去年去阿里面试,被问到ArrayList和LinkedList,我是这样回答的!
前言
在一开始基础面的时候,很多面试官可能会问List集合一些基础知识,比如:
ArrayList默认大小是多少,是如何扩容的?ArrayList和LinkedList的底层数据结构是什么?ArrayList和LinkedList的区别?分别用在什么场景?- 为什么说
ArrayList查询快而增删慢? Arrays.asList方法后的List可以扩容吗?modCount在非线程安全集合中的作用?ArrayList和LinkedList的区别、优缺点以及应用场景
ArrayList(1.8)
ArrayList是由动态再分配的Object[]数组作为底层结构,可设置null值,是非线程安全的。
ArrayList成员属性
//默认的空的数组,在构造方法初始化一个空数组的时候使用
private static final Object[] EMPTY_ELEMENTDATA = {}; //使用默认size大小的空数组实例
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; //ArrayList底层存储数据就是通过数组的形式,ArrayList长度就是数组的长度。
transient Object[] elementData; //arrayList的大小
private int size;
那么ArrayList底层数据结构是什么呢?
很明显,使用动态再分配的Object[]数组作为ArrayList底层数据结构了,既然是使用数组实现的,那么数组特点就能说明为什么ArrayList查询快而增删慢?
因为数组是根据下标查询不需要比较,查询方式为:首地址+(元素长度*下标),基于这个位置读取相应的字节数就可以了,所以非常快;但是增删会带来元素的移动,增加数据会向后移动,删除数据会向前移动,导致其效率比较低。
ArrayList的构造方法
- 带有初始化容量的构造方法
- 无参构造方法
- 参数为
Collection类型的构造器
//带有初始化容量的构造方法
public ArrayList(int initialCapacity) {
//参数大于0,elementData初始化为initialCapacity大小的数组
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
//参数小于0,elementData初始化为空数组
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
//参数小于0,抛出异常
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
} //无参构造方法
public ArrayList() {
//在1.7以后的版本,先构造方法中将elementData初始化为空数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA
//当调用add方法添加第一个元素的时候,会进行扩容,扩容至大小为DEFAULT_CAPACITY=10
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
那么ArrayList默认大小是多少?
从无参构造方法中可以看出,一开始默认为一个空的实例elementData为上面的DEFAULTCAPACITY_EMPTY_ELEMENTDATA,当添加第一个元素的时候会进行扩容,扩容大小就是上面的默认容量DEFAULT_CAPACITY为10
ArrayList的Add方法
boolean add(E):默认直接在末尾添加元素void add(int,E):在特定位置添加元素,也就是插入元素boolean addAll(Collection<? extends E> c):添加集合boolean addAll(int index, Collection<? extends E> c):在指定位置后添加集合
boolean add(E)
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
通过ensureCapacityInternal方法为确定容量大小方法。在添加元素之前需要确定数组是否能容纳下,size是数组中元素个数,添加一个元素size+1。然后再数组末尾添加元素。
其中,ensureCapacityInternal方法包含了ArrayList扩容机制grow方法,当前容量无法容纳下数据时1.5倍扩容,进行:
private void ensureCapacityInternal(int minCapacity) {
//判断当前的数组是否为默认设置的空数据,是否取出最小容量
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//包括扩容机制grow方法
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
//记录着集合的修改次数,也就每次add或者remove它的值都会加1
modCount++;
//当前容量容纳不下数据时(下标超过时),ArrayList扩容机制:扩容原来的1.5倍
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//ArrayList扩容机制:扩容原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
ArrayList是如何扩容的?
