JDK1.8 ConcurrentHashMap源码阅读
1. 带着问题去阅读
为什么说ConcurrentHashMap是线程安全的?或者说 ConcurrentHashMap是如何防止并发的?
2. 字段和常量
首先,来看一下ConcurrentHashMap中的一些字段和常量,这些在接下来的操作中会用得到
2.1. 常量

从中,我们可以获得以下信息:
- 数组的默认容量是16,最大容量是1<<30
- 当添加元素的时候,将列表转成树的阈值是8。也就是说,相同位置上多个元素是以链表的形式存储的,而当链表的长度(元素的个数)超过8时,将其转为树
- 在对数组扩容的时候,当树中元素个数小于或等于6时,将树转成链表
2.2. 字段

从这些字段中,我们可以获得以下信息:
- 底层是一个数组,且数组的类型是Node,延迟初始化,更重要的是它被 volatile 修饰
- sizeCtl是用于数组初始化和扩容的,当它是负数的时候,表示数组正在进行初始化或扩容,-1表示正在初始化,同时应该注意到它也被 volatile 修饰
2.3. 内部类

对比1.7里面的HashMap不难发现:
- Node继承自Map.Entry
- 其 value 和 next 都用 volatile 修饰

可以看到,TreeNode继承自Node,主要用于树形结构中。也就是说,TreeNode表示树中的结点。
还有一个TreeBin也是继承自Node
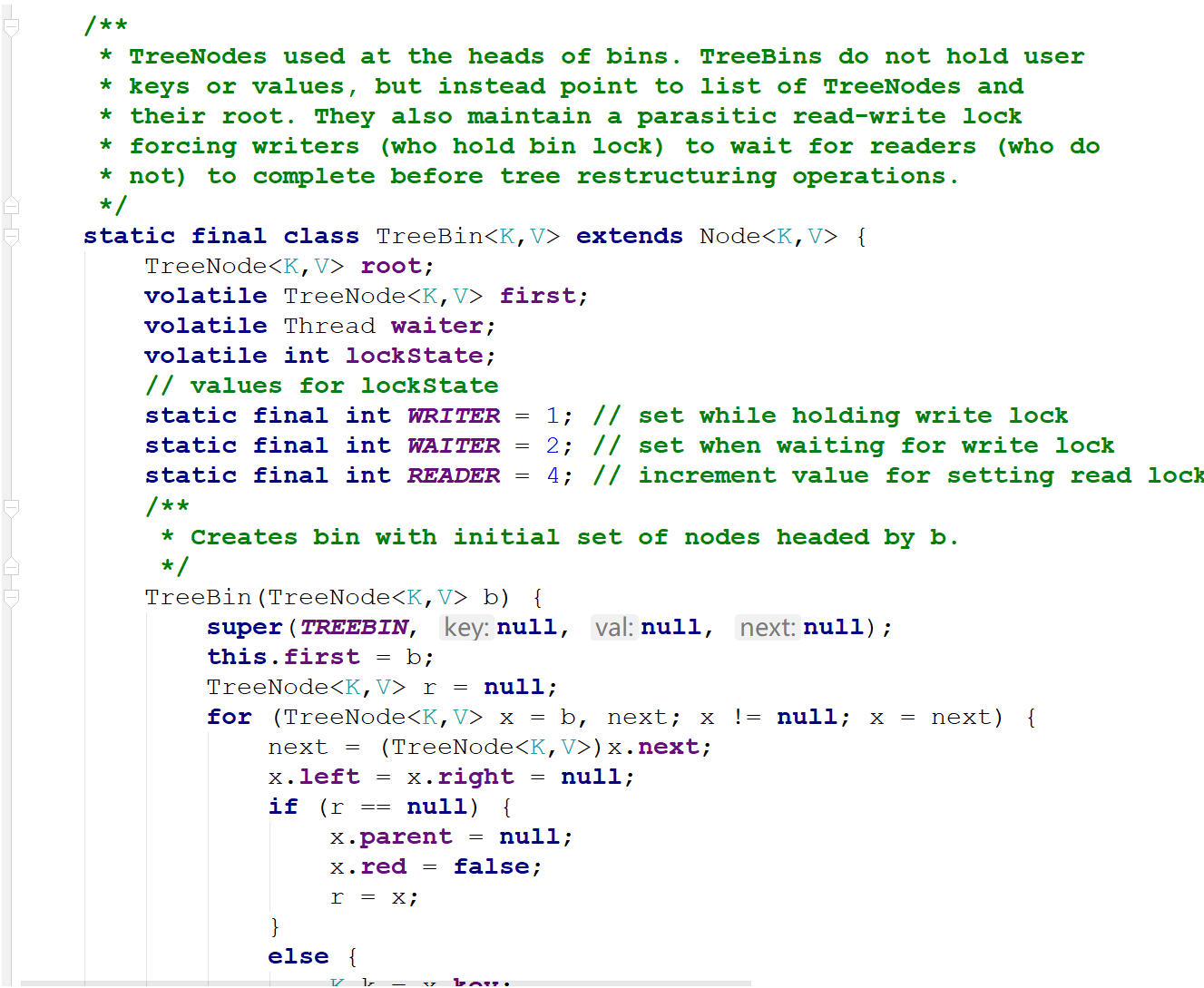
TreeBin表示整个树,TreeNode表示树中的结点
正常情况下,数组中某个位置的元素应该是Node,而Node是一个链表,它后面可能跟了多个Node。
但是,某个位置的节点个数超过阈值(默认8)时,将这个链表转成红黑树,那么此后数组中这个位置的元素就是TreeBin
也就是说,Node表示链表中的节点,TreeNode表示树中的节点,TreeBin表示树
3. 操作
3.1. put

