[心得] SQL Server Partition(表分區) 資料分佈探討
最近在群裡有個朋友問了個問題是這樣的
用户表有一千多万行,主键是用户ID,我做了分区。但经常查询时,其它的表根据用户ID来关联,这样跨区查询,reads非常高。有什么好的处理办法?不分区的话,索引维护要好久的时间
在查看了他提供的分區資訊後,發現只有23個分區(包含一定要有的Null分區)
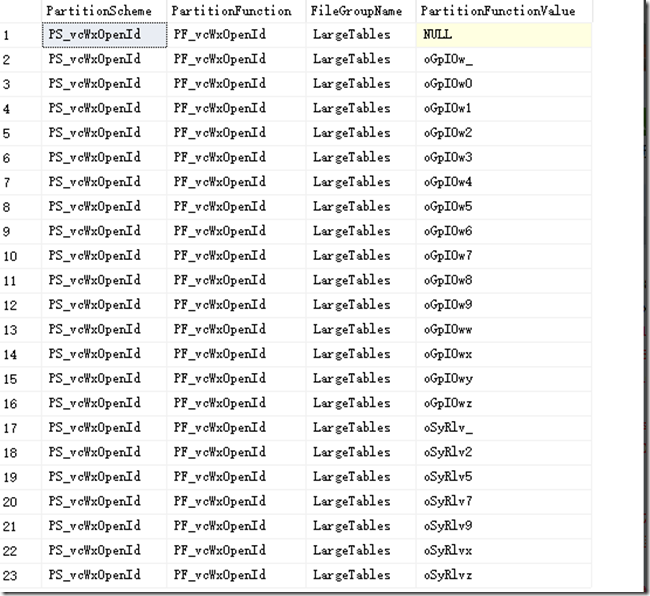
Null分區在這裡的定義其實很簡單,當你的資料沒有辦法放到你先前建立的分區時,就會將該資料放到所謂的Null分區(預設分區)。
因此如果在探尋分區規則時沒有依照現有的資料進行分區的設計,將會很容易導致資料偏斜(Data Bias),一但資料出現了偏斜時在查找時就會很容易在NULL區出現過多的讀取
以今天的案例來看待,當要比對的ID不在這22個分區中時就會到NULL分區進行查找的動作。而在群友提供的資料中其實有出現了oGpI0w_ 、mGpI0w等字眼
可以想見的是,該NULL分區的資料是相當多的
以下就一個測試情境來探討在分區規則不同時的效能比較
首先建立二張結構一樣的表,資料量約一千二百萬筆
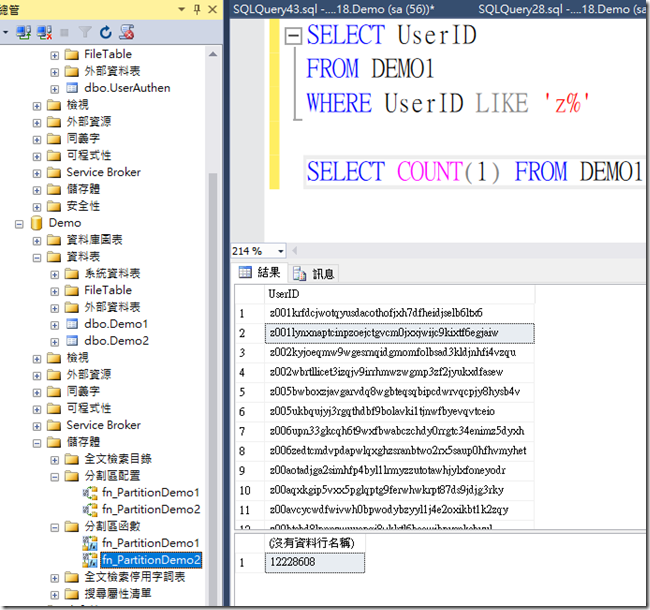
接下來分別建立給表Demo1與Demo2的表分區函數(請注意圖中的註解)
(注意,以下示範並沒有利用到分區FileGroup優化,當你用了分區時請一定要同時利用FileGroup進行優化)
一個是利用UserID前五碼分區另一個則利用前一碼進行分區
這裡要注意的是SQL Server 2016一個資料表或索引最多可以有 15,000 個資料分割
SQL Server 2005 與 2008 則需為SP2才可使用 (否則只能合計有1000個分區)
Refer : New Limit for Number of Partitions in SQL Server 2008 SP2
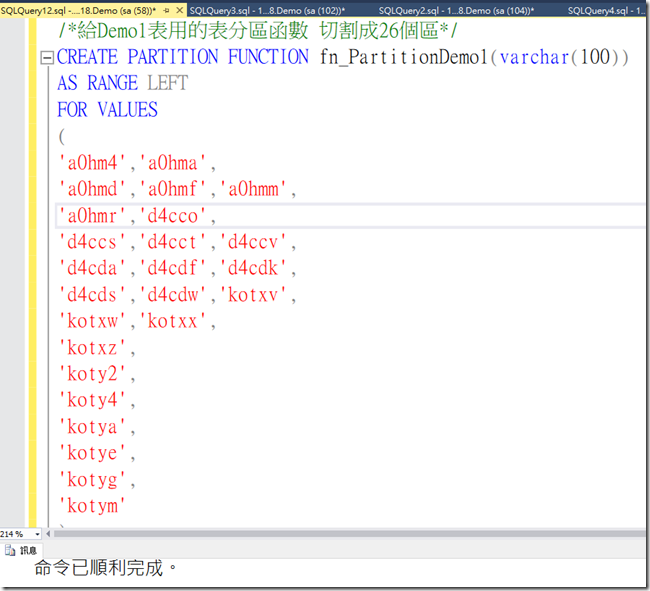