根据当前的容量容纳不下新增数据时,ArrayList会调用grow进行扩容:
//相当于int newCapacity = oldCapacity + oldCapacity/2
int newCapacity = oldCapacity + (oldCapacity >> 1);
扩容原来的1.5倍。
void add(int,E)
public void add(int index, E element) {
//检查index也就是插入的位置是否合理,是否存在数组越界
rangeCheckForAdd(index);
//机制和boolean add(E)方法一样
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
ArrayList的删除方法
- remove(int):通过删除指定位置上的元素,
- remove(Object):根据元素进行删除,
- clear():将
elementData中每个元素都赋值为null,等待垃圾回收将这个给回收掉, - removeAll(collection c):批量删除。
remove(int)
public E remove(int index) {
//检查下标是否超出数组长度,造成数组越界
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
//算出数组需要移动的元素数量
int numMoved = size - index - 1;
if (numMoved > 0)
//数组数据迁移,这样会导致删除数据时,效率会慢
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将--size上的位置赋值为null,让gc(垃圾回收机制)更快的回收它。
elementData[--size] = null; // clear to let GC do its work
//返回删除的元素
return oldValue;
}
为什么说ArrayList删除元素效率低?
因为删除数据需要将数据后面的元素数据迁移到新增位置的后面,这样导致性能下降很多,效率低。
remove(Object)
public boolean remove(Object o) {
//如果需要删除数据为null时,会让数据重新排序,将null数据迁移到数组尾端
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
//删除数据,并迁移数据
fastRemove(index);
return true;
}
} else {
//循环删除数组中object对象的值,也需要数据迁移
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
可以看出,arrayList是可以存放null值。
LinkedList(1.8)
LinkedList是一个继承于AbstractSequentialList的双向链表。它也可以被当做堆栈、队列或双端队列进行使用,而且LinkedList也为非线程安全, jdk1.6使用的是一个带有 header节头结点的双向循环链表, 头结点不存储实际数据 ,在1.6之后,就变更使用两个节点first、last指向首尾节点。
LinkedList的主要属性
//链表节点的个数
transient int size = 0;
//链表首节点
transient Node<E> first;
//链表尾节点
transient Node<E> last;
//Node节点内部类定义
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev; Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问
LinkedList构造方法
无参构造函数, 默认构造方法声明也不做,first和last节点会被默认初始化为null。
*
/** Constructs an empty list. \*/* public LinkedList() {}
LinkedList插入
由于LinkedList由双向链表作为底层数据结构,因此其插入无非由三大种
尾插:
add(E e)、addLast(E e)、addAll(Collection<? extends E> c)头插:
addFirst(E e)中插:
add(int index, E element)可以从源码看出,在链表首尾添加元素很高效,在中间添加元素比较低效,首先要找到插入位置的节点,在修改前后节点的指针。
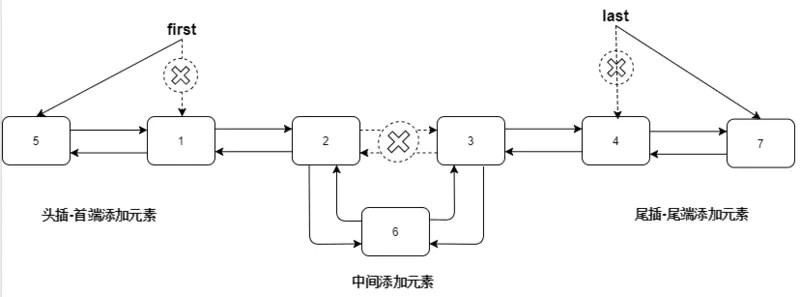
尾插-add(E e)和addLast(E e)
//常用的添加元素方法
public boolean add(E e) {
//使用尾插法
linkLast(e);
return true;
} //在链表尾部添加元素
public void addLast(E e) {
linkLast(e);
} //在链表尾端添加元素
void linkLast(E e) {
//尾节点
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
//判断是否是第一个添加的元素
//如果是将新节点赋值给last
//如果不是把原首节点的prev设置为新节点
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
//将集合修改次数加1
modCount++;
}
头插-addFirst(E e)
public void addFirst(E e) {
//在链表头插入指定元素
linkFirst(e);
}
private void linkFirst(E e) {
//获取头部元素,首节点
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
//链表头部为空,(也就是链表为空)
//插入元素为首节点元素
// 否则就更新原来的头元素的prev为新元素的地址引用
if (f == null)
last = newNode;
else
f.prev = newNode;
//
size++;
modCount++;
}
中插-add(int index, E element)
当index不为首尾的的时候,实际就在链表中间插入元素。
// 作用:在指定位置添加元素
public void add(int index, E element) {
// 检查插入位置的索引的合理性
checkPositionIndex(index); if (index == size)
// 插入的情况是尾部插入的情况:调用linkLast()。
