MongoDB分片集群部署方案
前言
副本集部署是对数据的冗余和增加读请求的处理能力,却不能提高写请求的处理能力;关键问题是随着数据增加,单机硬件配置会成为性能的瓶颈。而分片集群可以很好的解决这一问题,通过水平扩展来提升性能。分片部署依赖三个组件:mongos(路由),config(配置服务),shard(分片)
shard:每个分片存储被分片的部分数据,同时每个分片又可以部署成副本集
mongos:作为查询路由器,为客户端与分片集群之间通讯的提供访问接口
config server:配置服务器存储这个集群的元数据和配置信息
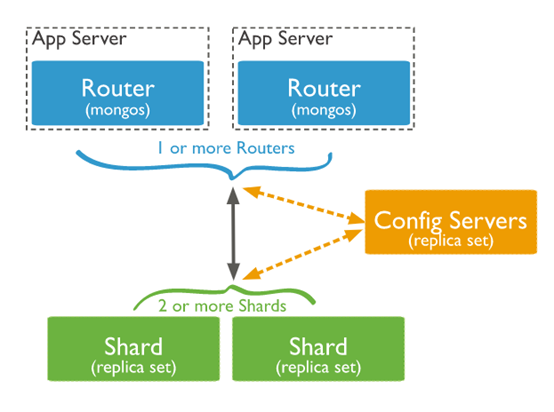
部署规划
1. 服务分布
3台机器:mongodbA 192.168.128.128,mongodbB 192.168.128.129,mongodbB 192.168.128.130
3个分片,分片和配置服务部署成副本集,如下图:

副本集部署时,当节点数超过3个时候,需要配置仲裁节点;这里为了演示节点分布,所以配置了仲裁节点。
在实际生产环境部署的时候,可以根据机器资源灵活配置。
2. 目录规划
mongos:
/data/mongo-cluster/mongos/log
config:
/data/mongo-cluster/config/data
/data/mongo-cluster/config/log
shard1:
/data/mongo-cluster/shard1/data
/data/mongo-cluster/shard1/log
shard2:
/data/mongo-cluster/shard2/data
/data/mongo-cluster/shard2/log
shard3:
/data/mongo-cluster/shard3/data
/data/mongo-cluster/shard3/log
3. 端口规划
mongos: 21000,22000,23000
config: 31000,32000,33000
shard1: 41010,41020,41030
shard2: 42010,42020,42030
shard3: 43010,43020,43030
准备工作
1. 下载安装包
参考网上教程
本文档安装版本:
db version v3.6.4
git version: d0181a711f7e7f39e60b5aeb1dc7097bf6ae5856
OpenSSL version: OpenSSL 1.0.2g 1 Mar 2016
allocator: tcmalloc
modules: enterprise
build environment:
distmod: ubuntu1604
distarch: x86_64
target_arch: x86_64
2. 部署目录
mkdir /data/mongo-cluster -p
mkdir /data/mongo-cluster/mongos/log -p
mkdir /data/mongo-cluster/shard1/data -p
mkdir /data/mongo-cluster/shard1/log -p
mkdir /data/mongo-cluster/shard2/data -p
mkdir /data/mongo-cluster/shard2/log -p
mkdir /data/mongo-cluster/shard3/data -p
mkdir /data/mongo-cluster/shard3/log -p
mkdir /data/mongo-cluster/config/log -p
mkdir /data/mongo-cluster/config/data -p
mkdir /data/mongo-cluster/keyfile -p
3. 创建配置文件
cd /data/mongo-cluster
A. mongod 配置文件 mongo_node.conf
mongo_node.conf 作为mongod实例共享的配置文件,内容如下:
# mongod.conf # for documentation of all options, see:
# http://docs.mongodb.org/manual/reference/configuration-options/ # Where and how to store data.
storage:
# dbPath: /var/lib/mongodb
journal:
