HashMap的put kv,是如何扩容的?
HashMap的put kv,是如何扩容的?
描述下HashMap put(k,v)的流程?
它的扩容流程是怎么样的?
HashMap put(k,v)流程
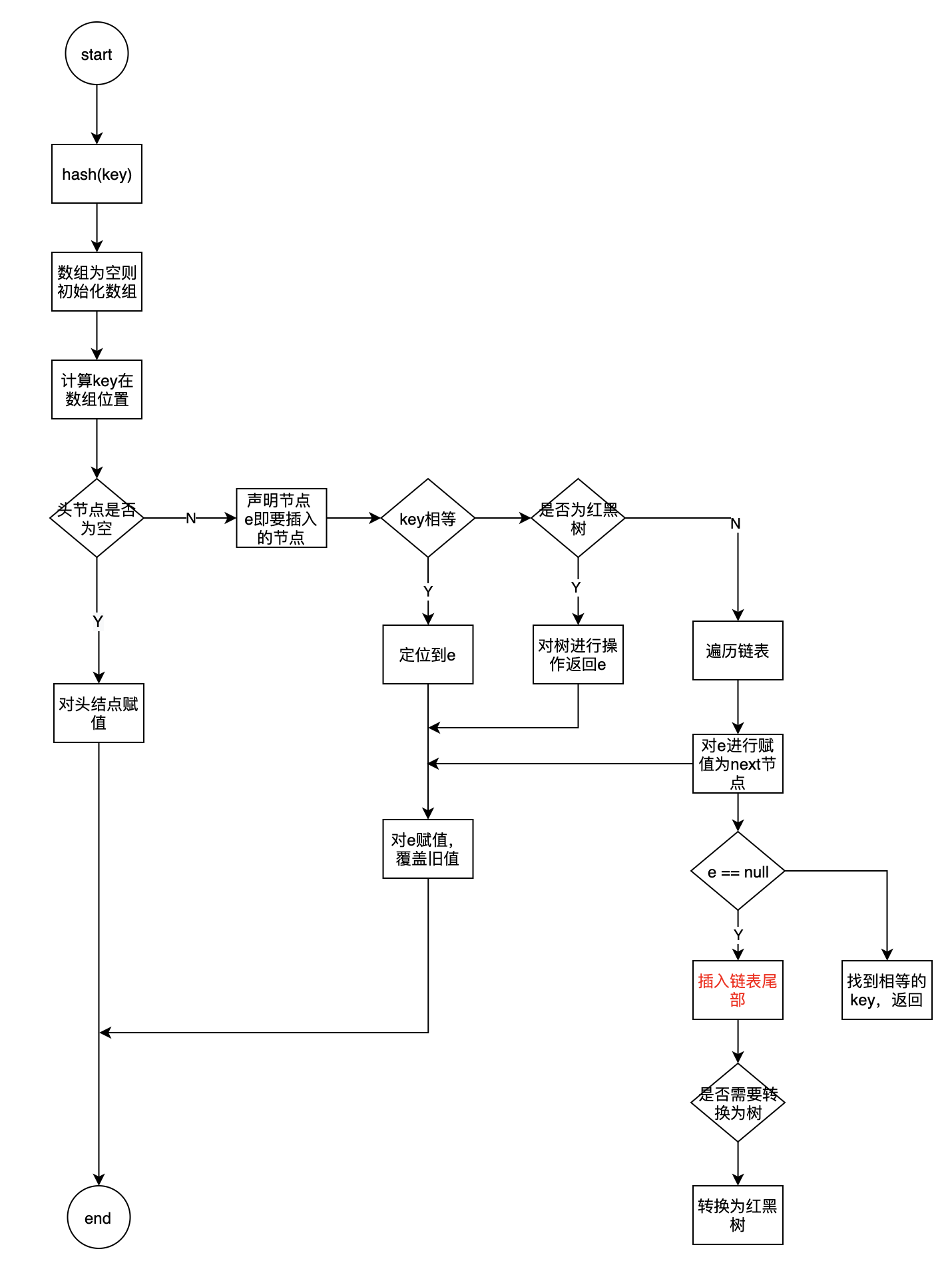
- 通过hash(key方法)获取到key的hash值
- 调用put方法, 将value存放到指定的位置
- 根据hash值确定当前key所在node数组的索引
(n - 1) & hash - 如果node[i]==null 则直接创建新数组
- 如果node[i]!=null
- 判断 当前node的头结点的 hash和key是否都相等, 相等则需要操作的就是该node
- 判断当前节点是否为TreeNode,对TreeNode进行操作,并返回结果e
- 如果是链表则遍历链表,key存在则返回节点e,不存在则赋值
- 判断节点e有没有被赋值,覆盖旧值
- hashMap size进行加1,同时判断v新size是否大于扩容阈值从而判断是否需要扩容
- 根据hash值确定当前key所在node数组的索引
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// 声明Node数组tab, Node节点
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 对tab数组赋值为当前HashMap的table, 并判断是否为空, 或者长度为0
// 为0进行则resize()数组, 并对 n赋值为当前tab的长度
// resize() 对HashMap的table扩容, 并返回扩容后的新数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 对 node p 进行赋值, 数组所在位置 即 node p 如果是null 则直接赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// p 不为null, 声明 node e, key k
Node<K,V> e; K k;
// 如果hash值相等且key相等, 直接将 e 赋值为当前node的头节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
// 如果是红黑树, 则对树进行操作, 返回节点e
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 对链表进行遍历, 找到对应的节点
for (int binCount = 0; ; ++binCount) {
// 将 e 赋值为 头节点p的next, 如果下一个节点为null
if ((e = p.next) == null) {
// 对节点进行赋值
