关于操作HDFS的一个问题
一、问题起源及详细异常
近日写程序定时任务调Hadoop MR程序,然后生成报表,发送邮件,当时起了两个任务A和B,调MR程序之前,会操作hdfs(读写都有),任务A每天一点跑,任务B每十分钟跑一次,B任务不会调用MR程序,纯粹采集数据。结果第一天就发现任务A没有发送邮件,于是乎查日志,异常信息如下
java.io.IOException: Failed on local exception: java.io.InterruptedIOException: Interrupted while waiting for IO on channel java.nio.channels.SocketChannel[connected local=/10.1.23.249:52305 remote=/10.1.23.249:9000]. 60000 millis timeout left.; Host Details : local host is: "hadoop-alone-test/10.1.23.249"; destination host is: "hadoop-alone-test":9000;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:776)
at org.apache.hadoop.ipc.Client.call(Client.java:1479)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy109.getListing(Unknown Source)
........
当时有点懵,不知道为什么出现这种IO被中断。于是乎,我在job控制台再调一下,并没有出现错误。本来想看看源码,但是领导安排了个比较紧急的任务。忙了几天,期间没有仔细去管,我只是注意了下每天的邮件,发现还是有的时候会成功的。忙完了任务,赶紧来排查,再看日志,发现报的错不止这一种,下面列出其他错误
java.io.IOException: Failed on local exception: java.io.IOException; Host Details : local host is: "hadoop-alone-test/10.1.23.249"; destination host is: "hadoop-alone-test":9000;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:776)
at org.apache.hadoop.ipc.Client.call(Client.java:1479)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy109.getFileInfo(Unknown Source)
...........
java.io.IOException: Filesystem closed
at org.apache.hadoop.hdfs.DFSClient.checkOpen(DFSClient.java:808)
at org.apache.hadoop.hdfs.DFSClient.listPaths(DFSClient.java:2083)
at org.apache.hadoop.hdfs.DistributedFileSystem$DirListingIterator.<init>(DistributedFileSystem.java:944)
at org.apache.hadoop.hdfs.DistributedFileSystem$DirListingIterator.<init>(DistributedFileSystem.java:927)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:872)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:868)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
................
java.io.IOException: The client is stopped
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1507)
at org.apache.hadoop.ipc.Client.call(Client.java:1451)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy109.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:771)
at sun.reflect.GeneratedMethodAccessor69.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
就是上述这四个错误,都是和io通信有关,然后都出现在操作Hadoop的FileSystem那段代码,且任务A和B都不等量的出现过,而且出现在凌晨一点,两个线程同时操作的时候,所以问题很明确,出在并发上面,联系到上面的FileSystem被关闭,我代码确实是调用了close方法
于是查看了一下源码,创建FileSystem的时候有如下代码
String disableCacheName = String.format("fs.%s.impl.disable.cache", scheme);
return conf.getBoolean(disableCacheName, false) ? createFileSystem(uri, conf) : CACHE.get(uri, conf);
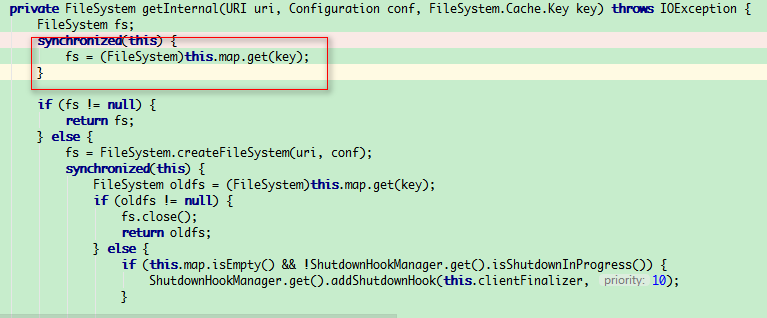
创建FileSystem的时候读取配置"fs.%s.impl.disable.cache",默认为false,所以第二次走了缓存, FileSystem的URI相同的话,一定只创建一个FileSystem
涉及到多线程访问,而线程B已经调用了filesystem.close()方法,这个时候线程A还在操作filesystem,所以报错上面种种异常
二、解决办法
1、代码同步(这里就不贴代码,用synchronized、lock这些都行)
2、禁用FileSystem缓存
代码里
Configuration conf = new Configuration();
conf.set("fs.hdfs.impl.disable.cache", "true");
core-site.xml文件里面配置(二者选其一)
<property>
<name>fs.hdfs.impl.disable.cache</name>
<value>true</value>
</property>
关于操作HDFS的一个问题的更多相关文章
- java操作hdfs实例
环境:window7+eclipse+vmware虚拟机+搭建好的hadoop环境(master.slave01.slave02) 内容:主要是在windows环境下,利用eclipse如何来操作hd ...
