hdfs学习(三)
HDFS 的 API 操作
使用url方式访问数据(了解)
@Test
public void urlHdfs() throws IOException {
//1.注册url
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
//2.获取hdfs文件的输入流
InputStream inputStream=new URL("hdfs://hadoop101:8020/a.txt").openStream();
//3.获取本地文件的输出流
OutputStream outputStream= new FileOutputStream(new File("E:\\hello.txt"));
//4.实现文件的拷贝
IOUtils.copy(inputStream,outputStream);
//5.关流
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
}
使用文件系统方式访问数据(掌握)
获取 FileSystem 的几种方式
①
/*
获取FileSystem,方式1
*/
@Test
public void getFileSystem1() throws IOException{
//1.创建Configuration对象
Configuration configuration=new Configuration();
//2.设置文件系统类型
configuration.set("fs.defaultFS","hdfs://hadoop101:8020");
//3.获取指定的文件系统
FileSystem fileSystem= FileSystem.get(configuration);
//4.输出
System.out.println(fileSystem);
}
②用的次数比较多
/*
获取FileSystem,方式2
ctrl+alt+v自动补全返回值
*/
@Test
public void getFileSystem2() throws URISyntaxException, IOException, InterruptedException {
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop101:8020"), new Configuration(),"root");
System.out.println(fileSystem);
}
③
/*
获取FileSystem,方式3
ctrl+alt+v自动补全返回值
*/
@Test
public void getFileSystem3() throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://hadoop101:8020","root");
//3.获取指定的文件系统
FileSystem fileSystem= FileSystem.newInstance(configuration);
//4.输出
System.out.println(fileSystem.toString());
}
④
/*
获取FileSystem,方式4
ctrl+alt+v自动补全返回值
*/
@Test
public void getFileSystem4() throws URISyntaxException, IOException, InterruptedException {
FileSystem fileSystem= FileSystem.newInstance(new URI("hdfs://hadoop101:8020"), new Configuration(),"root");
System.out.println(fileSystem);
}
遍历 HDFS中所有文件
/*
hdfs文件的遍历