这里,再多看一眼,刚才的putTreeVal()方法

总的来说,是先插入,后调整
大致流程是这样的:
- 如果数组为空,则先初始化数组
- 根据key计算哈希值,进而计算应该在数组的什么位置
- 取出该位置上的元素,如果为空,则直接构造一个Node,并将元素放置于此
- 如果该位置上的元素不为空,则进一步判断是链表还是树(PS:Node还是TreeBin)
- 如果是Node,则遍历链表,如果发现有key相同的元素,则用新值替换旧值,否则构造Node,并将其插入到链表尾部
- 如果是TreeBin,则遍历树,若发现相同key的节点,则用新值替换旧值,否则构造TreeNode,并将其插入到树中
- 插入完成以后,最后再看一下要不要转成树型结构
- 如果旧值不为空,则返回旧值
3.2. resize
在上一步的put操作中,如果数组正在扩容,则帮助扩容

下面看一下扩容

我以前在理解上一直有一个误区,以前我一直以为在数组相同位置上的元素的哈希值都相同,今天我恍然大悟,原来不是这样的,这些元素之所以会在同一个位置是因为通过key的哈希值再结合数组长度计算得出该元素应该在这个位置上,而不同的哈希值可能经过计算也在同一个位置,所以,相同位置的元素的hash值不一定相同,或者说,链表上的元素的hash并不一定都相同,只是恰巧它们在数组的位置相同而已。
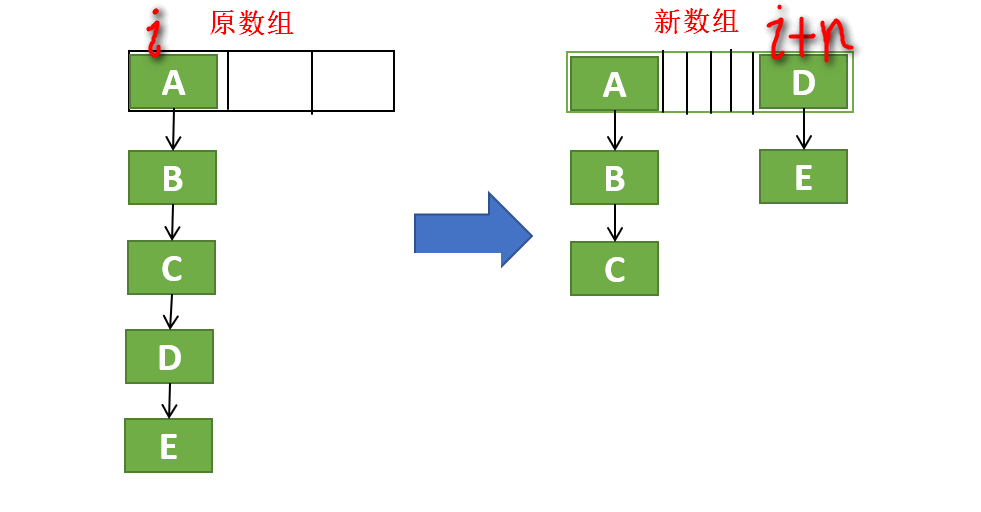
扩容是这样的:
- 新数组的长度是原来的2倍
- 根据不同位置的元素的结构有不同的方式
- 不管原来是链表结构还是树型结构,扩容以后都变成两部分,一部分是hash&n为0的,另一部分是hash&n不为0的,其中n为原数组的长度
- 对于那些hash&n==0的结点,它们在新数组中的位置保持不变,也就是说它们原先在旧数组中是什么位置,现在在新数组中还是什么位置
- 对于那些hash&n != 0的节点,它们在新数组中的位置相比于之前在旧数组中的位置是向后移动了n
- 每个位置在迁移的时候都加锁了
- 扩容后,原来在旧数组中在相同位置的结点在新数组中未必还在相同的位置
- 扩容后,链表没有倒置
- 由于迁移到新数组中时,会将原先一棵树分成两部分(跟链表一样),所以分出来的树中如果结点数小于或等于6,则转成链表
下面是一个示意图,不必拘泥细节,重在意思
3.3. get和remove
删除和获取相对比较简单,不再赘述
至此,可以回答开头我们提出的问题了
sychronized + volatile + CAS
插入、删除、扩容的时候都对数组中相应位置的元素加锁了,加锁用的是synchronized
table数组、Node中的val和next、以及一些控制字段都加了volatile
在更新一些关键变量的时候用到了sun.misc.Unsafe中的一些方法

