Celery:进一步探索
一、创建Celery专用模块
对于大型项目,一般需要创建一个专用模块,便于管理。
1.1 模块结构
proj/__init__.py
/celery.py
/tasks.py
proj/celery.py
from celery import Celery
app = Celery('proj',
broker='amqp://',
backend='rpc://',
include=['proj.tasks'])
app.conf.update(
result_expires=3600,
)
# include参数是 worker 进程启动时要导入的模块的列表。需要在此处添加我们的任务模块,以便 workers 能够找到我们的任务。
proj/tasks.py
from .celery import app
@app.task
def add(x, y):
return x + y
@app.task
def mul(x, y):
return x * y
@app.task
def xsum(numbers):
return sum(numbers)
1.2 启动 worker 进程
$ celery -A proj worker -l INFO
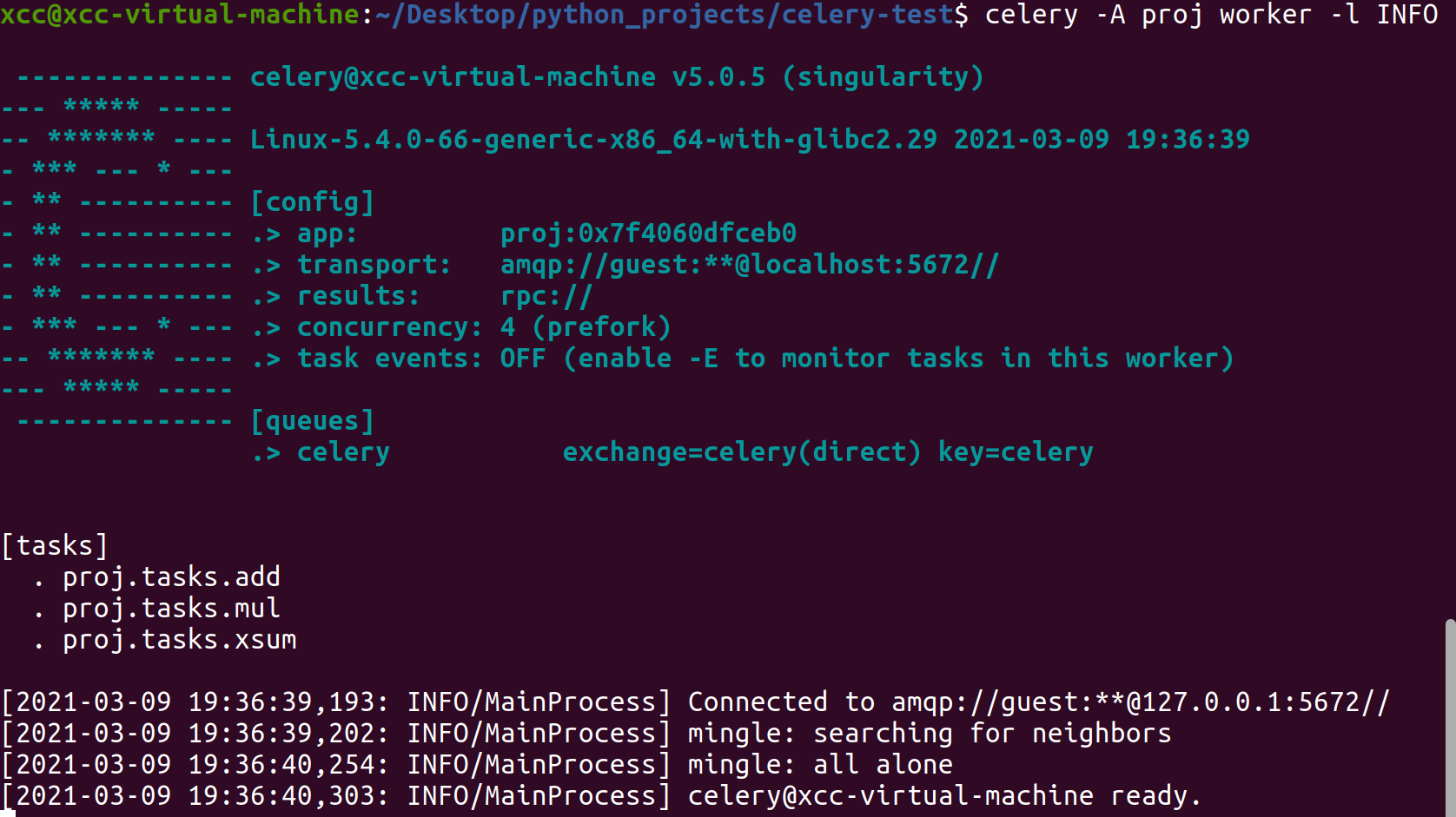
- Concurrency:是用于同时处理任务的最大工作进程数,默认是CPU核心数,详情见
celery worker -c。Celery还支持使用Eventlet,Gevent并在单个线程中运行(请参阅Concurrency) - task events:是否发送Celery的监控信息,用于如Flower之类的实时监控程序,详见Monitoring and Management guide.