*/
@Test
public void listFiles() throws URISyntaxException, IOException, InterruptedException {
//1.获取FileSystem实例
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop101:8020"), new Configuration(),"root");
//2.调用方法listFiles获取/目录下的所有文件信息
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path("/"), true);
//3.遍历迭代器
while (iterator.hasNext()){
LocatedFileStatus fileStatus = iterator.next(); //获取文件的绝对路径:hdfs://hadoop101:/xxx
System.out.println(fileStatus.getPath()+"----"+fileStatus.getPath().getName());
//文件的block信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println("block数目:"+blockLocations.length);
}
}
输出:

HDFS 上创建文件夹
/*
hdfs创建文件夹
*/
@Test
public void mkdirsTest() throws URISyntaxException, IOException, InterruptedException {
//1.获取FileSystem实例
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop101:8020"), new Configuration(),"root");
//2.获取文件夹
boolean bl=fileSystem.mkdirs(new Path("/aaa/bbb/ccc/a.txt"));
//fileSystem.create(new Path("/aaa/bbb/ccc/a.txt"));
System.out.println(bl);
//3.关闭FileSystem
fileSystem.close();
}
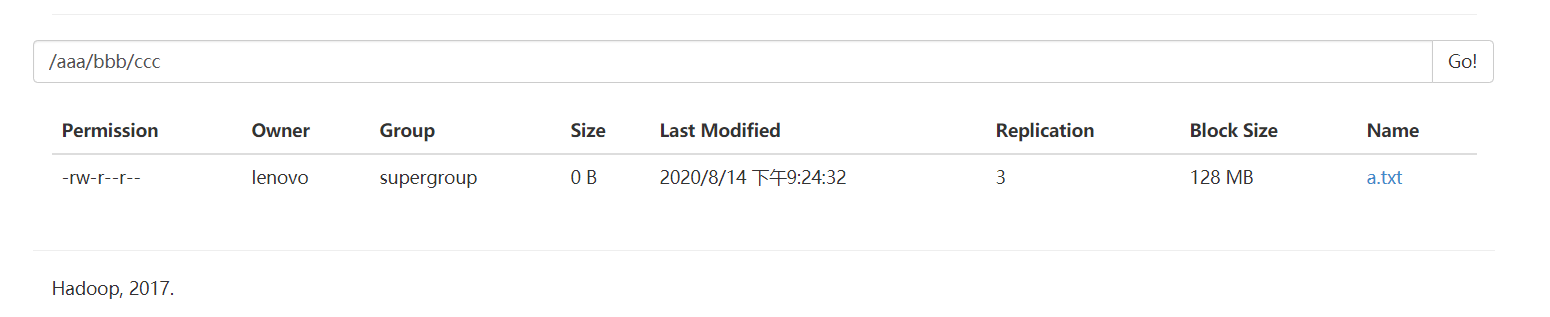
下载文件
/*
文件下载2:使用方法copyToLocalFile下载到本地E盘下的bbb.txt
*/
@Test
public void downloadFile2() throws URISyntaxException, IOException, InterruptedException {
//1.获取FileSystem
FileSystem fileSystem=FileSystem.get(new URI("hdfs://hadoop101:8020"),new Configuration(),"root"); fileSystem.copyToLocalFile(new Path("/a.txt"),new Path("E://bbb.txt")); fileSystem.close(); }
/*
文件下载
*/
@Test
public void downloadFile() throws URISyntaxException, IOException {
//1.获取FileSystem
FileSystem fileSystem=FileSystem.get(new URI("hdfs://hadoop101:8020"),new Configuration());
//2.获取hdfs的输入流