enabled: true
engine: wiredTiger
# mmapv1:
# wiredTiger: # where to write logging data.
systemLog:
destination: file
logAppend: true
# path: /var/log/mongodb/mongod.log # network interfaces
#net:
# port: 27017
# bindIp: 127.0.0.1,192.168.147.128
# bindIpAll: true # how the process runs
processManagement:
timeZoneInfo: /usr/share/zoneinfo
fork: true security:
authorization: "enabled" #operationProfiling: #replication: #sharding: ## Enterprise-Only Options: #auditLog: #snmp:
B. mongos 配置文件 mongos.conf
systemLog:
destination: file
logAppend: true
processManagement:
fork: true
4. 创建keyfile文件
cd /data/mongo-cluster
mkdir keyfile
openssl rand -base64 756 > mongo.key
chmod 400 mongo.key
集群搭建
mongoCluster.sh内容:
#!/bin/sh
WORK_DIR=/data/mongo-cluster
KEYFILE=$WORK_DIR/keyfile/mongo.key
CONFFILE=$WORK_DIR/mongo_node.conf
MONGOS_CONFFILE=$WORK_DIR/mongos.conf
MONGOD=/usr/bin/mongod
MONGOS=/usr/bin/mongos mongos_start_cmd()
{
$MONGOS --port 21000 --bind_ip 127.0.0.1,192.168.128.130 --configdb configReplSet/192.168.128.130:31000,192.168.128.129:32000,192.168.128.128:33000 --keyFile $KEYFILE --pidfilepath $WORK_DIR/mongos.pid --logpath $WORK_DIR/mongos/log/mongo.log --config $MONGOS_CONFFILE
return $?
} config_start_cmd()
{
$MONGOD --port 31000 --bind_ip 127.0.0.1,192.168.128.130 --configsvr --replSet configReplSet --keyFile $KEYFILE --dbpath $WORK_DIR/config/data --pidfilepath $WORK_DIR/mongo_config.pid --logpath $WORK_DIR/config/log/mongo.log --config $CONFFILE
return $?
} shard_start_cmd()
{
$MONGOD --port 41010 --bind_ip 127.0.0.1,192.168.128.130 --shardsvr --replSet shard1 --keyFile $KEYFILE --dbpath $WORK_DIR/shard1/data --pidfilepath $WORK_DIR/mongo_shard1.pid --logpath $WORK_DIR/shard1/log/mongo.log --config $CONFFILE &&\
$MONGOD --port 42010 --bind_ip 127.0.0.1,192.168.128.130 --shardsvr --replSet shard2 --keyFile $KEYFILE --dbpath $WORK_DIR/shard2/data --pidfilepath $WORK_DIR/mongo_shard2.pid --logpath $WORK_DIR/shard2/log/mongo.log --config $CONFFILE &&\
$MONGOD --port 43010 --bind_ip 127.0.0.1,192.168.128.130 --shardsvr --replSet shard3 --keyFile $KEYFILE --dbpath $WORK_DIR/shard3/data --pidfilepath $WORK_DIR/mongo_shard3.pid --logpath $WORK_DIR/shard3/log/mongo.log --config $CONFFILE
} mongos_server()
{
case $1 in
start)
mongos_start_cmd
;;
stop)
echo "stoping mongos server..."
cat mongos.pid | xargs kill -9
;;
restart)
echo "stoping mongos server..."
cat mongos.pid | xargs kill -9
echo "setup mongos server..."
mongos_start_cmd
;;
status)
pid=`cat mongos.pid`
if ps -ef | grep -v "grep" | grep $pid > /dev/null 2>&1; then
status="running"
else
status="stoped"
fi
echo "mongos server[$pid] status: ${status}"
;;
*)
echo "Usage: /etc/init.d/samba {start|stop|reload|restart|force-reload|status}"
;;
esac
} config_server()
{
case $1 in
start)
config_start_cmd
;;
stop)
echo "stoping config server..."
cat mongo_config.pid | xargs kill -9
;;
restart)
echo "stoping config server..."
cat mongo_config.pid | xargs kill -9;
echo "setup config server..."