Demo1表分區函數
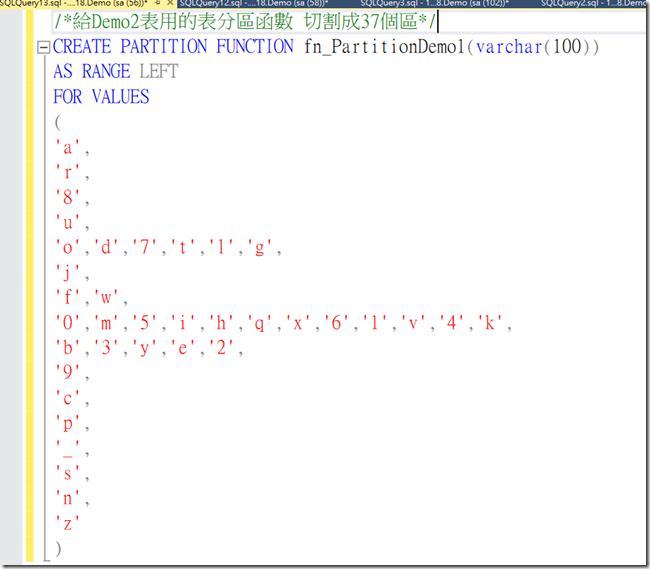
Demo2表分區函數
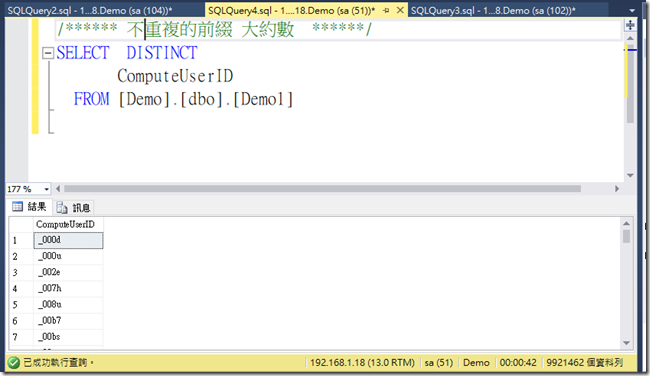
而在表中不重複前五碼的資料筆數約9百多萬,如下圖
(可以想見的是在NULL區中會有大量的資料存放)
接下來我們來看看分區後的Demo1與Demo2分區表資料分佈情形

Demo1表分區資料分佈
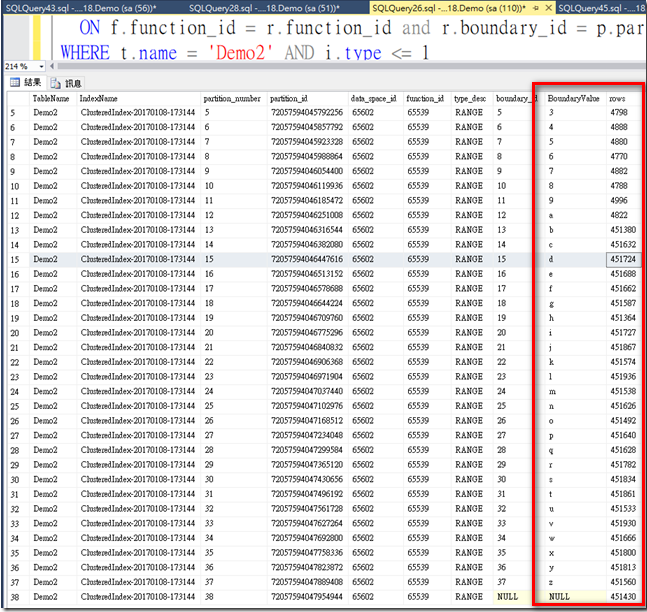

Demo2表分區資料分佈
案例:當利用LIKE做前綴查找
這裡從前述的資訊可以知道在Demo1 a0%最少有6個區需要查找
而Demo2只有一個區需要查找
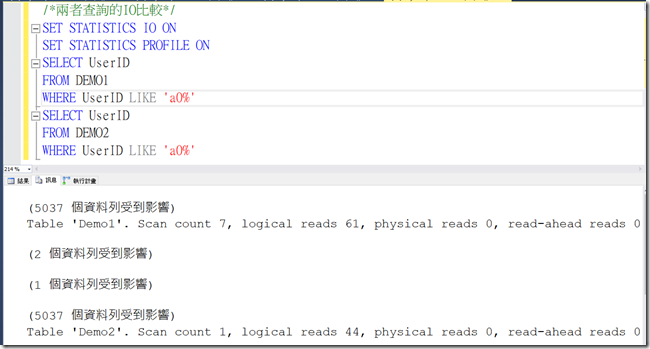
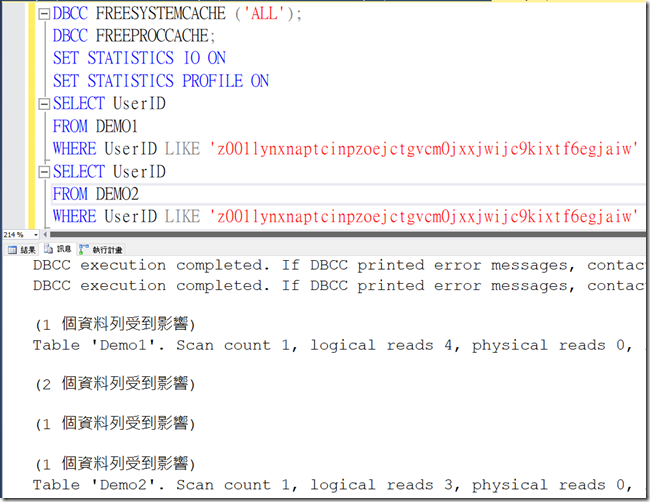
接下來我們先簡單的看一下兩張表在相同查詢時IO的差異 (可以看到第二張表較優)
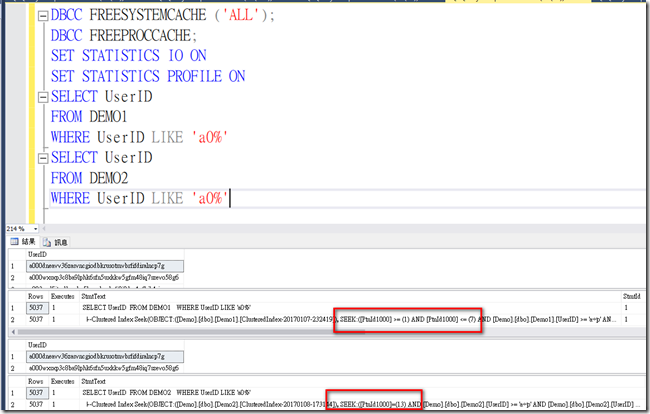
接下來我們仔細看一下相關的執行計畫與查找的分區數
可以發現在執行時Demo1會查找七個分區,而Demo2只會從一個分區中進行查找
案例:當從預設分區查找
這次我們簡單的查找z開頭的UserID ,從先前的資訊可以知道。
表Demo1並沒有建立z開頭的分區,因此z相關的資料將會存放到預設分區(Null區)
表Demo1的預設分區統計約有643萬筆,而表Demo2的z分區約有45萬筆
由此可見在Demo2表上查找應該會優於Demo1的(當資料筆數再更多時,差異會更大)
見下圖
以上便是今天的表分區探討,替各位總結一下。
1.在規劃表分區時,首先要注意該表的相關查詢語句,以最常用在條件式的字段做為分區依據是較佳的。
2.承上,即使使用最常用的字段做為分區依據,仍然要確認資料是否適合做為分區。