linkLast(element);
else
// 插入的情况是非尾部插入的情况(中间插入):linkBefore
linkBefore(element, node(index));
} private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
} private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
} void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev; // 得到插入位置元素的前继节点
final Node<E> newNode = new Node<>(pred, e, succ); // 创建新节点,其前继节点是succ的前节点,后接点是succ节点
succ.prev = newNode; // 更新插入位置(succ)的前置节点为新节点
if (pred == null)
// 如果pred为null,说明该节点插入在头节点之前,要重置first头节点
first = newNode;
else
// 如果pred不为null,那么直接将pred的后继指针指向newNode即可
pred.next = newNode;
size++;
modCount++;
}
LinkedList 删除
删除和插入一样,其实本质也是只有三大种方式,
删除首节点:
removeFirst()删除尾节点:
removeLast()删除中间节点 :
remove(Object o)、remove(int index)在首尾节点删除很高效,删除中间元素比较低效要先找到节点位置,再修改前后指针指引。
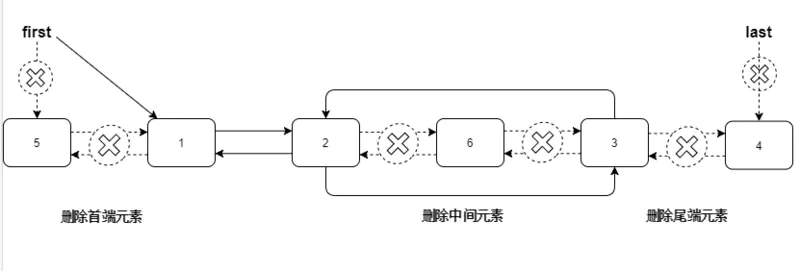
删除中间节点-remove(int index)和remove(Object o)
remove(int index)和remove(Object o)都是使用删除指定节点的unlink删除元素
public boolean remove(Object o) {
//因为LinkedList允许存在null,所以需要进行null判断
if (o == null) {
//从首节点开始遍历
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
//调用unlink方法删除指定节点
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
//删除指定位置的节点,其实和上面的方法差不多
//通过node方法获得指定位置的节点,再通过unlink方法删除
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
//删除指定节点
E unlink(Node<E> x) {
//获取x节点的元素,以及它上一个节点,和下一个节点
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//如果x的上一个节点为null,说明是首节点,将x的下一个节点设置为新的首节点
//否则将x的上一节点设置为next,将x的上一节点设为null
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
//如果x的下一节点为null,说明是尾节点,将x的上一节点设置新的尾节点
//否则将x的上一节点设置x的上一节点,将x的下一节点设为null
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
//将x节点的元素值设为null,等待垃圾收集器收集
x.item = null;
//链表节点个数减1
size--;
//将集合修改次数加1
modCount++;
//返回删除节点的元素值
return element;
}
删除首节点-removeFirst()
//删除首节点
public E remove() {
return removeFirst();
}
//删除首节点
public E removeFirst() {
final Node<E> f = first;
//如果首节点为null,说明是空链表,抛出异常
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
//删除首节点
private E unlinkFirst(Node<E> f) {
//首节点的元素值
final E element = f.item;
//首节点的下一节点
final Node<E> next = f.next;
//将首节点的元素值和下一节点设为null,等待垃圾收集器收集
f.item = null;
f.next = null; // help GC
//将next设置为新的首节点
first = next;
//如果next为null,说明说明链表中只有一个节点,把last也设为null
//否则把next的上一节点设为null
if (next == null)
last = null;
else
next.prev = null;
//链表节点个数减1
size--;
//将集合修改次数加1
modCount++;
//返回删除节点的元素值
return element;
}
删除尾节点-removeLast()
//删除尾节点
public E removeLast() {
final Node<E> l = last;
//如果首节点为null,说明是空链表,抛出异常
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node<E> l) {
//尾节点的元素值
final E element = l.item;
//尾节点的上一节点
final Node<E> prev = l.prev;
//将尾节点的元素值和上一节点设为null,等待垃圾收集器收集
l.item = null;
l.prev = null; // help GC
//将prev设置新的尾节点
last = prev;
//如果prev为null,说明说明链表中只有一个节点,把first也设为null
//否则把prev的下一节点设为null
if (prev == null)
first = null;
else
prev.next = null;
//链表节点个数减1
size--;
//将集合修改次数加1
modCount++;
//返回删除节点的元素值
return element;
}
其他方法也是类似的,比如查询方法 LinkedList提供了get、getFirst、getLast等方法获取节点元素值。
modCount属性的作用?
