jieba库的使用与词频统计
1、词频统计
(1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本
挖掘的重要手段。它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其变化趋势。
(2)安装jieba库
安装说明
代码对 Python 2/3 均兼容
全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
通过 import jieba 来引用
示例、全自动安装
在命令行下输入指令:
pip install jieba
(2) 安装进程:

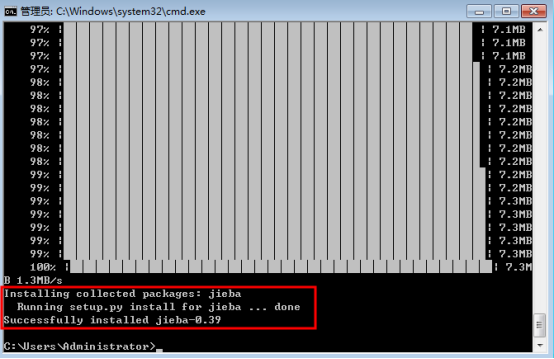
2、调用库函数
1、输入import jieba与使用其中函数
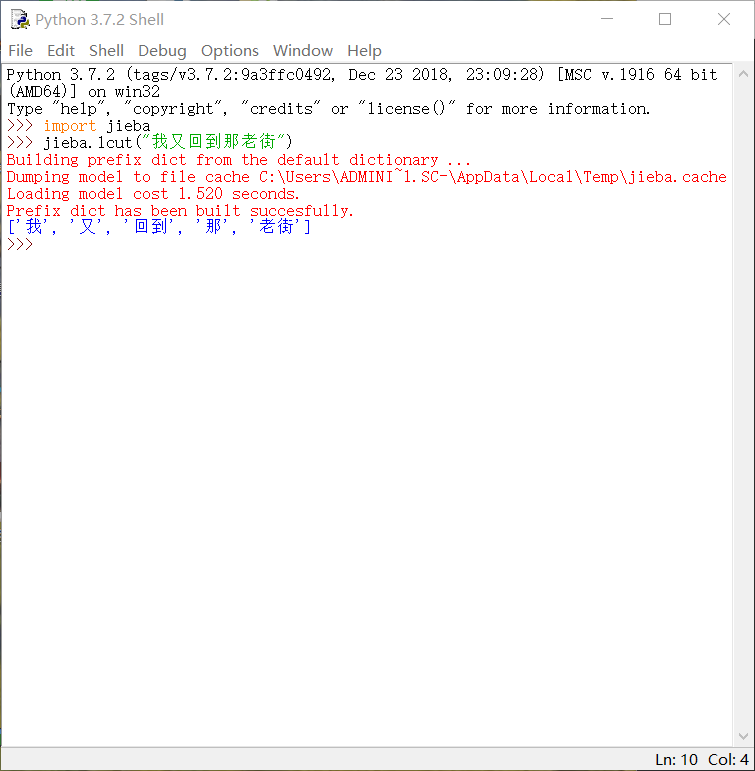
3、python代码
#! python3
# -*- coding: utf- -*-
import os, codecs
import jieba
from collections import Counter def get_words(txt):
seg_list = jieba.cut(txt) #对文本进行分词
c = Counter()
for x in seg_list: #进行词频统计
if len(x)> and x != '\r\n':
c[x] +=
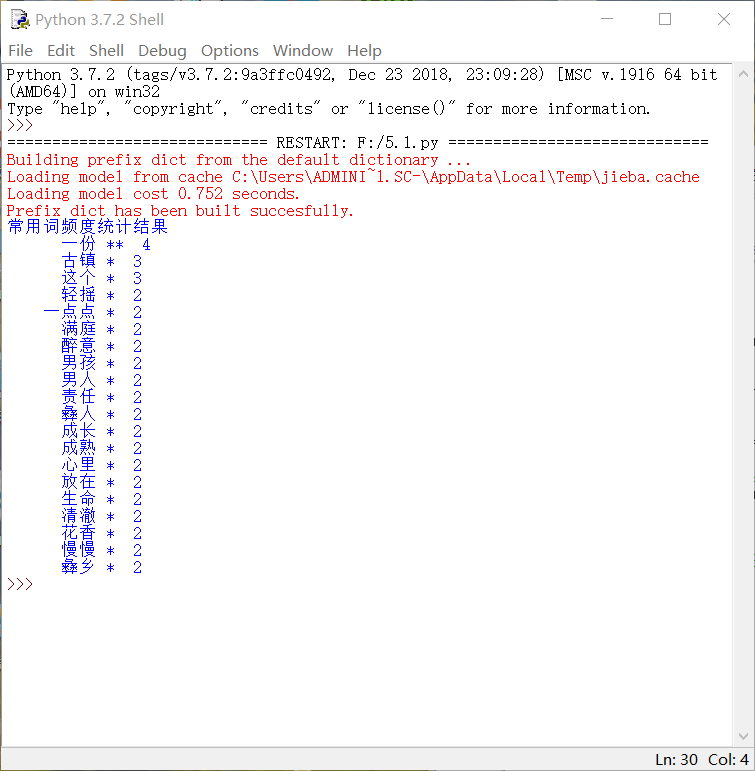
print('常用词频度统计结果')
for (k,v) in c.most_common(): #遍历输出高频词
print('%s%s %s %d' % (' '*(-len(k)), k, '*'*int(v/2), v)) if __name__ == '__main__':