- queues:worker进程可以拿取任务的队列集合,可以规定worker一次从多个队列中拿取任务,定制更高级的生产者消费者模型时参见Routing Guide、Workers Guide.
1.3 停止 worker 进程
当worker进程已经在前台运行时,使用 Control-c 即可停止运行。
1.4 后台运行 worker 进程
在生产环境,一般将Celery worker在后台运行,且使用celery multi命令在后台启动一个或多个worker进程。
启动:
$ celery multi start w1 -A proj -l INFO
重启:
$ celery multi restart w1 -A proj -l INFO
停止:
# 停止,但不会等待工作程序关闭
$ celery multi stop w1 -A proj -l INFO
# 停止,并确保在退出之前已完成所有当前正在执行的任务
$ celery multi stopwait w1 -A proj -l INFO
二、调用 Celery 任务
可以使用delay()函数调用任务:
>>> from proj.tasks import add
>>> add.delay(2, 2)
delay()方法实际上是apply_async()方法的快捷方式:
>>> add.apply_async((2, 2))
使用apply_async()方法可以指定选项,如运行时间,应发送到的队列等:
>>> add.apply_async((2, 2), queue='lopri', countdown=10)
# 任务将被发送到名为的队列中lopri,并且任务将最早在消息发送后10秒钟执行
若直接应用任务将在当前进程中执行任务,不会发送任何消息:
>>> add(2, 2)
4
使用上述三种方法组成了 Celery 任务调用的API接口, Calling User Guide 中有更详尽的描述。
三、查看任务状态
每个任务调用都将被赋予一个唯一的标识符(UUID)即任务ID:
>>> res.id
d6b3aea2-fb9b-4ebc-8da4-848818db9114
result.get()出错时默认情况下会抛出异常,传递propagate参数可以不抛出异常,而是返回一个异常对象
>>> res.get(propagate=False)
TypeError("unsupported operand type(s) for +: 'int' and 'str'")
查看任务执行结果:
>>> res.failed()
True
>>> res.successful()
False
>>> res.state
'FAILURE'
- 关于查看任务状态的详细设置: States
- 关于执行任务的详细设置: Calling Guide
四、设计任务工作流
4.1 函数签名
是有我们可能希望将一个 “任务调用” 传递给另一个进程,或者作为另一个函数的参数,于是Celery为此使用了一种称为signature的函数。它包装单个“ 任务调用” 的参数和执行选项,这个 signature 可以传递给函数,甚至可以序列化并通过网络发送。
创建一个任务签名:
>>> add.signature((2, 2), countdown=10)
tasks.add(2, 2)
# 快捷方式:
>>> add.s(2, 2)
tasks.add(2, 2)
一个签名也是一个任务,也可以调用delay和apply_async方法执行,区别在于签名可能已经指定了参数签名,完整的签名可以直接执行:
>>> s1 = add.s(2, 2)
>>> res = s1.delay()
>>> res.get()
4
也可以创建不完整的签名,在在调用签名时补全其他参数(重复的参数会被新参数替代):
>>> s2 = add.s(2)
>>> res = s2.delay(8)
>>> res.get()
10
所以,创建一个函数签名到底用来干啥呢?下面要说的 canvas 原语会用到。
4.2 原语
所谓原语,一般是指由若干条指令组成的程序段,用来实现某个特定功能,在执行过程中不可被中断。我们执行异步任务时,也可能会遇到这样的业务场景,即一组任务要么全部成功,要么全部失败。 canvas 原语就是用来定义这一组任务的执行,通过多种方式组合它们以构成复杂的工作流程。
canvas 原语包括以下六种:
Groups
一个 group 会并行调用任务列表,返回一个特殊的结果实例,该实例让我们可以将结果作为一个组进行检查,并按顺序检索返回值。
>>> from celery import group
>>> from proj.tasks import add
>>> group(add.s(i, i) for i in range(10))().get()
