linux - word frequency
linux 输出某个文件的单词出现频率
解决方式
cat words.txt |awk '{for(i=1;i<=NF;i++) print $i;}'|sort|uniq -c|sort -r|awk '{print $2,$1;}'
1、读出文件 cat xxx.txt

2、awk 逐行读入,按空格将每行分割 然后处理 (awk 常用命令参考 https://www.cnblogs.com/xiaoleiel/p/8349487.html)
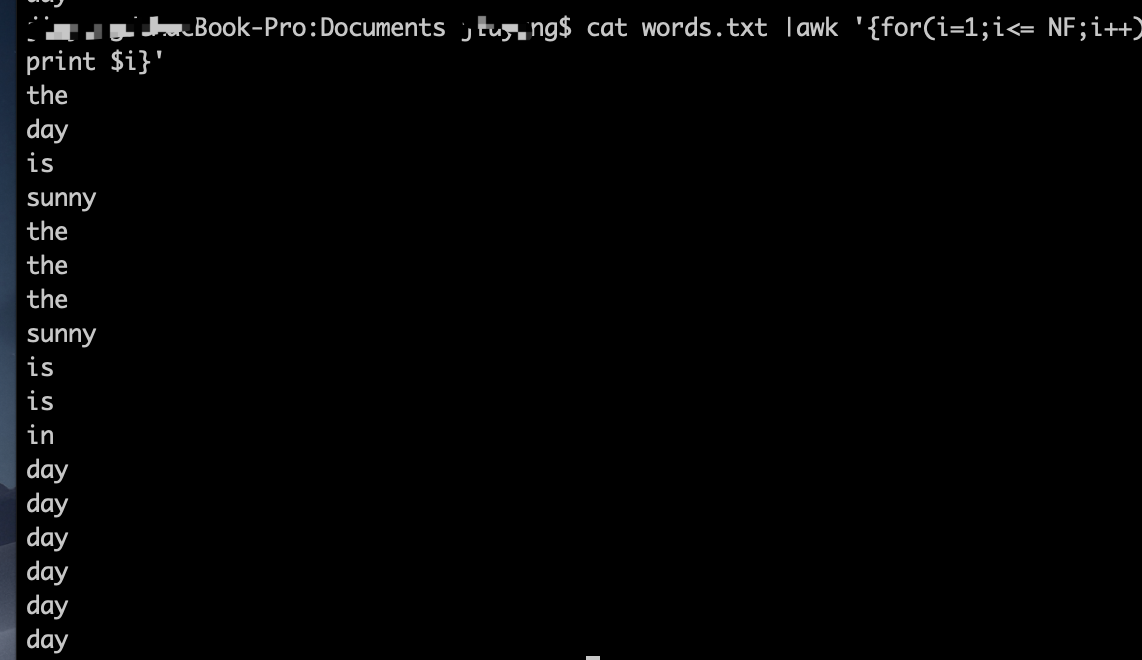
awk NF 每一行的单词数量
'{for(i=1;i<= NF;i++)print $i}' 逐行逐词输出单词
3、sort 按词排序,将相同的词语放在一起