with codecs.open('梦里花落知多少.txt', 'r', 'utf8') as f:
txt = f.read()
get_words(txt)
• •显示效果
4、词云
import jieba
import wordcloud
f = open("梦里花落知多少.txt","r",encoding = "utf-8") #打开文件
t = f.read() #读取文件,并存好
f.close()
ls = jieba.lcut(t) #对文本分词
txt = " ".join(ls) #对文本进行标点空格化
w = wordcloud.WordCloud(font_path = "msyh.ttc",width = ,height = ,background_color = "white") #设置词云背景,找到字体路径(否则会乱码)
w.generate(txt) #生成词云
w.to_file("govermentwordcloud.png") #保存词云图
• 词云显示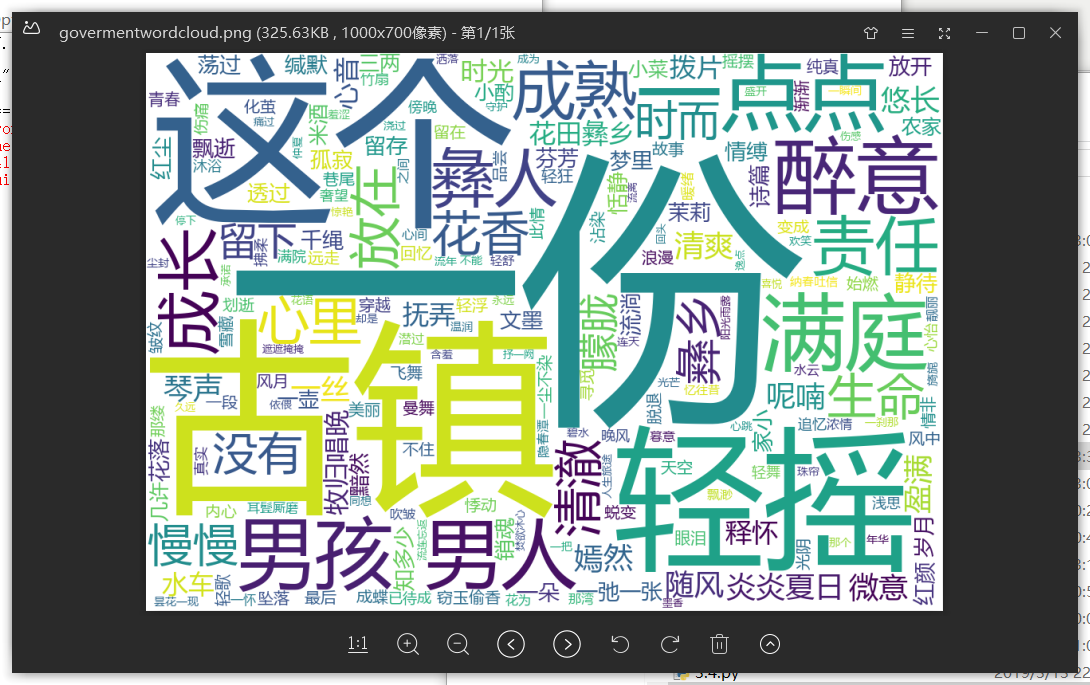
jieba库的使用与词频统计的更多相关文章
- jieba库及wordcloud库的使用
知识内容: 1.jieba库的使用 2.wordcloud库的使用 参考资料: https://github.com/fxsjy/jieba https://blog.csdn.net/fontthr ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jieba库词频统计
一.jieba 库简介 (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定义中文 ...
