Python 网站后台扫描脚本
Python 网站后台扫描脚本
#!/usr/bin/python
#coding=utf-8
import sys
import urllib
import time
url = "http://123.207.123.228/"
txt = open(r"C:\Users\ww\Desktop\houtaiphp.txt","r")
open_url = []
all_url = []
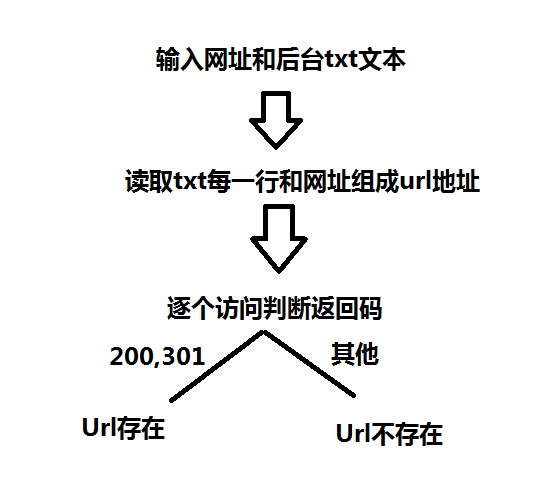
def search_url(url,txt):
with open(r"C:\Users\ww\Desktop\houtaiphp.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = url+each
all_url.append(urllist)
print("查找:"+urllist+'\n')
try:
req = urllib.urlopen(urllist)
if req.getcode() == 200:
open_url.append(urllist)
if req.getcode() == 301:
open_url.append(urllist)
except:
pass
def main():
search_url(url,txt)
if open_url:
print("后台地址:")
for each in open_url:
print("[+]"+each)
else:
print("没有找到网站后台")
if __name__ == "__main__":
main()
#!/usr/bin/python
#coding=utf-8
import sys
import urllib
import time
url = "http://123.207.123.228/"
txt = open(r"C:\Users\ww\Desktop\houtaiphp.txt","r")
open_url = []
all_url = []
def search_url(url,txt):
with open(r"C:\Users\ww\Desktop\houtaiphp.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = url+each
all_url.append(urllist)
handle_url(urllist) def handle_url(urllist):
print("查找:"+urllist+'\n')
try:
req = urllib.urlopen(urllist)
if req.getcode() == 200:
open_url.append(urllist)
if req.getcode() == 301:
open_url.append(urllist)
except:
pass def main():
search_url(url,txt)
if open_url:
print("后台地址:")
for each in open_url:
print("[+]"+each)
else:
print("没有找到网站后台")
if __name__ == "__main__":
main()

师傅让我多看看-->多线程
这里就加个多线程吧。
#!/usr/bin/python
#coding=utf-8
import sys
import urllib
import time
import threading
url = "http://123.207.123.228/"
txt = open(r"C:\Users\ww\Desktop\houtaiphp.txt","r")
open_url = []
all_url = []
threads = []
def search_url(url,txt):
with open(r"C:\Users\ww\Desktop\houtaiphp.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = url+each
all_url.append(urllist)
def handle_url(urllist):
print("查找:"+urllist+'\n')
try:
req = urllib.urlopen(urllist)
if req.getcode() == 200:
open_url.append(urllist)
if req.getcode() == 301:
open_url.append(urllist)
except:
pass def main():
search_url(url,txt)
for each in all_url:
t = threading.Thread(target = handle_url,args=(each,))
threads.append(t)
t.start()
for t in threads:
t.join()
if open_url:
print("后台地址:")