JDK1.8 ConcurrentHashMap源码阅读的更多相关文章
- ConcurrentHashMap源码阅读
1. 前言 HashMap是非线程安全的,在多线程访问时没有同步机制,并发场景下put操作可能导致同一数组下的链表形成闭环,get时候出现死循环,导致CPU利用率接近100%. HashTable是线 ...
- JDK12 concurrenthashmap源码阅读
本文部分照片和代码分析来自文末参考资料 java8中的concurrenthashmap的方法逻辑和注解有些问题,建议看最新的JDK版本 建议阅读 concu ...
- JDK1.7 ConcurrentHashMap 源码浅析
概述 ConcurrentHashMap是HashMap的线程安全版本,使用了分段加锁的方案,在高并发时有比较好的性能. 本文分析JDK1.7中ConcurrentHashMap的实现. 正文 Con ...
- 【JDK1.8】JDK1.8集合源码阅读——总章
一.前言 今天开始阅读jdk1.8的集合部分,平时在写项目的时候,用到的最多的部分可能就是Java的集合框架,通过阅读集合框架源码,了解其内部的数据结构实现,能够深入理解各个集合的性能特性,并且能够帮 ...
- 【JDK1.8】JDK1.8集合源码阅读——HashMap
一.前言 笔者之前看过一篇关于jdk1.8的HashMap源码分析,作者对里面的解读很到位,将代码里关键的地方都说了一遍,值得推荐.笔者也会顺着他的顺序来阅读一遍,除了基础的方法外,添加了其他补充内容 ...
- 【JDK1.8】JDK1.8集合源码阅读——IdentityHashMap
一.前言 今天我们来看一下本次集合源码阅读里的最后一个Map--IdentityHashMap.这个Map之所以放在最后是因为它用到的情况最少,也相较于其他的map来说比较特殊.就笔者来说,到目前为止 ...
- 【JDK1.8】JDK1.8集合源码阅读——ArrayList
一.前言 在前面几篇,我们已经学习了常见了Map,下面开始阅读实现Collection接口的常见的实现类.在有了之前源码的铺垫之后,我们后面的阅读之路将会变得简单很多,因为很多Collection的结 ...
- 【JDK1.8】JDK1.8集合源码阅读——LinkedList
一.前言 这次我们来看一下常见的List中的第二个--LinkedList,在前面分析ArrayList的时候,我们提到,LinkedList是链表的结构,其实它跟我们在分析map的时候讲到的Link ...
- ConcurrentHashMap 源码阅读小结
前言 每一次总结都意味着重新开始,同时也是为了更好的开始.ConcurrentHashMap 一直是我心中的痛.虽然不敢说完全读懂了,但也看了几个重要的方法,有不少我觉得比较重要的知识点. 然后呢,放 ...
随机推荐
- SparkStreaming
Spark Streaming用于流式数据的处理.Spark Streaming支持的数据输入源很多,例如:Kafka.Flume.Twitter.ZeroMQ和简单的TCP套接字等等.数据输入后可以 ...
- adjustResize模式下ExpandaleListView中输入框焦点错乱及布局底部的导航栏被顶在键盘上方的处理
为了更好的用户体验,煎熬了许久,得到这么个解决方案.在此记录下来,以供后来者参考. 第一部分 清单文件中组件activity的android:windowSoftInputMode属性值的含义: [A ...
- Object冷知识
Object.create()方法创建一个新对象,使用现有的对象来提供新创建的对象的__proto__ 语法:Object.create(proto, [propertiesObject]) prop ...
- 英语词汇—V01
今日词汇 1, wash [wɒʃ] n. 洗涤:洗的衣服:化妆水:冲积物 vt. 洗涤:洗刷:冲走:拍打 vi. 洗澡:被冲蚀 2, dust [dʌst] n. 灰尘:尘埃:尘土 vt. 撒:拂去 ...
- VMware ESXi 6.5 安装
1.1下载esxi镜像 此处我使用的版本是:VMware-VMvisor-Installer-6.5.0-4564106.x86_64 1.2新建一个虚拟机,硬件兼容性处选择ESXI6.5 硬盘40g ...
- mvc 路由配置
1.URL模式 路由系统用一组路由来实现它的功能,这些路由共同组成了应用系统URL架构或方案,这种URL架构是应用程序能够识别并能对之做出响应的一组URL,当处理一个输入 请求时,路由系统的工作是将这 ...
- Autograd:自动微分
Autograd 1.深度学习的算法本质上是通过反向传播求导数,Pytorch的Autograd模块实现了此功能:在Tensor上的所有操作,Autograd都能为他们自动提供微分,避免手动计算导数的 ...
- SpringBoot报错:Table 'database_name.hibernate_sequence' doesn't exist
引起条件: SpringBoot+JPA插入包含自增字段的对象 @Id @GeneratedValue private Integer id; 解决方法: 给注解添加属性 @Id @Generated ...
- MORE XOR
MORE XOR #include<bits/stdc++.h> using namespace std; ; int a[maxn]; ][maxn]; int main() { ios ...
- 用Java写hello world
public class HelloWorld{ public static void main(String[] args){ System.out.println("hello worl ...