python内存管理&垃圾回收
python内存管理&垃圾回收
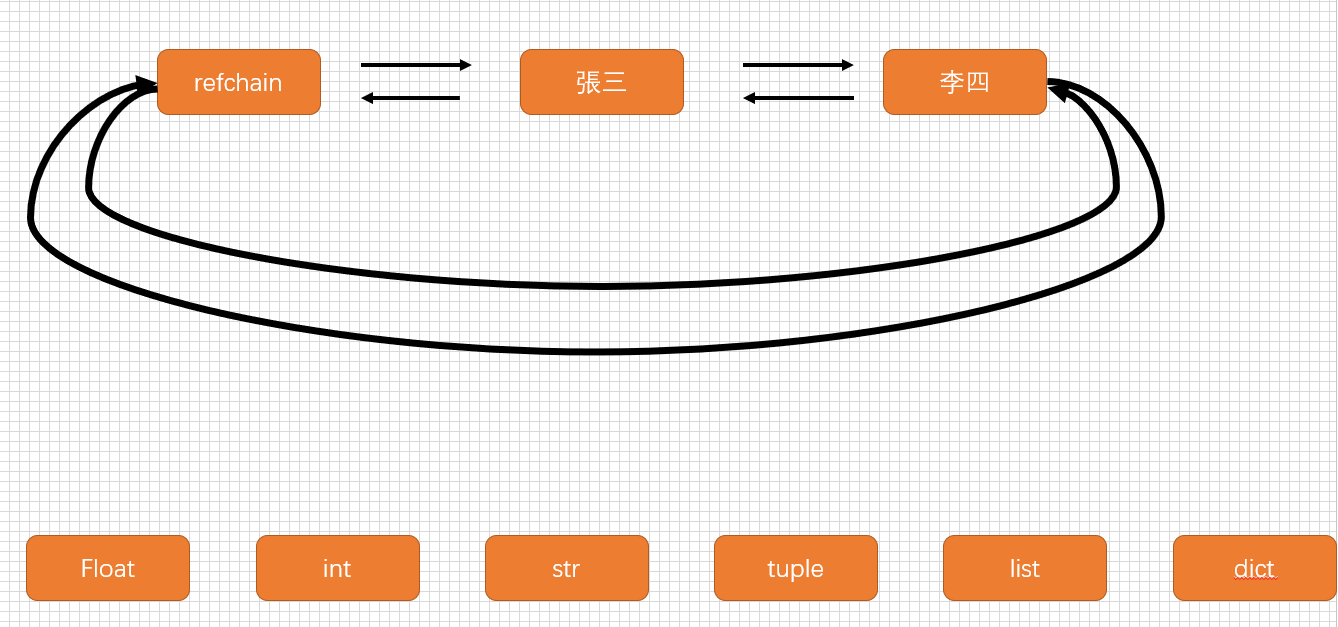
引用计数器
环装双向列表refchain
在python程序中创建的任何对象都会放在refchain连表中
name = '张三'
age = 18
hobby = ['汽车','游艇']
创建一个变量!内部会创建一些数据【上一个对象,下一个对象,类型,引用个数
name = '张三'
内部会创建一些数据【上一个对象,下一个对象,类型,引用计数】
age = 18
内部会创建一些数据【上一个对象、下一个对象、类型、引用计数、val=18】
hobby = ['汽车','游艇']
内部会创建一些数据【上一个对象、下一个对象、类型、引用计数、items=元素】
#define Pyobject_HEAD
#define Pyobject_VAR_HEAD
//宏定义,包含 上一个、下一个,用于构造双向连表用(放到refchain链表中,要用到)
#define _PyObject_HEAD_EXTRA
struct _object * _ob_next;
struct _object * _ob_prev;
typedef struct _object {
_PyObject_HEAD_EXTRA//构造双向连表
Py_ssize_t ob_refcnt;//引用计数器
struct _typeobject * ob_type//数据类型
}PrObject;
typedef struct {
PyObject ob_base;//PyObject对象
Py_ssize_t ob_size;//Number of items in variable part 元素个数
}PyVarObject;
在C源码中如何体验每个对象都有相同的值:PyObject结构体(4个值)
有多个元素组成的对象:PyObject结构体(4个值)+ob_size
类型封装结构体
data = 3.14
内部会创建:
_ob_next refchain中的上一个对象
_ob_prev refchain中的下一个对象
_ob_refcnt = 1
_ob_type = float
_ob_fval = 3.14
引用计数器
v1 = 3.14
v2 = 999
v3 = (1,2,3)
当python程序运行时,会根据数据类型的 不同找到其对应类型的结构体,根据结构体中的字段来创建相关的数据,然后将对象添加到refchain双向链表中。
在C源码中有两个关键的结构体:PyObject、PyVarObject
每个对象这种有ob_refcnt就是引用计数器,值 默认为1,当有其他变量引用对象时,引用计数器就会发生变化。
#引用
a = 666
b = a 引用计数2
a = 666
b = a
del b #b变量删除:b对应对象引用计数器-1
当一个对象的引用计数器为0时,意味着没有使用这个对象,这个对象就是垃圾。会被垃圾回收。
#回收:1.当对象从refchain链表移除,2.将对象销毁。内存归还。
引用计数器的BUG
循环引用的问题

标记清除
目的:为了解决引用计数器循环引用的不足
实现:在python的底层,维护一个链表,链表中专门放可能存在循环引用的对象【tuple、list、dict、set】。
在python内部某种情况下触发,回去扫描 可能存在循环应用的链表中的每个元素,检查是否有循环引用,如果有引用,让双方的引用技术器-1,如果是0 则垃圾回收。
问题:什么时候扫描?