for each in open_url:
print("[+]"+each)
else:
print("没有找到网站后台")
if __name__ == "__main__":
start = time.clock()
main()
end = time.clock()
print("spend time is:%.3f seconds" %(end-start))
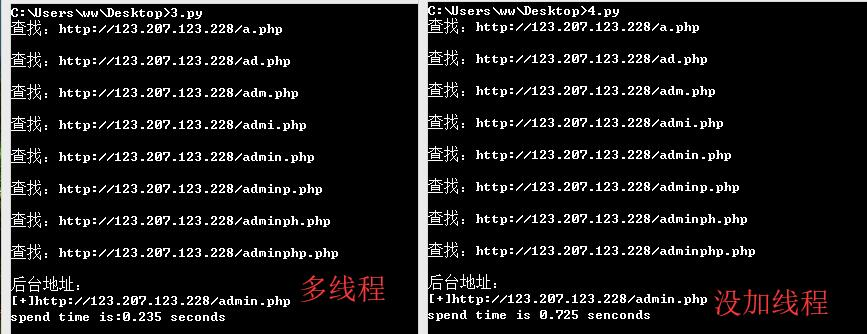
多线程和没加线程的时间对比
--------------------------------------------------------------------------------------------------------------------------------------------------
利用zoomeye搜索
调用ZoomEye API获取信息
主要涉及模块urllib,json,os模块。
# coding: utf-8
import os
import requests
import json access_token = ''
ip_list = [] def login():
"""
输入用户米密码 进行登录操作
:return: 访问口令 access_token
"""
user = raw_input('[-] input : username :')
passwd = raw_input('[-] input : password :')
data = {
'username' : user,
'password' : passwd
}
data_encoded = json.dumps(data) # dumps 将 python 对象转换成 json 字符串
try:
r = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
r_decoded = json.loads(r.text) # loads() 将 json 字符串转换成 python 对象
global access_token
access_token = r_decoded['access_token']
except Exception,e:
print '[-] info : username or password is wrong, please try again '
exit() def saveStrToFile(file,str):
"""
将字符串写如文件中
:return:
"""
with open(file,'w') as output:
output.write(str) def saveListToFile(file,list):
"""
将列表逐行写如文件中
:return:
"""
s = '\n'.join(list)
with open(file,'w') as output:
output.write(s) def apiTest():
"""
进行 api 使用测试
:return:
"""
page = 1
global access_token
with open('access_token.txt','r') as input:
access_token = input.read()
# 将 token 格式化并添加到 HTTP Header 中
headers = {
'Authorization' : 'JWT ' + access_token,
}
# print headers
while(True):
try: r = requests.get(url = 'https://api.zoomeye.org/host/search?query="phpmyadmin"&facet=app,os&page=' + str(page),
headers = headers)
r_decoded = json.loads(r.text)
# print r_decoded
# print r_decoded['total']
for x in r_decoded['matches']:
print x['ip']
ip_list.append(x['ip'])
print '[-] info : count ' + str(page * 10) except Exception,e:
# 若搜索请求超过 API 允许的最大条目限制 或者 全部搜索结束,则终止请求
if str(e.message) == 'matches':
print '[-] info : account was break, excceeding the max limitations'
break
else:
print '[-] info : ' + str(e.message)
else:
if page == 10:
break
page += 1 def main():
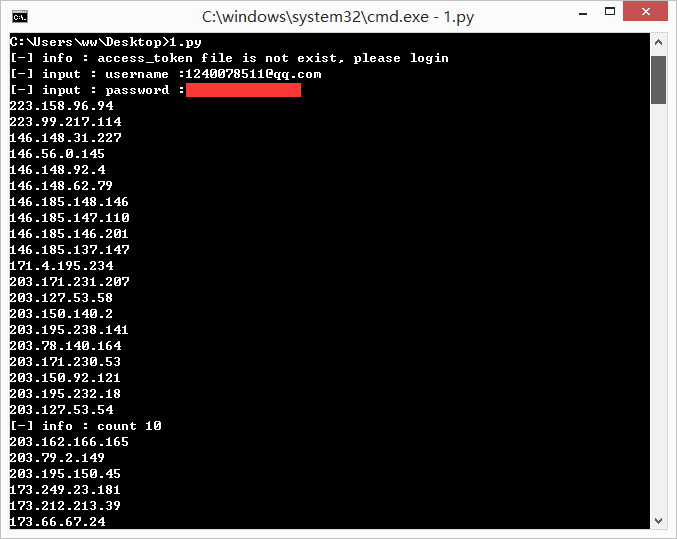
# 访问口令文件不存在则进行登录操作
if not os.path.isfile('access_token.txt'):
