SparkStreaming推测机制:面试被问遇到什么问题,说这个显水平!

背景
老刘最近晚上会刷刷牛客网的大数据开发面经,总是会看到一个高频的面试题,那就是你在学习过程中遇到过什么问题吗?
这个问题其实有点难回答,如果我说的太简单了,会不会让面试官觉得水平太低,那我应该讲什么东西呢?我一个自学的不可能遇到什么高级问题呀!
对于这个问题的答案网上也是众说纷纭,老刘也讲讲对这个问题的看法,分享一下自己的见解,欢迎各位伙伴前来battle!

过程
在寻找这个问题答案的过程中,老刘正好在学习spark框架的实时计算模块SparkStreaming,它里面就有一个非常经典的问题,关于推测机制的!
什么是推测机制?
如果有很多个task都在运行,很多task一下就完成了自己的任务,但是有一个task运行的很慢。在实时计算任务中,如果对实时性要求比较高,就算是两三秒也要在乎这些。
所以在sparkstreaming中有一个推测机制专门来解决这个运行的很慢的task。
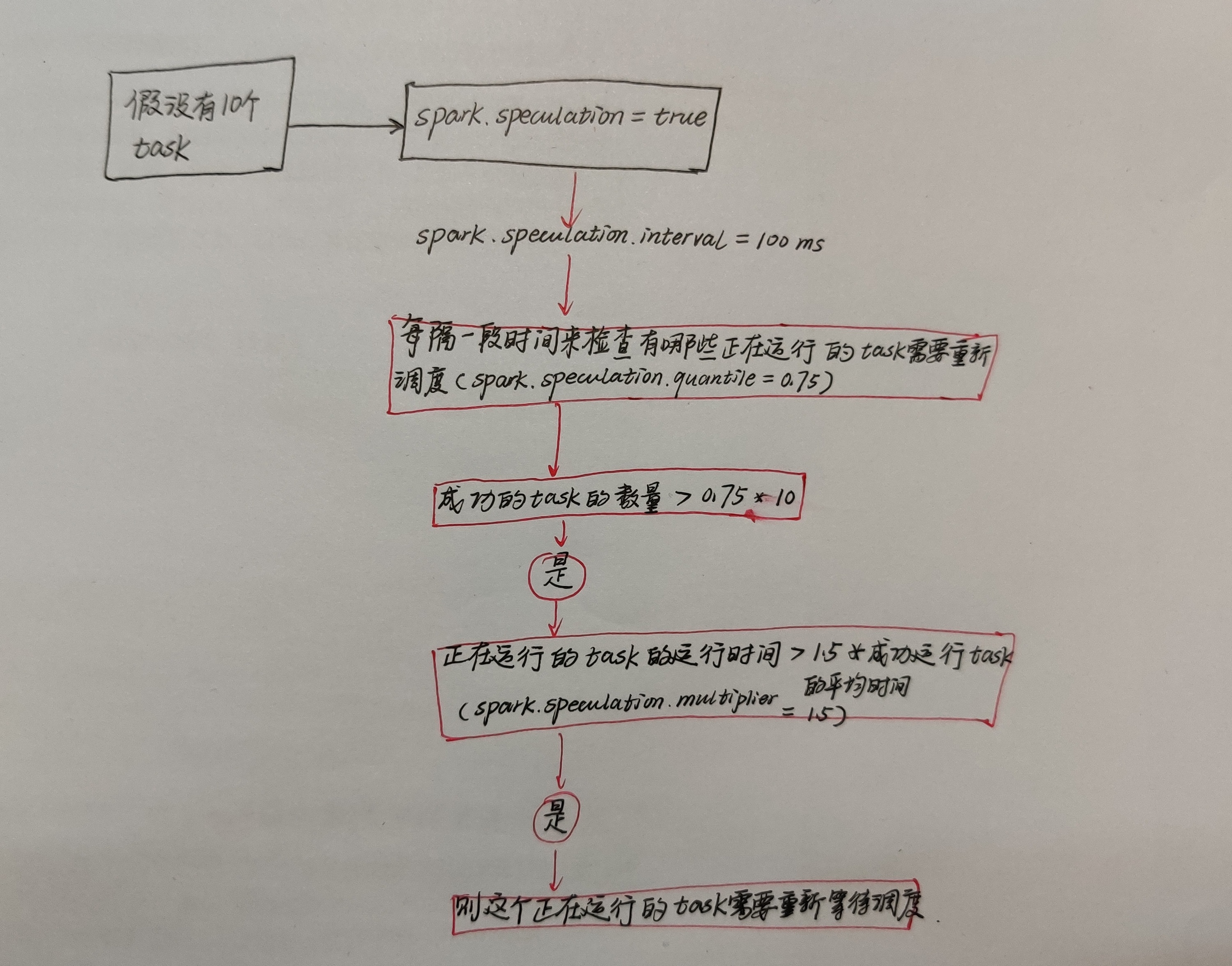
每隔一段时间来检查有哪些正在运行的task需要重新调度,假设总的task有10个,成功运行的task数量>0.75x10,正在运行的task的运行时间>1.5x成功运行task的平均时间,则这个正在运行的task需要重新等待调度。
但是这里有一个很严重的问题,最开始自学的时候发现了,接着在看一些机构视频里面也有讲到这个问题,说明老刘在自学过程中觉悟也在慢慢提高。

这个问题就是如果这个正在运行的task遇到数据倾斜怎么办?
假如有5个task,有一个task遇到了数据倾斜,但就算遇到数据倾斜(稍微有点数据倾斜,也没事),它也会完成任务,它需要6s,其他4个任务只需要1s。那开启推测机制后,这个任务好不容易运行到了2s,快要成功了,但遇到了推测机制,它就需要重新调度重新运行,下一次运行了3s,遇到推测机制就会重新运行,整个过程一直在循环,这就是老刘要说的问题!
某个培训机构视频里面的老师说这个问题还行,老刘自己也想到了看出了推测机制的这个缺点,所以就分享给大家!
解决
那开启推测机制遇到数据倾斜,怎么办?
我们可以采用一些解决数据倾斜的办法,老刘大致讲一下关于数据倾斜的几个解决方案:
1、如果发现导致数据倾斜的key就几个,而且对计算本身的影响并不大的话,就可以采用过滤少数导致倾斜的key