FSDataInputStream inputStream = fileSystem.open(new Path("/a.txt"));
//3.获取本地路径的输出流
FileOutputStream outputStream = new FileOutputStream("E://a.txt");
//4.文件的拷贝
IOUtils.copy(inputStream,outputStream);
//5.关闭流
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
fileSystem.close();
}
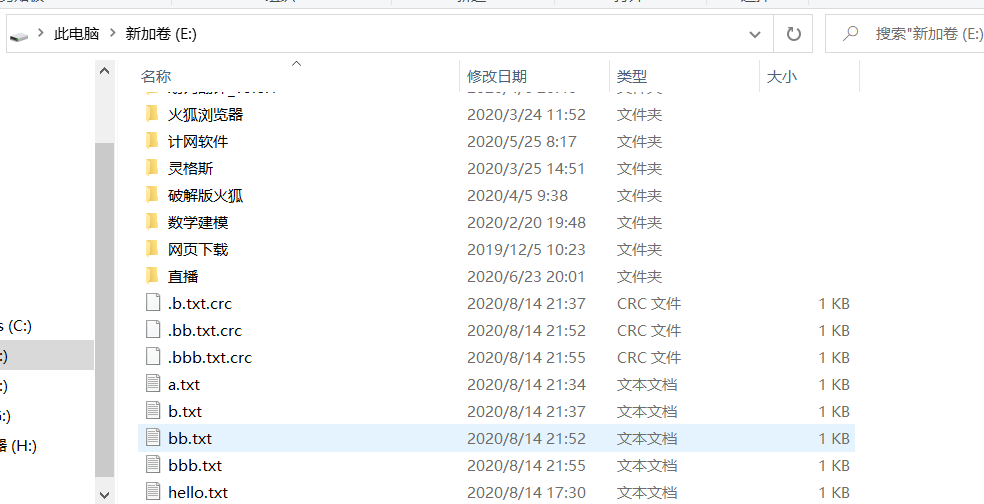
HDFS 文件上传
/*
文件的上传
*/
@Test
public void uploadFile() throws URISyntaxException, IOException, InterruptedException {
FileSystem fileSystem=FileSystem.get(new URI("hdfs://hadoop101:8020"),new Configuration(),"root");
fileSystem.copyFromLocalFile(new Path("E://hello.txt"),new Path("/"));
fileSystem.close();
}

小文件合并
由于 Hadoop 擅长存储大文件,因为大文件的元数据信息比较少,如果 Hadoop 集群当中有大
量的小文件,那么每个小文件都需要维护一份元数据信息,会大大的增加集群管理元数据的
内存压力,所以在实际工作当中,如果有必要一定要将小文件合并成大文件进行一起处理
在我们的 HDFS 的 Shell 命令模式下,可以通过命令行将很多的 hdfs 文件合并成一个大文件下
载到本地
cd /export/servers
hdfs dfs -getmerge /*.xml ./hello.xml
既然可以在下载的时候将这些小文件合并成一个大文件一起下载,那么肯定就可以在上传的
时候将小文件合并到一个大文件里面去
/*
小文件的合并
*/
@Test
public void mergeFile() throws URISyntaxException, IOException, InterruptedException {
//1.获取FileSystem
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop101:8020"), new Configuration(), "root");
//2.获取hdfs大文件的输出流
FSDataOutputStream outputStream = fileSystem.create(new Path("/big_txt.txt")); //3.获取一个本地文件系统
LocalFileSystem localFileSystem = FileSystem.getLocal(new Configuration());
//4.获取本地文件夹下的所有文件的详情
FileStatus[] fileStatuses = localFileSystem.listStatus(new Path("E:\\input"));
//5.遍历每个文件,获取每个文件的输入流
for (FileStatus fileStatus:fileStatuses){
FSDataInputStream inputStream=localFileSystem.open(fileStatus.getPath());
//6.将小文件的数据复制到大文件
IOUtils.copy(inputStream,outputStream);
IOUtils.closeQuietly(inputStream);
}
IOUtils.closeQuietly(outputStream);
