster and more efficient HBM2 implementation delivers up to 900 GB/s of peak memory bandwidth, compared to 732 GB/s for GP100.
- Volta架构中,L1缓存、纹理缓存、共享内存共享128KB缓存,Volta支持配置每SM 0、8、16、32、64、96 KB共享内存。
In Volta the L1 cache, texture cache, and shared memory are backed by a combined 128 KB data cache.Volta supports shared memory capacities of 0, 8, 16, 32, 64, or 96 KB per SM.
- Volta允许一个线程块使用全部的96KB的共享内存,当静态分配限制最多48KB,超过48KB则需要动态分配。
Volta enables a single thread block to address the full 96 KB of shared memory. To maintain architectural compatibility, static shared memory allocations remain limited to 48 KB, and an explicit opt-in is also required to enable dynamic allocations above this limit.
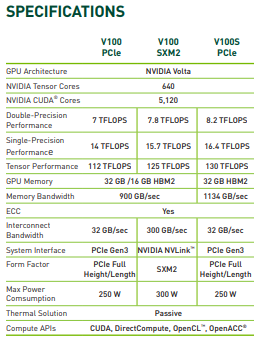
附1:Volta架构机型V100配置数据
NVIDIA GPU Volta架构简述的更多相关文章
- NVIDIA GPU Turing架构简述
NVIDIA GPU Turing架构简述 本文摘抄自Turing官方白皮书:https://www.nvidia.com/content/dam/en-zz/Solutions/design-vis ...
- NVIDIA GPU Pascal架构简述
NVIDIA GPU Pascal架构简述 本文摘抄自英伟达Pascal架构官方白皮书:https://www.nvidia.com/en-us/data-center/resources/pasca ...
- 深入GPU硬件架构及运行机制
目录 一.导言 1.1 为何要了解GPU? 1.2 内容要点 1.3 带着问题阅读 二.GPU概述 2.1 GPU是什么? 2.2 GPU历史 2.2.1 NV GPU发展史 2.2.2 NV GPU ...
- NVIDIA GPU的快速傅立叶变换
NVIDIA GPU的快速傅立叶变换 cuFFT库提供GPU加速的FFT实现,其执行速度比仅CPU的替代方案快10倍.cuFFT用于构建跨学科的商业和研究应用程序,例如深度学习,计算机视觉,计算物理, ...
- A100 GPU硬件架构
A100 GPU硬件架构 NVIDIA GA100 GPU由多个GPU处理群集(GPC),纹理处理群集(TPC),流式多处理器(SM)和HBM2内存控制器组成. GA100 GPU的完整实现包括以下单 ...
- NVIDIA Turing Architecture架构设计(下)
NVIDIA Turing Architecture架构设计(下) GDDR6 内存子系统 随着显示分辨率不断提高,着色器功能和渲染技术变得更加复杂,内存带宽和大小在 GPU 性能中扮演着更大的角色. ...
- NVIDIA Turing Architecture架构设计(上)
NVIDIA Turing Architecture架构设计(上) 在游戏市场持续增长和对更好的 3D 图形的永不满足的需求的推动下, NVIDIA 已经将 GPU 发展成为许多计算密集型应用的世界领 ...
- GPU体系架构(一):数据的并行处理
最近在了解GPU架构这方面的内容,由于资料零零散散,所以准备写两篇博客整理一下.GPU的架构复杂无比,这两篇文章也是从宏观的层面去一窥GPU的工作原理罢了 GPU根据厂商的不同,显卡型号的不同,GPU ...
- GPU体系架构(二):GPU存储体系
GPU是一个外围设备,本来是专门作为图形渲染使用的,但是随着其功能的越来越强大,GPU也逐渐成为继CPU之后的又一计算核心.但不同于CPU的架构设计,GPU的架构从一开始就更倾向于图形渲染和大规模数据 ...
随机推荐
- GoAccess分析Web日志
简介 为什么要用GoAccess? GoAccess 被设计成快速的并基于终端的日志分析工具.其核心理念是不需要通过 Web 浏览器就能快速分析并实时查看 Web 服务器的统计数据(这对于需要使用 S ...
- idea安装docker插件
Preferences->Plugins 根据上图安装docker插件,安装完成后可使用idea来管理docker项目了.docker运行项目请参加"Docker开发环境搭建" ...
- 一分钟开始持续集成之旅系列之:Java + GWT
作者:CODING - 朱增辉 前言 Google Web Toolkit(GWT)是一个开源.免费的 Web 开发框架,通过该框架,您可以使用 Java 构建复杂.高性能的 JavaScript 应 ...
- Mybatis各语句高级用法(未完待续)
更多的语法请参考官网 http://www.mybatis.org/mybatis-3/dynamic-sql.html# 环境:MySQL5.6,jdk1.8 建议:所有的参数加上@Param re ...
- loadRunnner中90%的响应时间
参考博客https://blog.csdn.net/lengyue_112/article/details/1095320?utm_source=blogxgwz4 LR在场景执行完了会出个报告,其中 ...
- SpringMVC 学习笔记(五)
47. 尚硅谷_佟刚_SpringMVC_文件上传.avi 参看博客https://www.cnblogs.com/hanfeihanfei/p/7931758.html相当的经典 我是陌生人关于Sp ...
- viewerjs 在html打开图片或打开pdf文件使用案例
开发者常用到在线访问pdf,txt,浏览图片的插件,这里推荐viewer.js这个插件,简单好用.它的核心亮点就是查看图片和pdf功能.老早以前就用过的,昨天一个小伙伴问我Android开发在线浏览p ...
- web如何测试
当我们负责web测试的时候,先了解B/S架构,然后分析如何开始执行测试,一般步骤:从功能测试,兼容测试,安全测试. 功能测试: 一.链接测试,链接是web应用系统的一个很重要的特征,主要是用于页面之间 ...
- Python 简明教程 --- 4,Python 变量与基本数据类型
微信公众号:码农充电站pro 个人主页:https://codeshellme.github.io 任何一个人都会写出能够让机器理解的代码,只有好的程序员才能写出人类可以理解的代码. -- Marti ...
- 入门大数据---Python基础
前言 由于AI的发展,包括Python集成了很多计算库,所以淡入了人们的视野,成为一个极力追捧的语言. 首先概括下Python中文含义是蟒蛇,它是一个胶水语言和一个脚本语言,胶水的意思是能和多种语言集 ...