Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建
下载包
所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2.2.0/
Spark 集群高可用搭建
对于 Spark Standalone 集群来说, 当 Worker 调度出现问题的时候, 会自动的弹性容错, 将出错的 Task 调度到其它 Worker 执行
但是对于 Master 来说, 是会出现单点失败的, 为了避免可能出现的单点失败问题, Spark 提供了两种方式满足高可用
使用 Zookeeper 实现 Masters 的主备切换
使用文件系统做主备切换
Step 1 停止 Spark 集群
cd /export/servers/spark
sbin/stop-all.shStep 2 修改配置文件, 增加 Spark 运行时参数, 从而指定 Zookeeper 的位置
进入
spark-env.sh所在目录, 打开 vi 编辑cd /export/servers/spark/conf
vi spark-env.sh编辑
spark-env.sh, 添加 Spark 启动参数, 并去掉 SPARK_MASTER_HOST 地址
# 指定 Java Home
export JAVA_HOME=/export/servers/jdk1.8.0_141 # 指定 Spark Master 地址
# export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077 # 指定 Spark History 运行参数
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log" # 指定 Spark 运行时参数
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
Step 3 分发配置文件到整个集群
cd /export/servers/spark/conf
scp spark-env.sh node02:$PWD
scp spark-env.sh node03:$PWDStep 4 启动
在
node01上启动整个集群cd /export/servers/spark
sbin/start-all.sh
sbin/start-history-server.sh在
node02上单独再启动一个 Mastercd /export/servers/spark
sbin/start-master.sh
Step 5 查看 node01 master 和 node02 master 的 WebUI
你会发现一个是
ALIVE(主), 另外一个是STANDBY(备)

Spark shell
简单介绍
Spark shell 是 Spark 提供的一个基于 Scala 语言的交互式解释器, 类似于 Scala 提供的交互式解释器, Spark shell 也可以直接在 Shell 中编写代码执行
这种方式也比较重要, 因为一般的数据分析任务可能需要探索着进行, 不是一蹴而就的, 使用 Spark shell 先进行探索, 当代码稳定以后, 使用独立应用的方式来提交任务, 这样是一个比较常见的流程
Spark shell 的方式编写 WordCount
|
Spark shell 简介
|
|
Master地址的设置
Master 的地址可以有如下几种设置方式
|
Step 1 准备文件
在 hadoop01 中创建文件 /export/data/wordcount.txt,文件内容如下
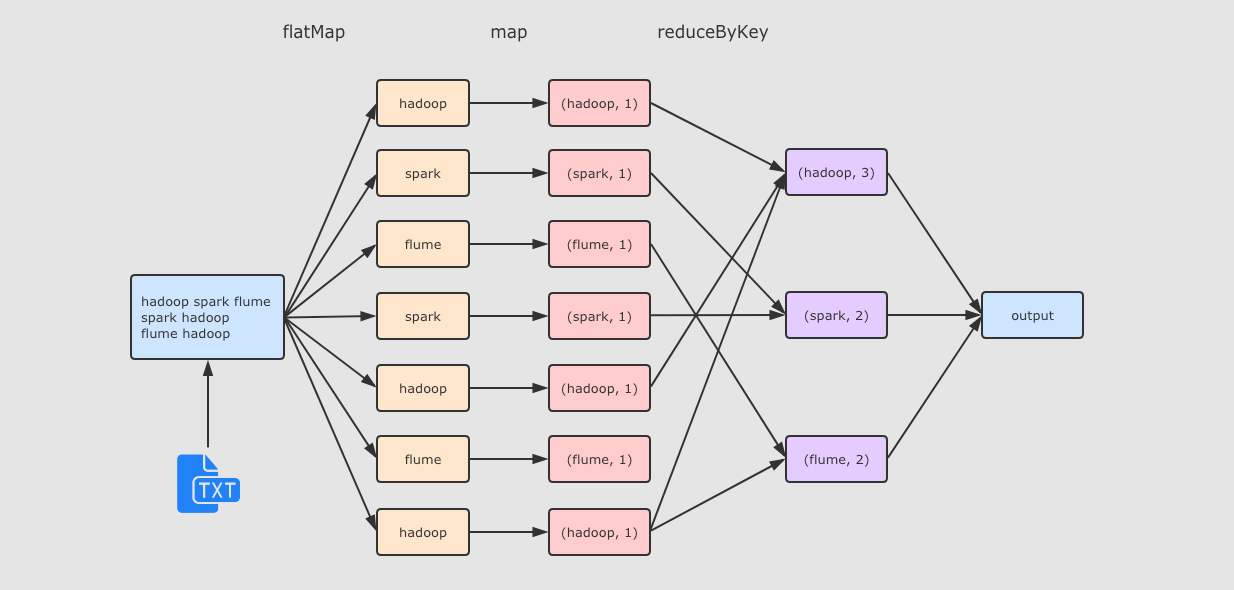