可能存在循环引用的链表扫码代价大!每次扫描耗时时间长。
分代回收
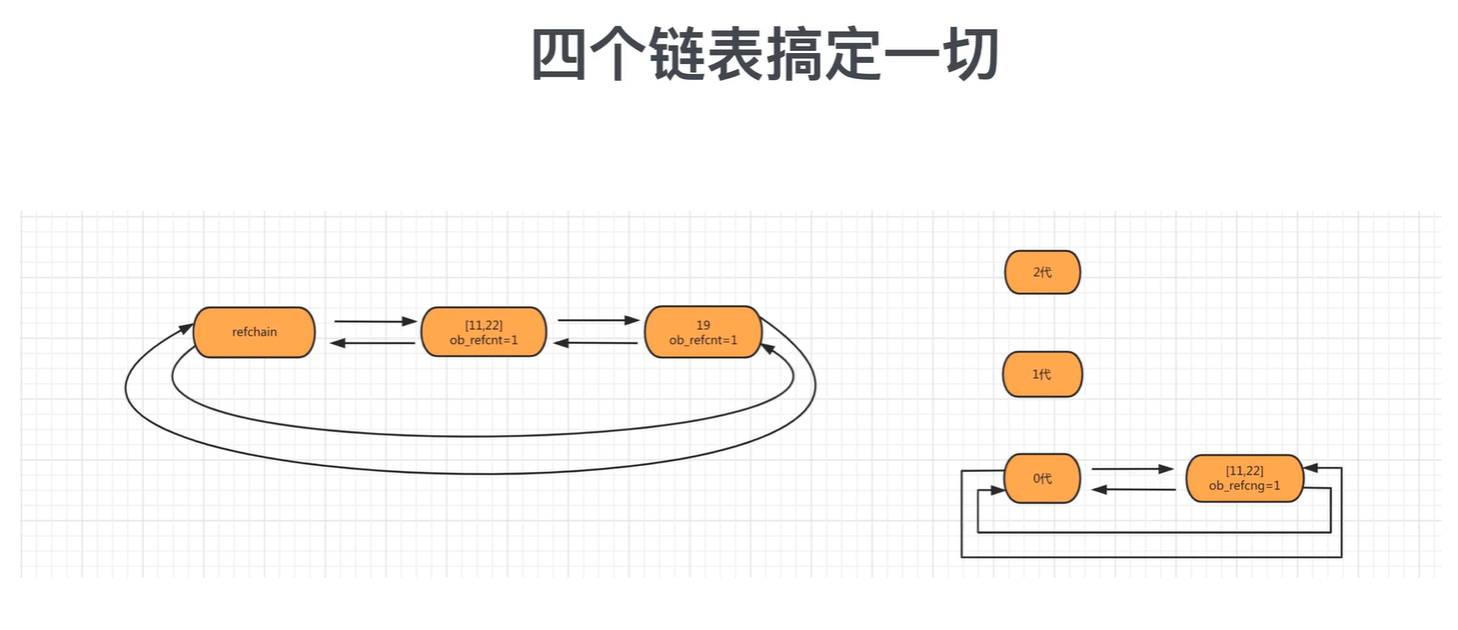
将可能存在循环引用的对象维护成3个链表
- 0代:0代中对象个数达到700个扫描一次。
- 1代:0代扫描10次,则一代扫描1次。
- 2代:1代扫描10次,则2代扫描1次。
小结
在python中维护了一个refchain的双向环装链表,这个链表中存储程序创建的所有对象,每种没醒的对象都有一个_obj_refcnt引用计数器的值,引用个数+1、-1,最后当引用计数器变为0时会进行垃圾回收(对象销毁、refchain中移除).
但是,在python对于那些可以有多个元素组成的对象可能会存在循环引用的问题,为了解决这个问题python又引入了标记清除和分代回收,在其内部都为4个链表。
- refchain
- 2代
- 1代
- 0代
在源码中当达到各自的阈值时,,就会触发扫描器进行标记清除的动作(有循环各自-1)
但是,源码内部在上述的流程中提出了优化机制。
python缓存
池
为了避免重复创建和销毁一些常见对象、维护池。
v1 = 7
v2 = 3
v3 = 3
为了节省资源、python只会创建两个资源
池的范围在 -5、 -4 到257
当数据大于257的时候,python会单独在内存中创建资源。
池(int、字符串)
free_list
当一个对象的引用计数器为0时,按道理讲应该会回收,但是在python中不会直接回收,而是将对象添加到free_list链表中当缓存,以后再去创建对象时,不再重新开辟内存,而是直接使用free_list.
v1 = 3.14 开辟内存,内部存储结构中定义那几个值,并存到refchain中
del v1 refchain中移除,将对象添加到free_list中【80个】,free_list满了才销毁。
v9 = 9999 不会重新开辟内存,去free_list中获取对象,对象内部数据初始化,再放到refchain中
python内存管理&垃圾回收的更多相关文章
- [Python之路] 内存管理&垃圾回收
一.python源码 1.准备源码 下载Python源码:https://www.python.org/ftp/python/3.8.0/Python-3.8.0.tgz 解压得到文件夹: 我们主要关 ...