localFileSystem.close();
fileSystem.close();
}
输出:

里面的内容是:在E盘下input文件夹下的5个txt文件的总和
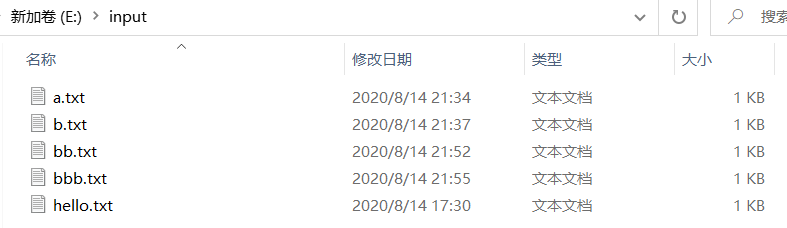
完成本地小文件的合并,上传

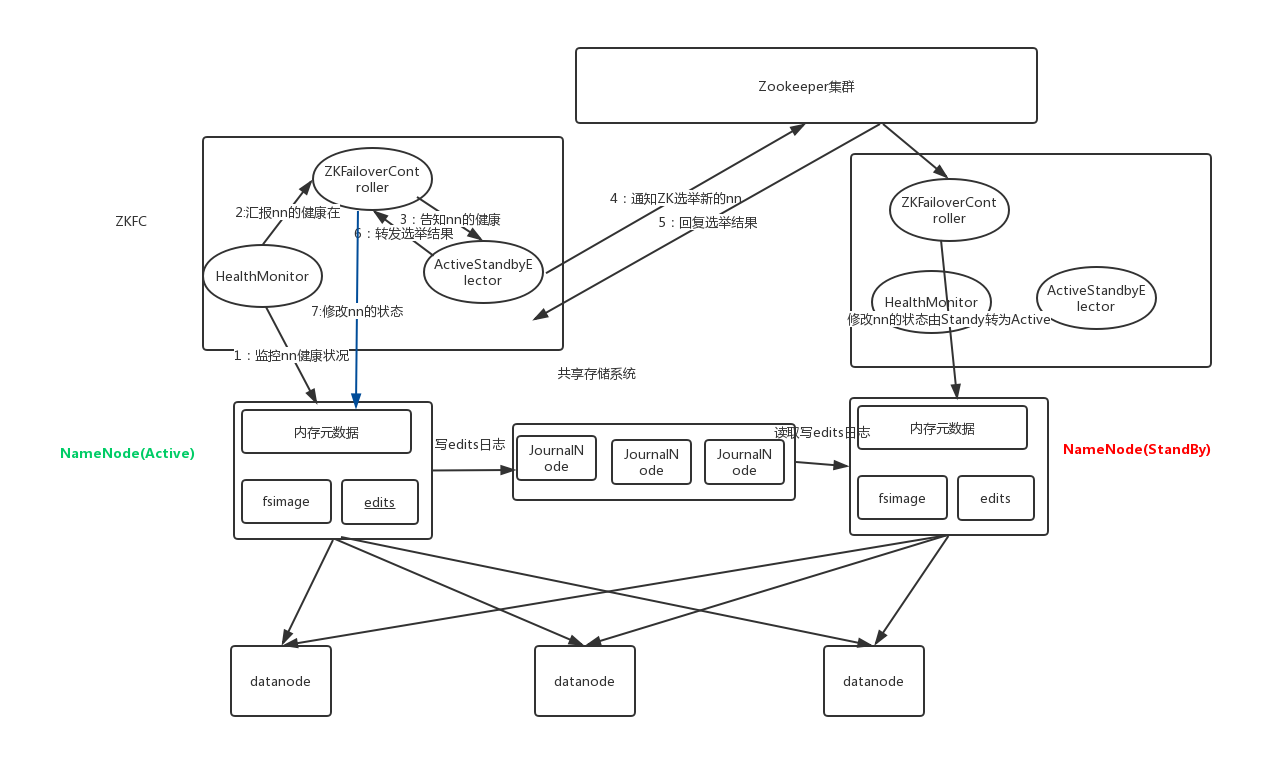
HDFS的高可用机制
在Hadoop 中,NameNode 所处的位置是非常重要的,整个HDFS文件系统的元数据信息都由
NameNode 来管理,NameNode的可用性直接决定了Hadoop 的可用性,一旦NameNode进程
不能工作了,就会影响整个集群的正常使用。
在典型的HA集群中,两台独立的机器被配置为NameNode。在工作集群中,NameNode机器中
的一个处于Active状态,另一个处于Standby状态。Active NameNode负责群集中的所有客户端
操作,而Standby充当从服务器。Standby机器保持足够的状态以提供快速故障切换(如果需
要)。
Hadoop的联邦机制(Federation)
HDFS Federation是解决namenode内存瓶颈问题的水平横向扩展方案。
Federation意味着在集群中将会有多个namenode/namespace。这些namenode之间是联合的,
也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的
datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注
册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
Federation一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分
大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集
群中所有的DataNode的,它们还是在同一个集群内的**。**
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(在DataNode的datadir
所在目录里面查看BP-xx.xx.xx.xx打头的目录)。
概括起来:
多个NN共用一个集群里的存储资源,每个NN都可以单独对外提供服务。
每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储。
DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源
情况。
HDFS Federation不足:
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从
单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相
应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个
secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。
所以一般集群规模真的很大的时候,会采用HA+Federation的部署方案。也就是每个联合的
namenodes都是ha的。

hdfs学习(三)的更多相关文章
- HTTP学习三:HTTPS
HTTP学习三:HTTPS 1 HTTP安全问题 HTTP1.0/1.1在网络中是明文传输的,因此会被黑客进行攻击. 1.1 窃取数据 因为HTTP1.0/1.1是明文的,黑客很容易获得用户的重要数据 ...
- TweenMax动画库学习(三)
目录 TweenMax动画库学习(一) TweenMax动画库学习(二) TweenMax动画库学习(三) ...