print '[-] info : access_token file is not exist, please login'
login()
saveStrToFile('access_token.txt',access_token) apiTest()
saveListToFile('ip_list.txt',ip_list) if __name__ == '__main__':
main()
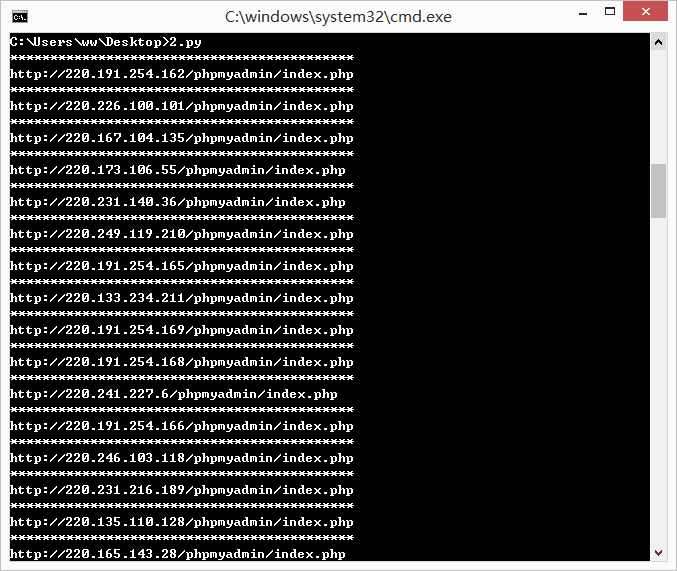
上面的脚本是搜索 phpmyadmin 的。搜索得到的 IP 会保存在同路径下的 ip_list.txt 文件。
但是搜索到的 ip 并不是都能够访问的,所以这里写个了识别 phpmyadmin 的脚本,判断是否存在,是则输出。
#!/usr/bin/python
#coding=utf-8
import sys
import time
import requests
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"}##浏览器请求头
open_url = []
all_url = []
payloa = 'http://'
payload = '/phpmyadmin/index.php'
def search_url():
with open(r"C:\Users\ww\Desktop\ip_list.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = payloa+each+payload
all_url.append(urllist)
handle_url(urllist)
def handle_url(urllist):
#print('\n'+urllist)
#print '----------------------------'
try:
start_htm = requests.get(urllist,headers=headers)
#print start_htm
if start_htm.status_code == 200:
print '*******************************************'
print urllist
except:
pass
if __name__ == "__main__":
search_url()
加个多线程,毕竟工作量很大。
#!/usr/bin/python
#coding=utf-8
import sys
import time
import requests
import threading
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"}##浏览器请求头
open_url = []
all_url = []
threads = []
payloa = 'http://'
payload = '/phpmyadmin/index.php'
def search_url():
with open(r"C:\Users\ww\Desktop\ip_list.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = payloa+each+payload
all_url.append(urllist)
#handle_url(urllist)
def handle_url(urllist):
#print('\n'+urllist)
#print '----------------------------'
try:
start_htm = requests.get(urllist,headers=headers)
#print start_htm
if start_htm.status_code == 200:
print '*******************************************'
print urllist
except:
pass
def main():
search_url()
for each in all_url:
t = threading.Thread(target=handle_url,args=(each,))
threads.append(t)
t.start()
for t in threads:
t.join()
if __name__ == "__main__":
start = time.clock()
main()
end = time.clock()
print("spend time is %.3f seconds" %(end-start))
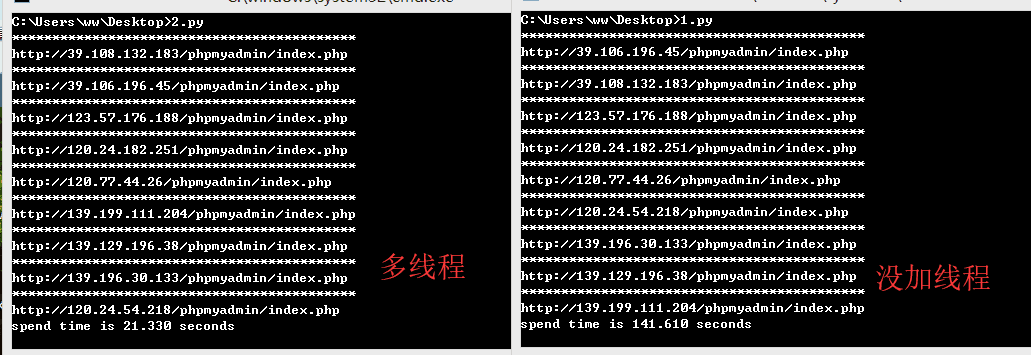
这下就方便了许多。
任重而道远!
Python 网站后台扫描脚本的更多相关文章
- Python 网站后台扫描
title date layout tags Python 网站后台扫描 2018-05-08 post Python #!/usr/bin/python # This was written for ...