- Java 类加载机制 ClassLoader Class.forName 内存管理 垃圾回收GC
[转载] :http://my.oschina.net/rouchongzi/blog/171046 Java之类加载机制 类加载是Java程序运行的第一步,研究类的加载有助于了解JVM执行过程,并指 ...
- 内存管理 垃圾回收 C语言内存分配 垃圾回收3大算法 引用计数3个缺点
小结: 1.垃圾回收的本质:找到并回收不再被使用的内存空间: 2.标记清除方式和复制收集方式的对比: 3.复制收集方式的局部性优点: https://en.wikipedia.org/wiki/C_( ...
- [CLR via C#]21. 自动内存管理(垃圾回收机制)
目录 理解垃圾回收平台的基本工作原理 垃圾回收算法 垃圾回收与调试 使用终结操作来释放本地资源 对托管资源使用终结操作 是什么导致Finalize方法被调用 终结操作揭秘 Dispose模式:强制对象 ...
- Python内存管理:垃圾回收
http://blog.csdn.net/pipisorry/article/details/39647931 Python GC主要使用引用计数(reference counting)来跟踪和回收垃 ...
- 【python测试开发栈】—python内存管理机制(二)—垃圾回收
在上一篇文章中(python 内存管理机制-引用计数)中,我们介绍了python内存管理机制中的引用计数,python正是通过它来有效的管理内存.今天来介绍python的垃圾回收,其主要策略是引用计数 ...
- python内存管理及垃圾回收
一.python的内存管理 python内部将所有类型分成两种,一种由单个元素组成,一种由多个元素组成.利用不同结构体进行区分 /* Nothing is actually declared to b ...
- Python 内存管理与垃圾回收
Python 内存管理与垃圾回收 参考文献:https://pythonav.com/wiki/detail/6/88/ 引用计数器为主标记清除和分代回收为辅 + 缓存机制 1.1 大管家refcha ...
- 转发:[Python]内存管理
本文为转发,原地址为:http://chenrudan.github.io/blog/2016/04/23/pythonmemorycontrol.html 本文主要为了解释清楚python的内存管理 ...
随机推荐
- 1.ASP.NET Core 管道、中间件、依赖注入
自定义中间件(基于工厂) 自定义中间件(注入到第三方容器)
- k8s二进制部署 - dashboard安装
配置资源清单rbac.yaml apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard ...
- 在kubernetes集群里集成Apollo配置中心(1)之交付Apollo-configservice至Kubernetes集群
1.Apollo简介 Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境.不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限.流程治理等特性,适用于微 ...
- 二进制安装kubernetes(二) kube-apiserver组件安装
根据架构图,我们的apiserver部署在hdss7-21和hdss7-22上: 首先在hdss7-200上申请证书并拷贝到21和22上: 创建证书文件: # cd /opt/certs # vi c ...
- 计蒜客第五场 UCloud 的安全秘钥(中等) (尺取游标法
每个 UCloud 用户会构造一个由数字序列组成的秘钥,用于对服务器进行各种操作.作为一家安全可信的云计算平台,秘钥的安全性至关重要.因此,UCloud 每年会对用户的秘钥进行安全性评估,具体的评估方 ...
- 计蒜客 第四场 C 商汤科技的行人检测(中等)平面几何好题
商汤科技近日推出的 SenseVideo 能够对视频监控中的对象进行识别与分析,包括行人检测等.在行人检测问题中,最重要的就是对行人移动的检测.由于往往是在视频监控数据中检测行人,我们将图像上的行人抽 ...
- java之 javassist简单使用
0x01.javassist介绍 什么是javassist,这个词一听起来感觉就很懵,对吧~ public void DynGenerateClass() { ClassPool pool = Cla ...
- μC/OS-III---I笔记7---消息队列
消息队列 任务之间仅仅靠信号量进行"沟通"是不够的,信号量可以标志事件的发生,却无法传递更多的数据,在需要任务间的数据信息传递时就绪要用到消息队列,传统我们一般在前后太系统中都是通 ...
- 动态规划算法 All In One
动态规划算法 All In One dynamic programming leetcode https://leetcode.com/tag/dynamic-programming/ https:/ ...
- The State of JavaScript 2019
The State of JavaScript 2019 https://stateofjs.com/ https://survey.stateofjs.com/ https://2018.state ...