modCount属性代表为结构性修改( 改变list的size大小、以其他方式改变他导致正在进行迭代时出现错误的结果)的次数,该属性被Iterator以及ListIterator的实现类所使用,且很多非线程安全使用modCount属性。
初始化迭代器时会给这个modCount赋值,如果在遍历的过程中,一旦发现这个对象的modCount和迭代器存储的modCount不一样,Iterator或者ListIterator 将抛出ConcurrentModificationException异常,
这是jdk在面对迭代遍历的时候为了避免不确定性而采取的 fail-fast(快速失败)原则:
在线程不安全的集合中,如果使用迭代器的过程中,发现集合被修改,会抛出ConcurrentModificationExceptions错误,这就是fail-fast机制。对集合进行结构性修改时,modCount都会增加,在初始化迭代器时,modCount的值会赋给expectedModCount,在迭代的过程中,只要modCount改变了,int expectedModCount = modCount等式就不成立了,迭代器检测到这一点,就会抛出错误:urrentModificationExceptions。
总结
ArrayList和LinkedList的区别、优缺点以及应用场景
区别:
ArrayList是实现了基于动态数组的数据结构,LinkedList是基于链表结构。- 对于随机访问的
get和set方法查询元素,ArrayList要优于LinkedList,因为LinkedList循环链表寻找元素。 - 对于新增和删除操作
add和remove,LinkedList比较高效,因为ArrayList要移动数据。
优缺点:
- 对
ArrayList和LinkedList而言,在末尾增加一个元素所花的开销都是固定的。对ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是 统一的,分配一个内部Entry对象。 - 在
ArrayList集合中添加或者删除一个元素时,当前的列表移动元素后面所有的元素都会被移动。而LinkedList集合中添加或者删除一个元素的开销是固定的。 LinkedList集合不支持 高效的随机随机访问(RandomAccess),因为可能产生二次项的行为。ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
应用场景:
ArrayList使用在查询比较多,但是插入和删除比较少的情况,而LinkedList用在查询比较少而插入删除比较多的情况
去年去阿里面试,被问到ArrayList和LinkedList,我是这样回答的!的更多相关文章
- 当面试官问我ArrayList和LinkedList哪个更占空间时,我这么答让他眼前一亮
前言 今天介绍一下Java的两个集合类,ArrayList和LinkedList,这两个集合的知识点几乎可以说面试必问的. 对于这两个集合类,相信大家都不陌生,ArrayList可以说是日常开发中用的 ...
- 去年去阿里面试,被问到java 多线程,我是这样手撕面试官的
1.多线程的基本概念 1.1进程与线程 程序:是为完成特定任务,用某种语言编写的一组指令的集合,即一段静态代码,静态对象. 进程:是程序的一次执行过程,或是正在运行的一个程序,是一个动态的过程,每个程 ...
- 去年去阿里面试,面试官居然问我Java类和对象,我是这样回答的!
1.谈谈你对Java面向对象的理解? 面向对象就是把构成问题的事务分解成一个个对象,建立对象的目的不是一个步骤,而是为了描述一个事务在解决问题中的行为.类是面向对象的一个重要概念,类是很多个具有相同属 ...
- 当阿里面试官问我:Java创建线程有几种方式?我就知道问题没那么简单
这是最新的大厂面试系列,还原真实场景,提炼出知识点分享给大家. 点赞再看,养成习惯~ 微信搜索[武哥聊编程],关注这个 Java 菜鸟. 昨天有个小伙伴去阿里面试实习生岗位,面试官问他了一个老生常谈的 ...
- 阿里面试这样问:redis 为什么把简单的字符串设计成 SDS?