例如:即使常用的查詢字段為姓別 (男、女),用此字段做為分區,僅能將資料最多分為三個區。在大資料時,性能並無法顯著的增加。簡單的評估可以用目前的資料筆數除以分區數,可得知每個分區的資料分佈進而做分區建立的評估依據
比如可以用下列這種簡單的語法計算每個分區數
--12228608 / 37
SELECT COUNT(1) /
(
SELECT COUNT(1) FROM
(
SELECT 1 as Counts FROM Demo1 GROUP BY SUBSTRING(UserID,1,1)
) as X
)
FROM Demo1
後記
在寫本篇時,還發現了一個需要注意的問題,當利用VARCHAR字段做為分區依據時。
在查詢時需要在該字段使用 LIKE 而不是一般的Equal (=)做為查找。
如果採用一般的Equal(=)做為查找時,該執行計畫會顯示查找了所有分區內容
具體原因如果有朋友知道,還請協助解答。
以下是查找的比較圖

使用Equal(=)查找

使用LIKE查找
本次用來查詢表分區相關資訊的語法
SELECT t.name AS TableName, i.name AS IndexName, p.partition_number,
p.partition_id, i.data_space_id, f.function_id, f.type_desc,
r.boundary_id, r.value AS BoundaryValue,p.rows
FROM sys.tables AS t
JOIN sys.indexes AS i
ON t.object_id = i.object_id
JOIN sys.partitions AS p
ON i.object_id = p.object_id AND i.index_id = p.index_id
JOIN sys.partition_schemes AS s
ON i.data_space_id = s.data_space_id
JOIN sys.partition_functions AS f
ON s.function_id = f.function_id