- py库: jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, 6, 1, 2, 1, 2, 1, 1] ls = ["呵呵", "呵呵&qu ...
- 利用python jieba库统计政府工作报告词频
1.安装jieba库 舍友帮装的,我也不会( ╯□╰ ) 2.上网寻找政府工作报告 3.参照课本三国演义词频统计代码编写 import jieba txt = open("D:\政府工作报告 ...
- Python之利用jieba库做词频统计且制作词云图
一.环境以及注意事项 1.windows10家庭版 python 3.7.1 2.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示 3.注意事项:由于wordclo ...
- jieba库词频统计练习
在sypder上运行jieba库的代码: import matplotlib.pyplot as pltfracs = [2,2,1,1,1]labels = 'houqin', 'jiemian', ...
- jieba库分词词频统计
代码已发至github上的python文件 词频统计结果如下(词频为1的词组数量已省略): {'是': 5, '风格': 4, '擅长': 4, '的': 4, '兴趣': 4, '宣言': 4, ' ...
- 使用jieba库与wordcloud库第三方库进行词频统计
一.jieba库与wordcloud库的使用 1.jieba库与wordcloud库的介绍 jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最 ...
随机推荐
- 从头开始学gradle【各系统安装gradle】
所有的环境都是基于jdk1.8 java -version windows安装 下载对应的gradle.zip安装包,解压到指定文件即可,然后配置相应的环境变量即可使用 linux/mac 安装 mk ...
- pyspider
Linux系统我使用CentOS.对于pycurl安装问题比较好解决,只需要先安装对应的开发包即可.执行如下命令: yum install python-devel curl-devel 分别安装py ...
- 8266编译错误 xtensa-lx106-elf/bin/ld: segmentled section `.text' will not fit in region `iram1_0_seg'
一种简单的解决办法 Okay, the solution was to copy the libgcc.a file from: esp-open-sdk/ESP8266_NONOS/lib/ to ...
- Arrays类的运用,二分法,数组的复制,命令行参数的运用,二维数组,Object,equals
/*Arrays jdk中为了便于开发,给开发者提供了Arrays类, 其中包含了很多数组的常用操作.例如快速输出.排序.查找等.*/ import java.util.Arrays; public ...
- 大前端服务器渲染 发布和部署 Vue + vue(SSR)
https://blog.csdn.net/sinat_15951543/article/details/80109521 就是到服务器dist 下面 npm run start & 然 ...
- Shell常用快捷键
编辑命令 ctr+u 删除光标到行首(unix-line-discard) ctrl+k 删除此处至末尾(kill-line) ctr+e 光标移到末尾(end) ctr+a 光标移到行首(ahead ...
- xr报表调整
xr报表调整,此乃为软件应用层调整,非后端数据库调整. 主单付款方式为AR支票300元 应收账务AR支票预付款 3000元录入调整 -300 AR支票付款录入收入 300 现金付款核销掉,报表现金多出 ...
- RabbitMQ通过Exchange.Direct、同一个队列绑定不同的routekey实现不同的消费
通过消费者去进行Exchange和Queue通过不同的RouteKey进行绑定 消费者1: static void Main(string[] args) { ConnectionFactory fa ...
- nand flash和nor flash的区别
NOR和NAND是现在市场上两种主要的非易失闪存技术. Intel于1988年首先开发出NOR flash技术,彻底改变了原先由EPROM和EEPROM一统天下的局面. 东芝于1989年开发出NAND ...
- Java1.0-1.12各个版本的新特性
JDK Version 1.0 1996-01-23 Oak(橡树) 初代版本,伟大的一个里程碑,但是是纯解释运行,使用外挂JIT,性能比较差,运行速度慢. JDK Version 1.1 1997- ...