p.next = newNode(hash, key, value, null);
// 如果长度到达数转换阈值, 则需要转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果e节点的hash相等, key相等, 则 直接跳出循环 e 已经被赋值为 p.next
// 此时e节点的value没有被赋值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 指针指向下一个节点, 继续遍历
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 对旧值进行覆盖, 并返回旧值
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 是否需要扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
resize()扩容过程
- JDK 1.7 扩容流程, 每次都需要数组扩容后, 链表需要重新计算在新数组的位置
- JDK 1.8 不需要重新计算 (优化点)
- 数组下标: (n - 1) & hash 即数组长度-1 & key的hash
- 扩容后的数组下标: ((n << 1) - 1) & hash 相当于在 高位1之前加了个1
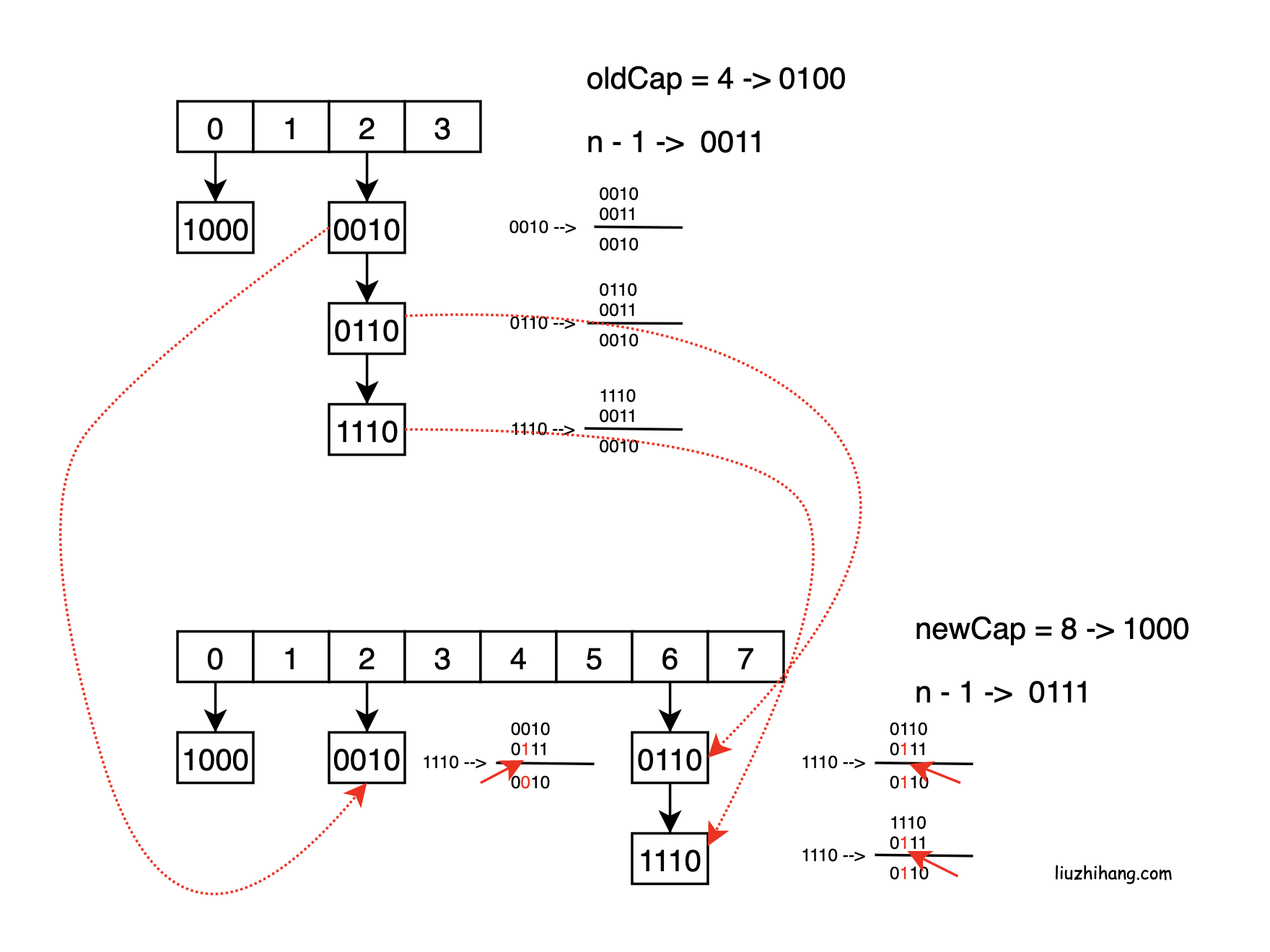
如图所示, 真正发生影响的是新增的那一位(红色箭头所指), 所以 oldCap & hash 完全可以判断该值是放在旧索引值的位置还是放在旧索引值+旧数组长度的位置
final Node<K,V>[] resize() {
// 旧数组
Node<K,V>[] oldTab = table;
// 旧数组长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 旧的扩容阈值
int oldThr = threshold;
// 新的数组长度和新扩容阈值
int newCap, newThr = 0;
// 旧数组存在
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 新数组长度为旧数组长度的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 扩容阈值是旧扩容阈值的2倍
newThr = oldThr << 1; // double threshold
}
// 旧数组不存在, 相当于首次put(K, V)时, 将数组长度置为扩容阈值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 旧数组不存在, new HashMap()未指定长度, 初次put(K, V), 设置为默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 新的扩容阈值是0, 则将扩容阈值设置为 新数组长度*负载因子
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 对全局的扩容阈值进行赋值
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 创建新数组, 长度为新长度, 即原数组长度的2倍
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 将table复制为新数组
table = newTab;
if (oldTab != null) {
// 对旧数组进行遍历
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 旧节点node赋值
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
// 只有头结点, 直接计算新的位置并赋值
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 树单独处理
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
// next节点
next = e.next;
// 节点hash与旧数组长度 & 的结果来决定元素所在位置, 参考上面图示所讲
if ((e.hash & oldCap) == 0) {
// 在元索引出创建新链表
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
// 新索引出创建链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 索引j处直接赋值
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 索引 j + 老数组长度位置存放hiHead
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap的put kv,是如何扩容的?的更多相关文章
- HashMap底层结构、原理、扩容机制
https://www.jianshu.com/p/c1b616ff1130 http://youzhixueyuan.com/the-underlying-structure-and-princip ...
- 深入理解HashMap(原理,查找,扩容)
面试的时候闻到了Hashmap的扩容机制,之前只看到了Hasmap的实现机制,补一下基础知识,讲的非常好 原文链接: http://www.iteye.com/topic/539465 Hashmap ...