LEFT JOIN sys.partition_range_values AS r
ON f.function_id = r.function_id and r.boundary_id = p.partition_number
WHERE t.name = '已分區表名稱' AND i.type <= 1
ORDER BY p.partition_number;
最後謝謝各位觀看囉!如果有問題歡迎在底下留言與我討論
[心得] SQL Server Partition(表分區) 資料分佈探討的更多相关文章
- sql server 更新表,每天的数据分固定批次设置批次号sql
按表中的字段 UpdateTime 按每天进行编号,每天的编号都从1开始编号,并附带表的主键 cid,把数据存入临时表中 WITH temp AS (SELECT cid,updatetime, RO ...
- 千万级SQL Server数据库表分区的实现
千万级SQL Server数据库表分区的实现 2010-09-10 13:37 佚名 数据库 字号:T | T 一般在千万级的数据压力下,分区是一种比较好的提升性能方法.本文将介绍SQL Server ...
- SQL Server 创建表分区
原文:SQL Server 创建表分区 先准备测试表 CREATE TABLE [dbo].[Employee] ( EmployeeNo ,) PRIMARY KEY, EmployeeName ) ...
- Sql server 系统表
sql server系统表详细说明 SQL Server 用户库中系统表说明 名称 说明 备注 syscolumns 每个表和视图中的每列在表中占一行,存储过程中的每个参数在表中也占一行. sys ...
- SQL Server系统表介绍与使用
关于SQL Server数据库的一切信息都保存在它的系统表格里.我怀疑你是否花过比较多的时间来检查系统表格,因为你总是忙于用户表格.但是,你可能需要偶尔做一点不同寻常的事,例如数据库所有的触发器.你可 ...