config_start_cmd
;;
status)
pid=`cat mongo_config.pid`
if ps -ef | grep -v "grep" | grep $pid > /dev/null 2>&1; then
status="running"
else
status="stoped"
fi
echo "config server[$pid] status: ${status}"
;;
*)
echo "Usage: `basename $0` config {start|stop|reload|restart|force-reload|status}"
;;
esac
} shard_server()
{
case $1 in
start)
shard_start_cmd
;;
stop)
cat mongo_shard1.pid | xargs kill -9;
cat mongo_shard2.pid | xargs kill -9;
cat mongo_shard3.pid | xargs kill -9;
;;
restart)
cat mongo_shard1.pid | xargs kill -9;
cat mongo_shard2.pid | xargs kill -9;
cat mongo_shard3.pid | xargs kill -9;
shard_start_cmd
;;
status)
pid=`cat mongo_shard1.pid`
if ps -ef | grep -v "grep" | grep $pid > /dev/null 2>&1; then
status="running"
else
status="stoped"
fi
echo "shard1 server[$pid] status: ${status}"
#shard2
pid=`cat mongo_shard2.pid`
if ps -ef | grep -v "grep" | grep $pid > /dev/null; then
status="running"
else
status="stoped"
fi
echo "shard2 server[$pid] status: ${status}"
#shard3
pid=`cat mongo_shard3.pid`
if ps -ef | grep -v "grep" | grep $pid > /dev/null; then
status="running"
else
status="stoped"
fi
echo "shard3 server[$pid] status: ${status}"
;;
*)
echo "Usage: /etc/init.d/samba {start|stop|reload|restart|force-reload|status}"
;;
esac
} all_server ()
{
case $1 in
start)
mongos_server start
config_server start
shard_server start
;;
stop)
mongos_server stop
config_server stop
shard_server stop
cat mongo_config.pid | xargs kill -9
cat mongo_shard1.pid | xargs kill -9
cat mongo_shard2.pid | xargs kill -9
cat mongo_shard3.pid | xargs kill -9
;;
restart)
mongos_server restart
config_server restart
shard_server restart
;;
status)
mongos_server status
config_server status
shard_server status
exit 0
;;
*)
echo "Usage: $0 {all|mongos|config|shard} {start|stop|reload|restart|force-reload|status}"
exit 1
;;
esac
} #set -e case $1 in
all)
all_server $2
;;
mongos)
mongos_server $2
;;
config)
config_server $2
;;
shard)
shard_server $2
;;
*)
echo "Usage: `basename $0` {all|mongos|config|shard} {start|stop|reload|restart|force-reload|status}"
;;
esac
对于不同主机,脚本中绑定的IP地址要做相应的修改
1. config集群部署
分别在mongodbA,mongodbB,mongodbC机器上,
执行./mongoCluster.sh config start
启动成功,会显示如下信息:

连接其中一个config服务,执行副本集初始化
mongo --port 31000 --host 127.0.0.1
>cfg={
_id:"configReplSet",
configsvr: true,
members:[
{_id:0, host:'192.168.128.128:33000'},
{_id:1, host:'192.168.128.129:32000'},
{_id:2, host:'192.168.128.130:31000'}
]};
>rs.initiate(cfg);
2. shard集群部署
分别在mongodbA,mongodbB,mongodbC机器上:
执行./mongoCluster.sh shard start
启动成功,会显示如下信息:
连接其中一个Shard进程,执行副本集初始化
mongo --port 41010 --host 127.0.0.1
>cfg={
_id:"shard1",
members:[
{_id:0, host:'192.168.128.128:41030',arbiterOnly:true},
{_id:1, host:'192.168.128.129:41020'},
{_id:2, host:'192.168.128.130:41010'}
]};
rs.initiate(cfg);