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
使用不完整签名函数的group:
>>> g = group(add.s(i) for i in range(10))
>>> g(10).get()
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
Chains
链式调用,前者的结果作为后者的一个输入:
>>> from celery import chain
>>> from proj.tasks import add, mul
# (4 + 4) * 8
>>> chain(add.s(4, 4) | mul.s(8))().get()
64
partial chain:
>>> # (? + 4) * 8
>>> g = chain(add.s(4) | mul.s(8))
>>> g(4).get()
64
可以直接省略chain关键字:
>>> (add.s(4, 4) | mul.s(8))().get()
64
Chords
chords 用于调用一个 group 的结果:
>>> from celery import chord
>>> from proj.tasks import add, xsum
>>> chord((add.s(i, i) for i in range(10)), xsum.s())().get()
90
一个连接到 group 的 chain 会自动转化为一个chord:
>>> (group(add.s(i, i) for i in range(10)) | xsum.s())().get()
90
由于原语都是用签名函数,所以可以随意组合,如:
>>> upload_document.s(file) | group(apply_filter.s() for filter in filters)
有关工作流程的更多信息:Canvas
五、路由
Celery支持AMQP协议提供的所有路由功能,也支持简单的路由规则,即:将消息发送的指定的队列。
task_routes参数可以按名称路由任务,并将所有内容集中在一个位置:
app.conf.update(
task_routes = {
'proj.tasks.add': {'queue': 'hipri'},
},
)
然后,可以让 worker进程 在指定的队列中拿取任务:
$ celery -A proj worker -Q hipri
还可以为 worker进程 指定多个队列,例如让 worker进程 从 hipri队列 和 默认队列 中拿取任务(由于历史原因,celery队列就是默认队列):
$ celery -A proj worker -Q hipri,celery
队列的顺序无关紧要,因为 worker进程 将给予队列同等的权重,要了解有关路由的更多信息,包括充分利用AMQP路由功能,参阅Routing Guide。
六、远程监控
如果使用RabbitMQ,Redis或Qpid作为代理,则可以在运行时监控 worker进程。
例如,可以查看worker进程当前正在执行的任务:
$ celery -A proj inspect active
这是通过使用广播消息传递实现的,因此群集中的每个 worker 都将接收所有远程控制命令。如果未提供目的地,那么每个 worker 都会响应并回复请求,使用--destination选项指定一个或多个 worker 对请求执行操作,这是 worker 主机名的逗号分隔列表:
$ celery -A proj inspect active --destination=celery@example.com
其他更多监控命令,参考Monitoring Guide
七、时区
Celery内部和消息默认使用UTC时区,当 worker 收到一条消息(例如设置了倒计时)时,它将该UTC时间转换为本地时间。如果希望使用与系统时区不同的时区,则必须使用以下timezone设置进行配置:
app.conf.timezone = 'Asia/Shanghai'
八、进一步优化
默认配置未针对吞吐量进行优化,默认情况下,它尝试在许多短期任务和较少的长期任务之间折衷,即吞吐量和公平调度间的折衷。
如果有严格的公平调度要求,或者要针对吞吐量进行优化,参阅Optimizing Guide。
如果使用RabbitMQ,则可以安装librabbitmq模块,这是用C实现的AMQP客户端:
$ pip install librabbitmq
Celery:进一步探索的更多相关文章
- aync await 进一步探索
aync await 进一步探索 首先来个例子 class Program { static int index = 1; static void Log(string str) { Console. ...