hadoop spark flume
spark hadoop
flume hadoopStep 2 启动 Spark shell
cd /export/servers/spark
bin/spark-shell --master local[2]Step 3 执行如下代码

运行流程
Spark学习进度-Spark环境搭建&Spark shell的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
随机推荐
- C#使用ML.Net完成人工智能预测
前言 Visual Studio2019 Preview中提供了图形界面的ML.Net,所以,只要我们安装Visual Studio2019 Preview就能简单的使用ML.Net了,因为我的电脑已 ...
- SpringBoot之自定义拦截器
一.自定义拦截器实现步骤 1.创建拦截器类并实现HandlerInterceptor接口 2.创建SpringMVC自定义配置类,实现WebMvcConfigurer接口中addInterceptor ...
- 实现一个类型判断函数,需要鉴别出基本类型、function、null、NaN、数组、对象?
只需要鉴别这些类型那么使用typeof即可,要鉴别null先判断双等判断是否为null,之后使用typeof判断,如果是obejct的话,再用Array.isArray判断是否为数组,如果是数字再使用 ...
- 【eJOI2020】考试(dp & 树状数组优化)
Description \(n\) 个正整数排成一列,每个位置 \(i\) 有一个初始值 \(A_i\) 以及目标值 \(B_i\). 一次操作可以选定一个区间 \([l, r]\),并将区间内所有数 ...
- Java并发编程的艺术(五)——线程和线程的状态
线程 什么是线程 操作系统调度的最小单元就是线程,也叫轻量级进程. 为什么要使用多线程 多线程程序能够更有效率地利用多处理器核心. 用户响应时间更快. 方便程序员将程序模型映射到Java提供的多线程编 ...
- echarts饼图默认状态高亮显示
需求:饼状图默认状态下高亮显示指定内容. 最常见的两种: 一.饼图中间始终默认展示数据总数和统计事项的名字(如下图),这种实现方式比较简单,就不多介绍 二.饼图中间默认展示某一图例的具体数据,鼠标放在 ...
- linux下/etc/profile /etc/bashrc /root/.bashrc /root/.bash_profile这四个配置文件的加载顺序
目录 一.关于linux配置文件 二.验证四个配置文件的加载顺序 三.结论 一.关于linux配置文件 1.linux下主要有四个配置文件:/etc/profile ./etc/bashrc ./ro ...
- MySQL 5.7.29主从安装配置
一.环境准备(关闭防火墙) 1.清除已安装数据库 [root@mysql01 ~]# rpm -qa | grep mariadb mariadb-libs-5.5.35-3.el7.x86_64 [ ...
- springmvc使用路径变量后再进行页面跳转会出现路径错误问题
学习<Servlet.JSP和SpringMVC学习指南>遇到的一个问题,记录下. 项目代码 现象 @RequestMapping(value = "/book_edit/{id ...
- 2020-2021-1 20209307 《Linux内核原理与分析》第九周作业
这个作业属于哪个课程 <2020-2021-1Linux内核原理与分析)> 这个作业要求在哪里 <2020-2021-1Linux内核原理与分析第九周作业> 这个作业的目标 & ...