linux服务器硬盘IO读写负载高来源定位 pt-ioprofile
|
1
2
3
4
5
|
top - 16:15:05 up 6 days, 6:25, 2 users, load average: 1.45, 1.77, 2.14
Tasks: 147 total, 1 running, 146 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.2% us, 0.2% sy, 0.0% ni, 86.9% id, 12.6% wa, 0.0% hi, 0.0% si
Mem: 4037872k total, 4003648k used, 34224k free, 5512k buffers
Swap: 7164948k total, 629192k used, 6535756k free, 3511184k cached
|
|
1
2
3
4
5
6
|
avg-cpu: %user %nice %sys %iowait %idle
0.00 0.00 0.25 33.46 66.29
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 1122 17.00 9.00 192.00 9216.00 96.00 4608.00 123.79 137.23 1033.43 13.17 100.10
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
|
|
1
|
vmstat 1
|
IO负载高的来源定位
前言:
在一般运维工作中经常会遇到这么一个场景,服务器的IO负载很高(iostat中的util),但是无法快速的定位到IO负载的来源进程和来源文件导致无法进行相应的策略来解决问题。
这个现象在MySQL上更为常见,在5.6(performance_schema提供io instrument)之前,我们通常只能猜到是MySQL导致的高IO,但是没法定位具体是哪个文件带来的负载。
例如是ibdata的刷写?还是冷门ibd的随机读取?
本文就将介绍一个比较简单的定位IO高负载的流程。
工具准备:
iotop: http://guichaz.free.fr/iotop/
pt-ioprofile:http://www.percona.com/downloads/percona-toolkit/2.2.1/
Step1 : iostat 查看IO情况
iostat -x 1 查看IO情况,从下图可以看到dfa这个磁盘的IO负载较高,接下来我们就来定位具体的负载来源
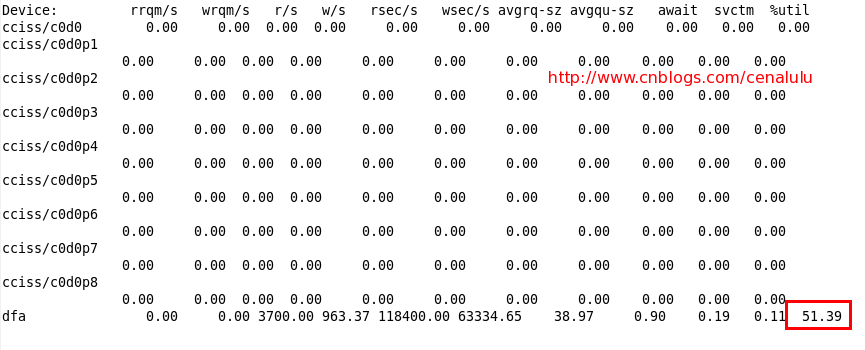
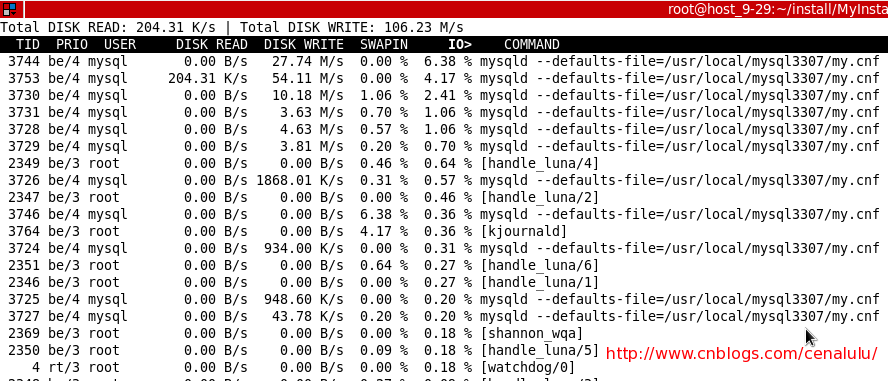
Step2: iotop定位负载来源进程
iotop的本质是一个python脚本,从proc中获取thread的IO信息,进行汇总。
从下图可以看出大部分的IO来源都来自于mysqld进程。因此可以确定dfa的负载来源是数据库
Step3 pt-ioprofile定位负载来源文件
pt-ioprofile的原理是对某个pid附加一个strace进程进行IO分析。
以下是摘自官网的一段警示:
However, it works by attaching strace to the process using ptrace(), which will make it run very slowly until strace detaches. In addition to freezing the server, there is also some risk of the process crashing or performing badly after strace detaches from it, or indeed of strace not detaching cleanly and leaving the process in a sleeping state. As a result, this should be considered an intrusive tool, and should not be used on production servers unless you are comfortable with that.