- 进一步探索:Windows Azure 网站中解锁的配置选项
编辑人员注释: 本文章由 Windows Azure 网站团队的项目经理 Erez Benari 撰写. 在 Windows Azure 网站 (WAWS) 中管理网站时,许多选项可使用 Azu ...
- Python标准库11 多进程探索 (multiprocessing包)
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 在初步了解Python多进程之后,我们可以继续探索multiprocessing包 ...
- Hadoop2源码分析-RPC探索实战
1.概述 在<Hadoop2源码分析-RPC机制初识>博客中,我们对RPC机制有了初步的认识和了解,下面我们对Hadoop V2的RPC机制做进一步探索,在研究Hadoop V2的RPC机 ...
- 每一行代码都有记录—如何用git一步步探索项目的历史
每一行代码都有一块被隐藏了的文档信息. 下面的代码片段不管是谁写的,其第4行因为某些原因要访问一个DOM结点的clientLeft属性,但却对结果不作任何处理.这十分的莫名其妙,你能告诉我他们为什么要 ...
- 企查查app 初步探索
企查查app sign算法破解初步探索 之前有说过企查查的sign的解密,但这次是企查查app的sign算法破解,目前是初步进程. 已删除!!!! 上边一些变量已经找到了,其中就有时间戳,其余两个需要 ...
- python_lesson2 多进程探索 (multiprocessing包)
进程池 进程池 (Process Pool)可以创建多个进程.这些进程就像是随时待命的士兵,准备执行任务(程序).一个进程池中可以容纳多个待命的士兵. import multiproces ...
- [源码解析] 并行分布式任务队列 Celery 之 消费动态流程
[源码解析] 并行分布式任务队列 Celery 之 消费动态流程 目录 [源码解析] 并行分布式任务队列 Celery 之 消费动态流程 0x00 摘要 0x01 来由 0x02 逻辑 in komb ...
- 探索专有领域的端到端ASR解决之道
摘要:本文从<Shallow-Fusion End-to-End Contextual Biasing>入手,探索解决专有领域的端到端ASR. 本文分享自华为云社区<语境偏移如何解决 ...
随机推荐
- Jmeter入门使用
1. 什么是Jmeter 转自:https://www.cnblogs.com/lijuanhu321/p/9537185.html#testComponent https://www.cnblogs ...
- Jpress小程序
首页轮播.首页公告.首页宫格.个人中心页面均支持在PC后台设置内容 首页列表.分类列表页.搜索列表的文章展示页均支持后台设置,拥有三种风格 所有分类展示支持两种风格 用户中心授权登陆,查看个人数据 J ...
- Ubuntu Live CD联网修复
此模式下可以联网修复ubuntu系统下绝大多数问题.进入LIVE CD模式,打开终端执行以下命令: #此处/dev/sda1为ubuntu根分区,工作中根据实际分区情况更改 sudo mount /d ...
- Java之一个整数的二进制中1的个数
这是今年某公司的面试题: 一般思路是:把整数n转换成二进制字符数组,然后一个一个数: private static int helper1(int i) { char[] chs = Integer. ...
- Python源码剖析——01内建对象
<Python源码剖析>笔记 第一章:对象初识 对象是Python中的核心概念,面向对象中的"类"和"对象"在Python中的概念都为对象,具体分为 ...
- HDU 4628 Pieces(状压DP)题解
题意:n个字母,每次可以删掉一组非连续回文,问你最少删几次 思路:把所有回文找出来,然后状压DP 代码: #include<set> #include<map> #includ ...
- 强网杯 2019]随便注(堆叠注入,Prepare、execute、deallocate)
然后就是今天学的新东西了,堆叠注入. 1';show databases; # 1';show tables; # 发现两个表1919810931114514.words 依次查询两张表的字段 1'; ...
- 深入理解JavaScript中的类继承
由于写本文时全部是在编辑器中边写代码边写感想的,所以,全部思想都写在代码注释里面了 // 类继承 //todo.1 extends 关键字 class Animal { constructor(nam ...
- vuepress & ReferenceError: window is not defined
vuepress & ReferenceError: window is not defined bug Client Compiled successfully in 15.35s Serv ...
- Python errors All In One
Python errors All In One SyntaxError: invalid character in identifier \u200b, ZERO WIDTH SPACE https ...