语言模型(N-Gram)
问题描述:由于公司业务产品中,需要用户自己填写公司名称,而这个公司名称存在大量的乱填现象,因此需要对其做一些归一化的问题。在这基础上,能延伸出一个预测用户填写的公司名是否有效的模型出来。
目标:问题提出来了,就是想找到一种办法来预测用户填写的公司名是否有效?
问题分析:要想预测用户填写的公司名称是否有效,需要用到NLP的知识内容,我们首先能够想到的是利用NLP中的语言模型,来对公司名称进行训练建模,并结合其他的特征(如:长度等)进行预测。
一、N-Gram的原理
N-Gram是基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关。(这也是隐马尔可夫当中的假设。)整个句子出现的概率就等于各个词出现的概率乘积。各个词的概率可以通过语料中统计计算得到。假设句子T是有词序列w1,w2,w3...wn组成,用公式表示N-Gram语言模型如下:
P(T)=P(w1)*p(w2)*p(w3)***p(wn)=p(w1)*p(w2|w1)*p(w3|w1w2)***p(wn|w1w2w3...)
一般常用的N-Gram模型是Bi-Gram和Tri-Gram。分别用公式表示如下:
Bi-Gram: P(T)=p(w1|begin)*p(w2|w1)*p(w3|w2)***p(wn|wn-1)
Tri-Gram: P(T)=p(w1|begin1,begin2)*p(w2|w1,begin1)*p(w3|w2w1)***p(wn|wn-1,wn-2)
- 注意上面概率的计算方法:P(w1|begin)=以w1为开头的所有句子/句子总数;p(w2|w1)=w1,w2同时出现的次数/w1出现的次数。以此类推。(这里需要进行平滑)
二、N-Gram的应用
根据上面的分析,N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念,通常在NLP中,它主要有两个重要应用场景:
(1)、人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。
(2)、另外一方面,N-Gram的另外一个作用是用来评估两个字符串之间的差异程度。这是模糊匹配中常用的一种手段。
1、N-gram在两个字符串的模糊匹配中的应用
首先需要介绍一个比较重要的概念:N-Gram距离。
(1)N-gram距离
它是表示,两个字符串s,t分别利用N-Gram语言模型来表示时,则对应N-gram子串中公共部分的长度就称之为N-Gram距离。例如:假设有字符串s,那么按照N-Gram方法得到N个分词组成的子字符串,其中相同的子字符串个数作为N-Gram距离计算的方式。具体如下所示:
字符串:s="ABC",对字符串进行分词,考虑字符串首尾的字符begin和end,得到begin,A,B,C,end。这里采用二元语言模型,则有:(begin,A)、(A,B)、(B,C)、(C,end)。
字符串:t="AB",对字符串进行分词,考虑字符串首尾的字符begin和end,得到begin,A,B,end。这里采用二元语言模型,则有:(begin,A)、(A,B)、(B,end)。
此时,若求字符串t与字符串s之间的距离可以用M-(N-Gram距离)=0。
然而,上面的N—gram距离表示的并不是很合理,他并没有考虑两个字符串的长度,所以在此基础上,有人提出非重复的N-gram距离,公式如下所示:
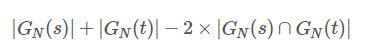
上面的字符串距离重新计算为:
4+3-2*3=1
2、N-Gram在判断句子有效性上的应用
假设有一个字符串s="ABC",则对应的BI-Gram的结果如下:(begin,A)、(A,B)、(B,C)、(C,end)。则对应的出现字符串s的概率为:
P(ABC)=P(A|begin)*P(B|A)*P(C|B)*P(end|C)。
3、N-Gram在特征工程中的应用
在处理文本特征的时候,通常一个关键词作为一个特征。这也许在一些场景下可能不够,需要进一步提取更多的特征,这个时候可以考虑N-Gram,思路如下:
以Bi-Gram为例,在原始文本中,以每个关键词作为一个特征,通过将关键词两两组合,得到一个Bi-Gram组合,再根据N-Gram语言模型,计算各个Bi-Gram组合的概率,作为新的特征。
语言模型(N-Gram)的更多相关文章
- [转]语言模型训练工具SRILM
SRILM是一个建立和使用统计语言模型的开源工具包,从1995年开始由SRI 口语技术与研究实验室(SRI Speech Technology and Research Laboratory)开发,现 ...