- Struts2框架学习(三) 数据处理
Struts2框架学习(三) 数据处理 Struts2框架框架使用OGNL语言和值栈技术实现数据的流转处理. 值栈就相当于一个容器,用来存放数据,而OGNL是一种快速查询数据的语言. 值栈:Value ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- DjangoRestFramework学习三之认证组件、权限组件、频率组件、url注册器、响应器、分页组件
DjangoRestFramework学习三之认证组件.权限组件.频率组件.url注册器.响应器.分页组件 本节目录 一 认证组件 二 权限组件 三 频率组件 四 URL注册器 五 响应器 六 分 ...
- [ZZ] 深度学习三巨头之一来清华演讲了,你只需要知道这7点
深度学习三巨头之一来清华演讲了,你只需要知道这7点 http://wemedia.ifeng.com/10939074/wemedia.shtml Yann LeCun还提到了一项FAIR开发的,用于 ...
- SVG 学习<三>渐变
目录 SVG 学习<一>基础图形及线段 SVG 学习<二>进阶 SVG世界,视野,视窗 stroke属性 svg分组 SVG 学习<三>渐变 SVG 学习<四 ...
- Android JNI学习(三)——Java与Native相互调用
本系列文章如下: Android JNI(一)——NDK与JNI基础 Android JNI学习(二)——实战JNI之“hello world” Android JNI学习(三)——Java与Nati ...
- day91 DjangoRestFramework学习三之认证组件、权限组件、频率组件、url注册器、响应器、分页组件
DjangoRestFramework学习三之认证组件.权限组件.频率组件.url注册器.响应器.分页组件 本节目录 一 认证组件 二 权限组件 三 频率组件 四 URL注册器 五 响应器 六 分 ...
随机推荐
- 有关 Session 的那些事儿
原文链接: https://blog.by24.cn/archives/about-session.html Web 开发中,Session 是经常用到的概念,但是在日常交流中,似乎又经常引起误解. ...
- Qt-绘制图表
1 简介 使用Qt的charts模块来绘制图表,案例来自Qt自带的demo. charts模块简介:Qt Chars模块提供了一系列容易使用的图表组件.需要使用charts组件时,需要导入Qt Ch ...
- Centos 7下编译安装Mysql
(1)官网下载地址:https://dev.mysql.com/downloads/mysql/ 此处下载的是 mysql-boost-5.7..tar.gz 百度云下载地址:https://pan. ...
- Tomcat Script(python)
由于刚接触 Python,所以使用Python 书写一些小的脚本,进行备忘同时分享给大家 #!/usr/bin/env python # _*_coding:utf-8_*_ # author: 'l ...
- java实现链表反转
为什么面试常考链表反转 链表是常用的数据结构,同时也是面试常考点,链表为什么常考,因为链表手写时,大多都会有许多坑,比如在添加节点时因为顺序不对的话会让引用指向自己,因此会导致内存泄漏等问题,Java ...
- Android性能优化----卡顿优化
前言 无论是启动,内存,布局等等这些优化,最终的目的就是为了应用不卡顿.应用的体验性好坏,最直观的表现就是应用的流畅程度,用户不知道什么启动优化,内存不足,等等,应用卡顿,那么这个应用就不行,被卸载的 ...
- checkbox变成单选型
checkbox的特性是可以选中或者取消,有时需要利用这一点做一个类似radio的选项框: <input type="checkbox" class="aa&quo ...
- 没有学历如何从事Java开发?
学历成了当今社会一个衡量一个人能力的标准,未来只会越来越深入,也有的人说不要总是把学历挂嘴边,学历并不能代表能力,确实学历不能代表能力,但是学历是能代表一个的人学习深度,也是在职场上必备的一个敲门砖. ...
- PHP asinh() 函数
实例 返回不同数的反双曲正弦: <?phpecho(asinh(7) . "<br>");echo(asinh(56) . "<br>&qu ...
- [草稿]基于 Virtuoso 环境比较便捷的项目文件及权限管理方案
https://www.cnblogs.com/yeungchie/ 假设如下情况: 1 项目名称 Project_01 2 包含 4 名研发用户,user01 和 user02 为前端工程师,use ...