- 网站后台扫描工具dirbuster、御剑的用法
dirbuster DirBuster是Owasp(Open Web Application Security Project )开发的一款专门用于探测网站目录和文件(包括隐藏文件)的工具.由于使用J ...
- 【Python】端口扫描脚本
0x00 使用模块简介 1.optparse模块 选项分析器,可用来生成脚本使用说明文档,基本使用如下: import optparse #程序使用说明 usage="%prog -H ...
- [python]MS17-010自动化扫描脚本
一种是3gstudent分享的调用Nsa泄露的smbtouch-1.1.1.exe实现验证,另一种是参考巡风的poc.这里整合学习了下两种不同的方法. import os import fileinp ...
- 转战网站后台与python
这么长时间了,迷茫的大雾也逐渐散去,正如标题所写的一样,转战网站后台开发.这段时间没怎么写博客,主要还是太忙,忙着期末考试的预习,以及服务器的搭建,python的学习,还有各种各样杂七杂八的小事,就像 ...
- python模块之sys和subprocess以及编写简单的主机扫描脚本
python模块之sys和subprocess以及编写简单的主机扫描脚本 1.sys模块 sys.exit(n) 作用:执行到主程序末尾,解释器自动退出,但是如果需要中途退出程序,可以调用sys.e ...
- BBScan — 一个信息泄漏批量扫描脚本
github:https://github.com/lijiejie/BBScan 有些朋友手上有几十万甚至上百万个域名,比如,乌云所有厂商的子域名. 如果把这30万个域名全部扔给wvs,APPsca ...
- 通过SQL注入获得网站后台用户密码
通过 SQL 注入攻击,掌握网站的工作机制,认识到 SQL 注入攻击的防范措施,加强对 Web 攻击的防范. 一.实验环境 下载所需代码及软件:获取链接:链接:https://pan.baidu.co ...
- 通过COOKIE欺骗登录网站后台
1.今天闲着没事看了看关于XSS(跨站脚本攻击)和CSRF(跨站请求伪造)的知识,xss表示Cross Site Scripting(跨站脚本攻击),它与SQL注入攻击类似,SQL注入攻击中以SQL语 ...
随机推荐
- Some notes in Stanford CS106A(1)
Karel world 1.During make a divider operation --int x=5; double y = x/2 => y=2 we need sth as a ...
- WEB学习笔记11-高可读性的HTML之如何设置网页标题层级
标题标签指的是<h1>~<h6>这6个标签,统称为<hx>标签. (1)在页面内容的标题部分使用<hx>标签 <h1 class="re ...
- VirtualBox 使用物理硬盘
/******************************************************************************* * VirtualBox 使用物理硬盘 ...
- 常用git操作命令
查看远程仓库 ->$ git remote -v 如果你本地有一个项目,想把他放到远程git服务器上,那就用上面的命令把项目 add 到远程服务器 ->$ git remote a ...
- 炸金花游戏(4)--炸金花AI基准测试评估
前言: 本文将谈谈如何评估测试炸金花的AI, 其实这个也代表一类的问题, 德州扑克也是类似的解法. 本文将谈谈两种思路, 一种是基于基准AI对抗评估, 另一种是基于测试集(人工选定牌谱). 由于炸金花 ...
- 42.输入一个递增排序的数组和一个数字S,在数组中查找两个数,使得他们的和正好是S, 如果有多对数字的和等于S,输出两个数的乘积最小的。
输入一个递增排序的数组和一个数字S,在数组中查找两个数,使得他们的和正好是S, 如果有多对数字的和等于S,输出两个数的乘积最小的. 这道题有很多烟雾弹: 首先如果有多对,最前面的两个数就是乘积最小的, ...
- celery使用rabbitmq报错[Errno 104] Connection reset by peer.
写好celery任务文件,使用celery -A app worker --loglevel=info启动时,报告如下错误: [2019-01-29 01:19:26,680: ERROR/MainP ...
- i3wm菜单
抛弃i3-dmenu-desktop吧,投入到 j4-demu-desktop 速度超快
- mysql 导入数据库问题
今天数据库迁移测试,发现存储过程导入不了,提示如下错误: Cannot load from mysql.proc. The table is probably corrupted 原因是mysql5. ...
- 转发: 探秘Java中的String、StringBuilder以及StringBuffer
原文地址 探秘Java中String.StringBuilder以及StringBuffer 相信String这个类是Java中使用得最频繁的类之一,并且又是各大公司面试喜欢问到的地方,今天就来和大家 ...