- sql server 关于表中只增标识问题 C# 实现自动化打开和关闭可执行文件(或 关闭停止与系统交互的可执行文件) ajaxfileupload插件上传图片功能,用MVC和aspx做后台各写了一个案例 将小写阿拉伯数字转换成大写的汉字, C# WinForm 中英文实现, 国际化实现的简单方法 ASP.NET Core 2 学习笔记(六)ASP.NET Core 2 学习笔记(三)
sql server 关于表中只增标识问题 由于我们系统时间用的过长,数据量大,设计是采用自增ID 我们插入数据的时候把ID也写进去,我们可以采用 关闭和开启自增标识 没有关闭的时候 ,提示一下错 ...
- Azure 意外重启, 丢失sql server master表和 filezilla
突然发现今晚网站打不开了,提示连不上数据库. ftp也连不上了. 远程连上Azure 发现机器意外重启, 丢失sql server master表和 filezilla 要重新安装. 又耗费我几个小时 ...
- SQL Server 系统表简介
SQL Server 系统表简介 系统目录是由描述SQL Server 系统的数据库.基表.视图和索引等对象的结构的系统表组成.SQL Server 经常访问系统目录,检索系统正常运行所需的必要信息. ...
- [SQL]SQL Server数据表的基础知识与增查删改
SQL Server数据表的基础知识与增查删改 由张晨辉(学生) 于19天 前发表 | 阅读94次 一.常用数据类型 .整型:bigint.int.smallint.tinyint .小数:decim ...
随机推荐
- Spring SpringMVC SpringBoot SpringCloud概念、关系及区别
一.正面解读: Spring主要是基于IOC反转Beans管理Bean类,主要依存于SSH框架(Struts+Spring+Hibernate)这个MVC框架,所以定位很明确,Struts主要负责表示 ...
- 《SpringMVC从入门到放肆》八、SpringMVC注解式开发(基本配置)
上一篇我们结束了配置式开发,配置式开发目前在企业中用的并不是很多,大部分企业都在使用注解式开发,所以今天我们就来学习注解式开发.所谓SpringMVC注解式开发是指,处理器是基于注解的类的开发方式.对 ...
- diy 滚动条 样式 ---- 核心代码
参考自 : https://blog.csdn.net/qq_38881495/article/details/83689721 .chapter_data position relative wid ...
- 树莓派3B+上运行.Net Core项目
最近买了个树莓派3B+,准备把自己写的一个.Net Core爬虫挂在上面跑 买之前没有想到树莓派因为是今年新出的,导致驱动以及系统啥的都不是很完善,导致走了很多弯路,早知道买树莓派3就不用那么多折腾了 ...
- emWin表盘界面设计,含uCOS-III和FreeRTOS两个版本
第4期:简易表盘界面设计 配套例子:V6-906_STemWin提高篇实验_简易表盘界面设计(uCOS-III)V6-907_STemWin提高篇实验_简易表盘界面设计(FreeRTOS) 例程下载地 ...
- [Swift]LeetCode701. 二叉搜索树中的插入操作 | Insert into a Binary Search Tree
Given the root node of a binary search tree (BST) and a value to be inserted into the tree, insert t ...
- [Swift]LeetCode964. 表示数字的最少运算符 | Least Operators to Express Number
Given a single positive integer x, we will write an expression of the form x (op1) x (op2) x (op3) x ...
- 主机名变成bogon?连不上mysql?你需要看下这篇文章
通过navicat for mysql操作部署在虚拟机centos里面的mysql数据库时候总是出现类似于下面的提示信息: Can't connct to MySQL server on '*.*.* ...
- Java连接数据库之MySQL
工具: eclipse MySQL Navicat for MySQL MySQL 连接驱动:mysql-connector-java-5.0.4-bin.jar SQL 代码 CREATE TABL ...
- 采坑:python base64
需求: 读取文本内容,对字符串进行base64加密 >>> str = 'aaaaaaaaaaaaaaaaaaa\nbbbbbbbbbbbbbbbbbbbbbbbbbbb\nccc ...