- 斯坦福大学自然语言处理第四课“语言模型(Language Modeling)”
http://52opencourse.com/111/斯坦福大学自然语言处理第四课-语言模型(language-modeling) 一.课程介绍 斯坦福大学于2012年3月在Coursera启动了在 ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- 语言模型srilm基本用法
目录: 一基本训练 二语言模型打分 三语言模型剪枝 四语言模型合并 五语言模型使用词典限制 一.基本训练 #功能 读取分词后的text文件或者count文件,然后用来输出最后汇总的count文件或者语 ...
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 语言模型 N-gram 与其平滑方法推导
N-gram N-gram 作为一个名词表示的是一个给定文本/音频样本中有n项(音素,音节,字母,单词)的一个连续序列. 数学表达 N-gram 模型表示的是当前这个 word \(w_i\) 依赖于 ...
- 语言模型kenlm的训练及使用
一.背景 近期研究了一下语言模型,同事推荐了一个比较好用的工具包kenlm,记录下使用过程. 二.使用kenlm训练 n-gram 1.工具介绍:http://kheafield.com/code/k ...
- CSC321 神经网络语言模型 RNN-LSTM
主要两个方面 Probabilistic modeling 概率建模,神经网络模型尝试去预测一个概率分布 Cross-entropy作为误差函数使得我们可以对于观测到的数据 给予较高的概率值 同时可以 ...
- language model —— basic model 语言模型之基础模型
一.发展 起源:统计语言模型起源于 Ponte 和 Croft 在 1998年的 SIGIR上发表的论文 应用:语言模型的应用很多: corsslingual retrieval distribute ...
随机推荐
- 在linux 上安装ansible
ansible 在线安装:yum install -y epel-releaseyum install -y ansible离线安装:rpm wget https://releases.ansible ...
- 第 8 章 容器网络 - 072 - 一文搞懂各种 Docker 网络
Docker 起初只提供了简单的 single-host 网络,显然这不利于 Docker 构建容器集群并通过 scale-out 方式横向扩展到多个主机上. 跨主机网络方案: Docker Over ...
- NetSec2019 20165327 Exp0 Kali安装 Week1
NetSec2019 20165327 Exp0 Kali安装 Week1 一.下载并安装Kali和VMware kali在官网下载,VMware上学期已安装 安装如下步骤: 选典型: 选稍后安装操作 ...
- Flutter工程无法找到Android真机或Android模拟器
之前的Flutter的工程链接真机还好好的 结果电脑抽抽了过了个年就连不到真机了 一点run就提示 No connected devices found; please connect a devic ...
- zabbix报错gd、freetype、png、jpeg
安装包位置:http://www.p-pp.cn/app/zabbix/ 1.安装freetype [root@localhost softs]# tar xf freetype-2.5.0.tar. ...
- 突破防盗链Referrer
//引用的源码网站的js<script src="https://raw.githack.com/jpgerek/referrer-killer/master/referrer-kil ...
- 【IDEA填坑】springboot整合ssm框架
遇到俩问题:一个是mybatis生疏 在EmpMapper.xml中定义resultMap <resultMap id="EmpWithDept" type="c ...
- Layui追加合计
parseData: function(res) { //将原始数据解析成table组件所规定的数据 admin.restest(res); var list = new Array(); var t ...
- wget 使用
1.很多软件官网会有安装脚本,并把脚本搞成raw模式,方便下载后直接运行的shell文件.比如docker wget -qO- get.docker.com | bash -q的含义是:--quiet ...
- JVM常用配置参数说明
堆设置 -Xms256M:初始堆大小256M,默认为物理内存的1/64 -Xmx1024M:最大堆大小1024M,默认为物理内存的1/4,等于与-XX:MaxHeapSize=64M -Xmn64M: ...