2021开工第一天,就有小伙伴私信我,还给我分享了一道他面阿里的redis题(这家伙绝比已经拿到年终奖了),我看了以后觉得挺有意思,题目很简单,是那种典型的似懂非懂,常常容易被大家忽略的问题.这里整理 ...
- 阿里面试100%问到,JVM性能调优篇
JVM 调优概述 性能定义 吞吐量 - 指不考虑 GC 引起的停顿时间或内存消耗,垃圾收集器能支撑应用达到的最高性能指标. 延迟 - 其度量标准是缩短由于垃圾啊收集引起的停顿时间或者完全消除因垃圾收集 ...
- Java面试题之HashMap阿里面试必问知识点,你会吗?
面试官Q1:你用过HashMap,你能跟我说说它的数据结构吗? HashMap作为一种容器类型,无论你是否了解过其内部的实现原理,它的大名已经频频出现在各种互联网Java面试题中了.从基本的使用角度来 ...
- 阿里面试:问springBoot自动装配我这样回答的,面试官对我竖起了大拇指
引言 最近有个读者在面试,面试中被问到了这样一个问题"看你项目中用到了springboot,你说下springboot的自动配置是怎么实现的?"这应该是一个springboot里面 ...
- 面试必问之ArrayList
ArrayList概述 (1)ArrayList 是一种变长的集合类,基于定长数组实现. (2)ArrayList 允许空值和重复元素,当往 ArrayList 中添加的元素数量大于其底层数组容量时, ...
随机推荐
- 安装Linux注意事项
网络配置NAT Worstation 生成虚拟网卡,编辑虚拟网络中子网IP地址为10网段内部地址,避免冲突. Linux命令 查看主机IP地址 [root@C8 ~]# hostname -I 19 ...
- [C#] (原创)一步一步教你自定义控件——03,SwitchButton(开关按钮)
一.前言 技术没有先进与落后,只有合适与不合适. 本篇的自定义控件是:开关按钮(SwitchButton). 开关按钮非常简单,实现方式也多种多样,比如常见的:使用两张不同的按钮图片,代表开和关,然后 ...
- RocketMQ 4.7.1 环境搭建、集群、MQ整合SpringBoot
导读 之前学过ActiveMQ但是并发量不是很大点我直达,所以又学阿里开源的RocketMQ,据说队列可以堆积亿级别.下面是网上找的消息队列对比图,仅供参考 部署 官网 点我直达 前置条件 推荐使用6 ...
- linux压缩和解压文件命令
tar 解包:tar zxvf filename.tar 打包:tar czvf filename.tar dirnamegz命令 解压1:gunzip filename.gz 解压2:gzi ...
- 转 js调用提交表单。
今天做网银支付的时候,需要做到点击支付的时候提交订单,然后新窗口打开支付界面. 思路1:window.open(''),这个直接被pass了,因为银行的服务一般都是需要post数据的.就算是可以用ge ...
- 专题五:redis的数据类型之set
一.基本简介 现在出现了新的查询需求:存储大量数据的同时,还需要在查询方面提供更高的效率.虽然list满足存储大量的数据,也可以通过索引来进行访问,但是list底层是双向链表的结构,在查询上的效率并没 ...
- 完美解决CentOS8 yum安装AppStream报错,更新yum后无法makecache的问题
问题 CentOS 8 yum安装软件时,提示无法从AppStream下载 [root@C8-3 ~]# yum -y install httpd mariadb-server mariadb php ...
- 使用scrapy框架模拟登录
scrapy模拟登录 注意:模拟登陆时,必须保证settings.py里的COOKIES_ENABLED(Cookies中间件) 处于开启状态 COOKIES_ENABLED = True 或# CO ...
- [Luogu P4215] 踩气球 (线段树)
题面 传送门:https://www.luogu.org/problemnew/show/P4215 Solution 这题十分有意思. 首先,我们可以先想想离线做法,因为在线做法可以从离线做法推出. ...
- 关于windows下activeMQ的安装
1.下载地址http://activemq.apache.org/activemq-5154-release.html 2.修改登录账号和密码,在配置文件jetty-realm.properties中 ...