- HashMap源码分析2:扩容
本文源码基于JDK1.8.0_45. final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = ...
- Java HashMap的扩容
最近博主参加面试,发现自己对于Java的HashMap的扩容过程理解不足,故最近在此进行总结. 首先说明博主德Java为1.8版本 HashMap中的变量 首先要了解HashMap的扩容过程,我们就得 ...
- 面试官:"准备用HashMap存1w条数据,构造时传10000还会触发扩容吗?"
// 预计存入 1w 条数据,初始化赋值 10000,避免 resize. HashMap<String,String> map = new HashMap<>(10000) ...
- Java8中HashMap扩容算法小计
Java8的HashMap扩容过程主要就是集中在resize()方法中 final Node<K,V>[] resize() { // ...省略不重要的 } 其中,当HashMap扩容完 ...
- HashMap源码解析、jdk7和8之后的区别、相关问题分析(多线程扩容带来的死循环)
一.概览 HashMap<String, Integer> map = new HashMap<>(); 这个语句执行起来,在 jdk1.8 之前,会创建一个长度是 16 的 ...
- HashMap的笔记
size表示HashMap中存放KV的数量 capacity译为容量.capacity就是指HashMap中桶的数量.默认值为16.一般第一次扩容时会扩容到64,之后好像是2倍.总之,容量都是2的幂. ...
- 分析轮子(十)- HashMap.java 之概念梳理
注:玩的是JDK1.7版本 一:还是原来的风格,先上一下类的继承关系图,这样能够比较清楚的知道此类的相关特性 二:HashMap.java 的代码比较难看,所以,我看了几天,写的话也分开来写,这样能表 ...
随机推荐
- Java知识系统回顾整理01基础03变量07final关键字
一.final赋值 final 修饰一个变量,有很多种说法,比如不能改变等等 准确的描述是 当一个变量被final修饰的时候,该变量只有一次赋值的机会 二.在声明的时候赋值 i已经被赋值为5,所以这里 ...
- windows 漏洞列表
漏洞列表 #Security Bulletin #KB #Description #Operating System CVE-2017-0213 [Windows COM Eleva ...
- matlab中ceil朝正无穷大四舍五入
来源:https://ww2.mathworks.cn/help/matlab/ref/ceil.html?searchHighlight=ceil&s_tid=doc_srchtitle 本 ...
- DORIS系统概述
DORIS(Doppler Orbitography and Radio-positioning Integrated by Satellite)(多普勒轨道学与无线电定位集成卫星),它是由法国Cne ...
- JavaScript按钮排他思想
要求: 有一系列按钮,要求每单击其中一个,该按钮改变样式(以背景颜色为例),其他按钮恢复保持默认样式. 实现思路: 获取所有按钮元素 首先先把其他按钮的背景颜色去掉 再单独设置自己的样式 代码实现: ...
- Pock 把 Touch Bar 变成系统中的 Dock 栏
Pock 把 Touch Bar 变成系统中的 Dock 栏 Pock 是一款 macOS App,你可以通过它把 Touch Bar 变成系统中的 Dock 栏,直接用来切换和启动 App,尽享全屏 ...
- tomcat 验证码显示问题
在Web开发中使用验证码时可能遇到的问题:java.lang.NoClassDefFoundError: Could not initialize class sun.awt.X11GraphicsE ...
- 安装两个Eclipse 版本不一致,高版本无法打开
Could not create the JavaVirtual Machine,A fatal exception has occurred. 首先删除了 工作空间的配置 然后删除掉C:\Windo ...
- element中过滤器filters的使用(开发小记)
之前在开发过程中遇到这么一个问题,一串数据需要在el-table中展示,其中含有金额字段,需要将其转换成标准数据格式,即三位一个逗号间隔. 今年刚毕业就上手项目了,第一次接触的Vue,开发经验少,也忘 ...
- CSP-S2020AFO记
2020-10.11 考初赛辣. 选择题考了一堆时间复杂度,一个不会(卒) 我寻思这01背包哪里能用贪心? 啊,这,这,这手写快排竟如此简单,手写取Max,手写队列,两个字符串颠来倒去,竟活到爆! 震 ...