- Hadoop操作hdfs的命令【转载】
本文系转载,原文地址被黑了,故无法贴出原始链接. Hadoop操作HDFS命令如下所示: hadoop fs 查看Hadoop HDFS支持的所有命令 hadoop fs –ls 列出目录及文件信息 ...
- 使用javaAPI操作hdfs
欢迎到https://github.com/huabingood/everyDayLanguagePractise查看源码. 一.构建环境 在hadoop的安装包中的share目录中有hadoop所有 ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- 使用Eclipse来操作HDFS的文件
一.常用类 1.Configuration Hadoop配置文件的管理类,该类的对象封装了客户端或者服务器的配置(配置集群时,所有的xml文件根节点都是configuration) 创建一个Confi ...
- Hadoop Java API操作HDFS文件系统(Mac)
1.下载Hadoop的压缩包 tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 2.关联jar包 在 ...
- Hadoop基础-通过IO流操作HDFS
Hadoop基础-通过IO流操作HDFS 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.上传文件 /* @author :yinzhengjie Blog:http://www ...
- 使用Java Api 操作HDFS
如题 我就是一个标题党 就是使用JavaApi操作HDFS,使用的是MAVEN,操作的环境是Linux 首先要配置好Maven环境,我使用的是已经有的仓库,如果你下载的jar包 速度慢,可以改变Ma ...
- Java代码操作HDFS测试类
1.Java代码操作HDFS需要用到Jar包和Java类 Jar包: hadoop-common-2.6.0.jar和hadoop-hdfs-2.6.0.jar Java类: java.net.URL ...
随机推荐
- ABP之session
ABP提供了一个IAbpSession接口,可以在不使用ASPNET的session的情况下获取当前用户和租户.IAbpSession还被ABP中的其他结构(如设置和授权系统)完全集成和使用. 注入s ...
- 以API方式调用C# dll,使用OneNote2013 sp1实现OCR识别本地图片
http://www.cnblogs.com/Charltsing/p/OneNoteOCRAPI.html OneNote2013 OCR API调用使用说明2019.4.17 使用说明:1.安装干 ...
- mysql数据库连接语句一定要加传参的编码格式
jdbc:mysql://localhost:3306/pachong?useUnicode=true&characterEncoding=UTF-8 不然可能会出现从源代码传出的中文参数到m ...
- MySQL--7种join连接
一,定义: 1)LEFT JOIN / LEFT OUTER JOIN:左外连接 左向外连接的结果集包括:LEFT OUTER子句中指定的左表的所有行,而不仅仅是连接列所匹配的行.如果左表的某行在右表 ...
- python面试宝典2018最新版
需要的联系,QQ:1844912514
- Laravel数据库迁移
Laravel的数据迁移功能很好用,并且可以带来一系列好处.通过几条简单的 artisan 命令,就可以顺利上手,没有复杂的地方 注意:该系列命令对数据库非常危险,请准备一个单独的数据库作为配套练习, ...
- 论Scrapy中的数据持久化
引入 Scrapy的数据持久化,主要包括存储到数据库.文件以及内置数据存储. 那我们今天就来讲讲如何把Scrapy中的数据存储到数据库和文件当中. 终端指令存储 保证爬虫文件的parse方法中有可迭代 ...
- CENTOS手动安装修复python ,YUM
CENTOS手动安装修复YUM
CENTOS手动安装修复YUM 2019年3月8日 杨宇 Comments 0 Comment 目录 [hide] 一.问题场景 二.手动修复 2.1 下载 rpm 包 2.2 安装 rpm 包 ...
- fastclick原理剖析及其用法
移动端点击延迟事件 移动端浏览器在派发点击事件的时候,通常会出现300ms左右的延迟. 原因: 移动端的双击会缩放导致click判断延迟.这是为了检查用户是否在做双击.为了能够立即响应用户的点击事件, ...
- Node的安装和进程管理
安装nvm git clone https://github.com/creationix/nvm.git source nvm/nvm.sh 安装node nvm install 6.14.4(版本 ...