2、两阶段聚合,将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。但是这个方法只适用于聚合类的shuffle操作,不适合join类的shuffle操作。
3、对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。适用于两个数据量比较大的表进行join。
4、如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义,此时就只能使用这一种方案来解决问题了。将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同key”分散到多个task中去处理,而不是让一个task处理大量的相同key。

好啦,SparkStreaming推测机制讲完了,大家以后可以拿这块的内容回答面试官。如果有什么问题,可以联系公众号:努力的老刘,欢迎大家来和老刘battle!
SparkStreaming推测机制:面试被问遇到什么问题,说这个显水平!的更多相关文章
- 面试必问:JVM类加载机制详细解析
前言 在Java面试中,简历上有写JVM(Java虚拟机)相关的东西,JVM的类加载机制基本是面试必问的知识点. 类的加载和卸载 JVM是虚拟机的一种,它的指令集语言是字节码,字节码构成的文件是cla ...
- Zookeeper的选举机制和同步机制超详细讲解,面试经常问到!
前言 zookeeper相信大家都不陌生,很多分布式中间件都利用zk来提供分布式一致性协调的特性.dubbo官方推荐使用zk作为注册中心,zk也是hadoop和Hbase的重要组件.其他知名的开源中间 ...
- 面试常问的dubbo的spi机制到底是什么?
前言 dubbo是一款微服务开发框架,它提供了 RPC通信 与 微服务治理 两大关键能力.作为spring cloud alibaba体系中重要的一部分,随着spring cloud alibaba在 ...
- 最近面试被问到一个问题,AtomicInteger如何保证线程安全?
最近面试被问到一个问题,AtomicInteger如何保证线程安全?我查阅了资料 发现还可以引申到 乐观锁/悲观锁的概念,觉得值得一记. 众所周知,JDK提供了AtomicInteger保证对数字的操 ...