4、uniq -c 按词统计次数
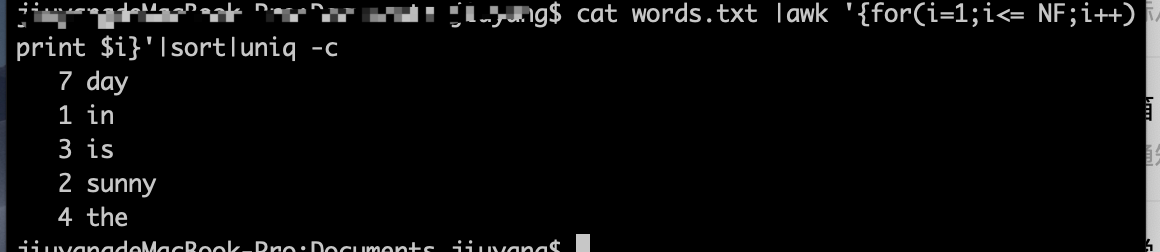
5、sort -r 按照第一行 倒叙排序

6、 awk '{print $2,$1}' 按照格式输出

sort 命令参数 http://www.runoob.com/linux/linux-comm-sort.html
参 数:
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
--help 显示帮助。
--version 显示版本信息
uniq http://www.runoob.com/linux/linux-comm-uniq.html
语法
uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][--help][--version][输入文件][输出文件] 参数:
-c或--count 在每列旁边显示该行重复出现的次数。
-d或--repeated 仅显示重复出现的行列。
-f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
-s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
-u或--unique 仅显示出一次的行列。
-w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
--help 显示帮助。
--version 显示版本信息。
[输入文件] 指定已排序好的文本文件。如果不指定此项,则从标准读取数据;
[输出文件] 指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
linux - word frequency的更多相关文章
- Individual Project - Word frequency program-11061171-MaoYu
BUAA Advanced Software Engineering Project: Individual Project - Word frequency program Ryan Mao (毛 ...
- Word Frequency
https://leetcode.com/problems/word-frequency/ Write a bash script to calculate the frequency of each ...
- [Bash]LeetCode192. 统计词频 | Word Frequency
Write a bash script to calculate the frequency of each word in a text file words.txt. For simplicity ...
- LeetCode(192. Word Frequency)
192. Word Frequency Write a bash script to calculate the frequency of each word in a text file words ...
- [LeetCode] Word Frequency 单词频率
Write a bash script to calculate the frequency of each word in a text file words.txt. For simplicity ...
- [CareerCup] 17.9 Word Frequency in a Book 书中单词频率
17.9 Design a method to find the frequency of occurrences of any given word in a book. 这道题让我们找书中单词出现 ...
- 192 Word Frequency
Write a bash script to calculate the frequency of each word in a text file words.txt. For simplicity ...
- LeetCode 192. Word Frequency
分析 写bash,不太会啊…… 难度 中 来源 https://leetcode.com/problems/word-frequency/ 题目 Write a bash script to calc ...
- Individual Project - Word frequency program - Multi Thread And Optimization
作业说明详见:http://www.cnblogs.com/jiel/p/3978727.html 一.开始写代码前的规划: 1.尝试用C#来写,之前没有学过C#,所以打算先花1天的时间学习C# 2. ...
随机推荐
- 树莓派的系统安装,并且利用网线直连 Mac 进行配置
最近单位给了我一个新的树莓派3B+让我自己玩.下面是我记录的我如何安装 Raspbian Stretch Lite 系统,然后如何成功不用独立显示屏而利用 MacBook 对其进行配置. 安装 Ras ...
- [C++] const与指针的关系
首先快速复习一些基础. 考虑下面的声明兼定义式: int p = 10; p的基础数据类型是int. 考虑下面的声明兼定义式: const int a = 10; a的基础数据类型是int,a是一个常 ...
- docker安装elasticsearch
docker search elasticsearch 选择一个版本,拉取镜像 docker pull elasticsearch: 查看镜像 docker images 通过镜像,启动一个容器,并将 ...
- IDEA中debug启动tomcat报错。Error running t8:Unable to open debugger port(127.0.0.1:49225):java.net.BindException"Address alread in use:JVM_Bind"
解决办法: 1,如下图打开项目配置的tomcat的“Edit Configurations...” 2,打开“Startup/Connection”--------"Debug"- ...
- 记一次Java动态代理实践【首发自高可用架构公众号】
1. 背景 最近在做数据库(MySQL)方面的升级改造.现状是数据库同时被多个应用直连,存在了一些问题: 有大量的重复代码,维护成本较高,也不优雅: 出现SQL语句质量的问题无法很快定位到是哪个应用导 ...
- webbrowser设置为相应的IE版本
注册表路径: HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\Internet Explorer\Main\FeatureControl\FEATU ...
- Python自动化中的鼠标事件
1)form selenium.webdriver.common.action_chains import ActionChains 导入该模块 2)ActionChains(driver) :用于 ...
- Ubuntu更新Python3及pip3
https://blog.csdn.net/good_tang/article/details/85001211 根据这篇文章的作者给出的方法进行的操作,但是其中出了两个问题: 我在操作之后重开bas ...
- Python学习笔记-CGI编程(如何在IIS上挂Python开发的Webservice)
一.如何用Python开发一个简单的Webservice 利用python的cgi编程,可以传入参数将结果输出. 定义需要编码以及需要引用的模块 #conding=utf-8 #修正中文乱码 impo ...
- JAVA学习笔记(2)—— java初始化三个原则
1. 初始化原则 (1) 静态对象(变量)优先于非静态对象(变量)初始化,其中静态对象(变量)初始化一次,非静态对象(变量)可能会初始化多次. (2) 父类优先于子类初始化 (3) 按照成 ...