同样shard2,shard3执行相同的操作:
shard2
cfg={
_id:"shard2",
members:[
{_id:0, host:'192.168.128.128:42030'},
{_id:1, host:'192.168.128.129:42020',arbiterOnly:true},
{_id:2, host:'192.168.128.130:42010'}
]};
rs.initiate(cfg);
shard3
cfg={
_id:"shard3",
members:[
{_id:0, host:'192.168.128.128:43030'},
{_id:1, host:'192.168.128.129:43020'},
{_id:2, host:'192.168.128.130:43010',arbiterOnly:true}
]};
rs.initiate(cfg);
3. mongos部署
分别在mongodbA,mongodbB,mongodbC机器上:
执行./mongoCluster.sh mongos start
启动成功,会显示如下信息:

接入其中一个mongos实例,执行添加分片操作:
./bin/mongo --port 21000 --host 127.0.0.1
>sh.addShard("shard1/192.168.128.130:41010")
{ "shardAdded" : "shard1", "ok" : 1 }
>sh.addShard("shard2/192.168.128.129:42010")
{ "shardAdded" : "shard2", "ok" : 1 }
>sh.addShard("shard2/192.168.128.128:43030")
{ "shardAdded" : "shard3", "ok" : 1 }
4. 初始化用户
初始化mongos用户
接入其中一个mongos实例,添加管理员用户
>use admin
>db.createUser({
user:'admin',pwd:'Admin@01',
roles:[
{role:'clusterAdmin',db:'admin'},
{role:'userAdminAnyDatabase',db:'admin'},
{role:'dbAdminAnyDatabase',db:'admin'},
{role:'readWriteAnyDatabase',db:'admin'}
]})
当前admin用户具有集群管理权限、所有数据库的操作权限。
需要注意的是,在第一次创建用户之后,localexception不再有效,接下来的所有操作要求先通过鉴权。
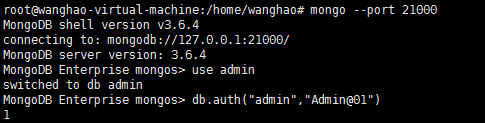
查看集群状态,sh.status()
初始化shard集群用户
分片集群中的访问都会通过mongos入口,而鉴权数据是存储在config副本集中的,即config实例中system.users数据库存储了集群用户及角色权限配置。mongos与shard实例则通过内部鉴权(keyfile机制)完成,因此shard实例上可以通过添加本地用户以方便操作管理。在一个副本集上,只需要在Primary节点上添加用户及权限,相关数据会自动同步到Secondary节点。
>use admin
>db.createUser({
user:'admin',pwd:'Admin123',
roles:[
{role:'clusterAdmin',db:'admin'},
{role:'userAdminAnyDatabase',db:'admin'},
{role:'dbAdminAnyDatabase',db:'admin'},
{role:'readWriteAnyDatabase',db:'admin'}
]})
数据割接
集合分片一般都是针对大数据量的集合;小集合分片没有必要进行分片,如果片键选择不当反而会影响查询效率
初始化数据分片
首先创建数据库用户uhome、为数据库实例uhome启动分片
use uhome
db.createUser({user:'uhome',pwd:'Uhome123',roles:[{role:'dbOwner',db:'uhome'}]})
sh.enableSharding("uhome")
以customer为例,
use uhome
db.createCollection("customer")
sh.shardCollection("uhome.
customer
", {community_id:"hashed"}, false)
导入数据:
mongoimport --port 21000 --db uhome --collection customer -u uhome -p Uhome123 --type csv --headerline --ignoreBlanks --file ./customer-mongo.csv
查看一下数据分布
db.customer.getShardDistribution()
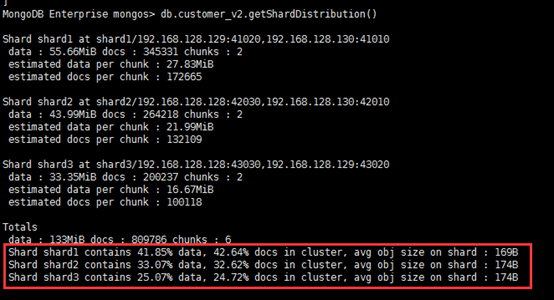
可以看出来,分布还算均匀
参考:
https://www.cnblogs.com/littleatp/p/8563273.html
https://docs.mongodb.com/manual/sharding/
MongoDB分片集群部署方案的更多相关文章
- MongoDB DBA 实践8-----Linux系统Mongodb分片集群部署
在Linux系统中,主要是使用命令行进行mongodb的分片集群部署 一.先决条件 mongodb安装成功,明确路径, MongoDB的几个路径: /var/lib/mongodb /var/log/ ...
- MongoDB分片集群原理、搭建及测试详解
随着技术的发展,目前数据库系统对于海量数据的存储和高效访问海量数据要求越来越高,MongoDB分片机制就是为了解决海量数据的存储和高效海量数据访问而生. MongoDB分片集群由mongos路由进程( ...
- CentOS7+Docker+MangoDB下部署简单的MongoDB分片集群
简单的在Docker上快速部署MongoDB分片集群 前言 文中使用的环境如下 OS:CentOS Linux release 7.5.1804 (Core) Docker:Docker versio ...