- linux驱动工程面试必问知识点
linux内核原理面试必问(由易到难) 简单型 1:linux中内核空间及用户空间的区别?用户空间与内核通信方式有哪些? 2:linux中内存划分及如何使用?虚拟地址及物理地址的概念及彼此之间的转化, ...
- 微软BI SSIS 2012 ETL 控件与案例精讲面试 200 问(SSIS 面试题,ETL 面试题)
开篇介绍 本自测与面试题出自 微软BI SSIS 2012 ETL 控件与案例精讲 (http://www.hellobi.com/course/21) 课程,对于学完本课程的每一课时和阅读完相关辅助 ...
- 面试官问:JS的this指向
前言 面试官出很多考题,基本都会变着方式来考察this指向,看候选人对JS基础知识是否扎实.读者可以先拉到底部看总结,再谷歌(或各技术平台)搜索几篇类似文章,看笔者写的文章和别人有什么不同(欢迎在评论 ...
- 面试官问你JS基本类型时他想知道什么?
面试的时候我们经常会被问答js的数据类型.大部分情况我们会这样回答包括:1.基本类型(值类型或者原始类型): Number.Boolean.String.NULL.Undefined以及ES6的Sym ...
- 互联网公司面试必问的Redis题目
Redis是一个非常火的非关系型数据库,火到什么程度呢?只要是一个互联网公司都会使用到.Redis相关的问题可以说是面试必问的,下面我从个人当面试官的经验,总结几个必须要掌握的知识点. 介绍:Redi ...
随机推荐
- springmvc<三> 异常解析链与视图解析链
1.1.7. Exceptions - 如果异常被Controller抛出,则DispatchServlet委托异常解析链来处理异常并提供处理方案(通常是一个错误的响应) spri ...
- FHQ简要笔记
前言 原文写于 XJ 集训day2 2020.1.19. 现在想想那时候连模板都还没写,只是刚刚理解就在那里瞎yy--之前果然还是太幼稚了. 今天刷训练指南发现全是 Treap 和 Splay ,不想 ...
- Codeforces Edu Round 62 A-E
A. Detective Book 模拟题,有一些细节需要注意. #include <cstdio> #include <iostream> #include <cmat ...
- Acwing 403. 平面
以一个这个环为基准,剩下的边可以放在圈外,也可以放在圈内,两种状态. 如果两条线段出现了环上意义的交叉即冲突,即不能同时放在圈外/内. 这是典型的 2-SAT 问题,因为关系传递是无向的,即逆命题与原 ...
- 部署在GitHub的个人博客如何绑定个人域名
前提是已经搭建好了自己的个人博客 如果想要搭建自己的个人博客可以来我的个人博客学习呀 地址 购买域名 首先想要绑定域名,总归需要去购买一个属于自己的域名吧,我是在腾讯云上面购买的域名(不是广告) 在腾 ...
- STL——容器(Set & multiset)的概念和特点
1. Set 和 multiset 的概念 set 和 multiset 是一个集合容器,其中 set 所包含的元素是唯一的,集合中的元素按一定的顺序排列.set 采用红黑树变体的数据结构实现,红黑树 ...
- Vue-组件化,父组件传子组件常见传值方式
前言 我们都知道vue核心之一:组件化,vue中万物皆组件,组件化我认为应该来至于模块化的设计思想,比如在模块化开发中,一个模块就是一个实现特定功能的独立的文件,有了模块我们就更方便去阅读代码,更方便 ...
- 【Electron Playground 系列】窗口篇
作者:Kurosaki 本文主要讲解Electron 窗口的 API 和一些在开发之中遇到的问题. 官方文档 虽然比较全面,但是要想开发一个商用级别的桌面应用必须对整个 Electron API 有 ...
- IOS中使用.xib文件封装一个自定义View
1.新建一个继承UIView的自定义view,假设类名叫做 MyAppVew #import <UIKit/UIKit.h> @class MyApp; @interface MyAppV ...
- Elasticsearch 新机型发布,性能提升30%
跨年迎双节,2020 年最后一次囤货的机会来啦! Elasticsearch Service 星星海新机型发布,更高性能,更低价格. 爆款机型限时特惠,帮助您顺畅体验 Elasticsearch 云上 ...