- MongoDB(7):集群部署实践,包含复制集,分片
注: 刚开始学习MongoDB,写的有点麻烦了,网上教程都是很少的代码就完成了集群的部署, 纯属个人实践,错误之处望指正!有好的建议和资料请联系我QQ:1176479642 集群架构: 2mongos ...
- MongoDB在windows平台分片集群部署
本文转载自:https://www.cnblogs.com/hx764208769/p/4260177.html 前言-为什么我要使用mongodb 最近我公司要开发一个日志系统,这个日志系统包括很多 ...
- MongoDB部署实战(一)MongoDB在windows平台分片集群部署
前言-为什么我要使用mongodb 最近我公司要开发一个日志系统,这个日志系统包括很多类型,错误的,操作的,...用MongoDB存储日志,大量的日志产生,大量读写吞吐量很大的时候,单个Server很 ...
- 网易云MongoDB分片集群(Sharding)服务已上线
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. MongoDB sharding cluster(分片集群)是MongoDB提供的数据在线水平扩展方案,包括 ...
- Redis 中常见的集群部署方案
Redis 的高可用集群 前言 几种常用的集群方案 主从集群模式 全量同步 增量同步 哨兵机制 什么是哨兵机制 如何保证选主的准确性 如何选主 选举主节点的规则 哨兵进行主节点切换 切片集群 Redi ...
- Mongodb分片集群技术+用户验证
随着数据量持续增多,后续迟早会出现一台机器硬件瓶颈问题的.而mongodb主打的就是海量数据架构,“分片”就用这个来解决这个问题. 从图中可以看到有四个组件:mongos.config server. ...
随机推荐
- 持续引领大数据行业发展,腾讯云发布全链路数据开发平台WeData
9月11日,在腾讯全球数字生态大会大数据专场上,腾讯云大数据产品副总经理雷小平重磅发布了全链路数据开发平台WeData,同时发布和升级了流计算服务.云数据仓库.ES.企业画像等6款核心产品,进一步优化 ...
- Linux 设置日期时间
linux 日期设置 直接设置日期和时间 date -s 2019-02-11 date -s 12:12:12 date -s "2019-02-11 12:12:12"
- 云原生网络代理(MOSN)的进化之路
本文系云原生应用最佳实践杭州站活动演讲稿整理.杭州站活动邀请了 Apache APISIX 项目 VP 温铭.又拍云平台开发部高级工程师莫红波.蚂蚁金服技术专家王发康.有赞中间件开发工程师张超,分享云 ...
- 下载windows官网镜像并打包成iso文件
一.微软官网下载镜像地址:https://www.microsoft.com/zh-cn/software-download/ 选择所需下载的win10.win7等windows镜像(以win10为例 ...
- burpsuite进阶使用
.Burpsuite:爆破 个人建议选择pro破解版的,免费版的太鸡肋,爆破不能设置线程,速度超乎你想像 浏览器和burpsuite设置代理后,开启抓包,截获数据包后,右键选择发送到repeater修 ...
- [BUUCTF] 真的很杂
这似乎是一道安卓逆向题??我就是没有搞懂安卓逆向原来是misc吗... 安卓逆向一个例子 工具准备 1.apktool--可以反编译软件的布局文件.图片等资源,方便大家学习一些很好的布局: 2.dex ...
- iNeuOS工业互联平台,图表与数据点组合成新组件,进行项目复用
目 录 1. 概述... 1 2. 演示信息... 2 3. 应用过程... 2 1. 概述 针对有些行业的数据已经形成了标准化的建模或者有些公司专注于某 ...
- 容器编排系统k8s之Ingress资源
前文我们了解了k8s上的service资源的相关话题,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/14161950.html:今天我们来了解下k8s上的In ...
- 2020年Spring Cloud最后一个大版本发布!
2020年12月22日,Spring Cloud 2020.0 正式发布GA版本! 版本说明 每次Spring Cloud的大版本发布,我们都要先弄清楚,它对应的Spring Boot版本是哪个! 该 ...
- HCIP --- BGP实验
实验拓扑: 要求: R1.R2是EBGP关系,R2.R4是IBGP关系,R4.R5是EBGP邻居关系 R1与R5的环回可以通信 1.配置IP地址 2.BGP承载与IGP之上,所以给AS 2 启用IGP ...