通过ps aux|grep mysqld 找到 mysqld进程对应的进程号,通过pt-ioprofile查看哪个文件的IO占用时间最多。
默认参数下该工具展示的是IO占用的时间。

对于定位问题更有用的是通过IO的吞吐量来进行定位。使用参数 --cell=sizes,该参数将结果已 B/s 的方式展示出来

从上图可以看出IO负载的主要来源是sbtest (sysbench的IO bound OLTP测试)。
并且压力主要集中在读取上。
linux服务器硬盘IO读写负载高来源定位 pt-ioprofile的更多相关文章
- [转]查看linux服务器硬盘IO读写负载
最近一台linux服务器出现异常,系统反映很慢,相应的应用程序也无法反映,而且还出现死机的情况,经过几天的观察了解,发现服务器压力很大,主要的压力来自硬盘的IO访问已经达到100% 为了方便各位和自己 ...
- 查看linux服务器硬盘IO读写负载
最近一台linux服务器出现异常,系统反映很慢,相应的应用程序也无法反映,而且还出现死机的情况,经过几天的观察了解,发现服务器压力很大,主要的压力来自硬盘的IO访问已经达到100% 为了方便各位和自己 ...
- IO负载高来源定位pt-ioprofile
1.使用top -d 1 查看%wa是否有等待IO完成的cpu时间,简单理解就是指cpu等待磁盘写入完成的时间:IO等待所占用的cpu时间的百分比,高过30%时IO压力高: 2.使用iostat -d ...
- Linux 查看磁盘IO并找出占用IO读写很高的进程
背景-线上告警 线上一台服务器告警,磁盘利用率 disk.util > 90,并持续告警. 登录该服务器后通过 iostat -x 1 10 查看了相关磁盘使用信息.相关截图如下: # 如果没有 ...
- linux磁盘IO读写性能优化
在LINUX系统中,如果有大量读请求,默认的请求队列或许应付不过来,我们可以 动态调整请求队列数来提高效率,默认的请求队列数存放在/sys/block/xvda/queue/nr_requests 文 ...
- IO负载高的来源定位
前言: 在一般运维工作中经常会遇到这么一个场景,服务器的IO负载很高(iostat中的util),但是无法快速的定位到IO负载的来源进程和来源文件导致无法进行相应的策略来解决问题. 这个现象在MySQ ...
- iotop,pt-ioprofile : mysql IO负载高的来源定位
http://www.cnblogs.com/cenalulu/archive/2013/04/12/3016714.html 前言: 在一般运维工作中经常会遇到这么一个场景,服务器的IO负载很高(i ...
- IO负载高的来源定位 IO系列
http://elf8848.iteye.com/category/281637 前言: 在一般运维工作中经常会遇到这么一个场景,服务器的IO负载很高(iostat中的util),但是无法快速的定位到 ...
- [Linux] - 服务器/VPS一键检测带宽、CPU、内存、负载、IO读写
一.SuperBench.sh VPS/服务器一键检测带宽.CPU.内存.负载.IO读写等的脚本: wget -qO- https://raw.githubusercontent.com/oooldk ...
随机推荐
- MongoDB exception:connection failed
根据http://www.runoob.com/mongodb/mongodb-window-install.html的教程配置了MongoDB,Mongod.exe配置为 --port 指令表明mo ...
- VS 2013 professional版在win10上安装出错的解决方法
VS 2013 professional版在win10上安装出错的解决方法 win10上安装完VS 2012 professional和VS 2017 professional后,由于项目的需要,要在 ...
- Android--操作图片Exif信息
前言 在Android系统中,图片文件在内存中以像素点的二维数组加载,存放像素信息,还会在开头加上一些额外的照片拍摄参数信息,这些信息就是Exif.Android2.0之后,媒体库加入了操作图片Exi ...
- RestTemplate的逆袭之路,从发送请求到负载均衡
上篇文章我们详细的介绍了RestTemplate发送请求的问题,熟悉Spring的小伙伴可能会发现:RestTemplate不就是Spring提供的一个发送请求的工具吗?它什么时候具有了实现客户端负载 ...
- EF架构~TransactionScope与SaveChanges的关系
回到目录 TransactionScope是.net环境下的事务,可以提升为分布式事务,这些知识早在很久前就已经说过了,今天不再说它,今天主要谈谈Savechanges()这个方法在Transacti ...
- Asp.Net Core 程序部署到Linux(centos)生产环境(一):普通部署
运行环境 照例,先亮底 centos:7.2 cpu:1核 2G内存 1M带宽 辅助工具:xshell xftp 搭建.net core运行环境 .net core 的运行环境我单独写了一篇,请看我的 ...
- 【Java基础】【08面向对象_继承&方法&final】
08.01_面向对象(代码块的概述和分类)(了解)(面试的时候会问,开发不用或者很少用) A:代码块概述 在Java中,使用{}括起来的代码被称为代码块. B:代码块分类 根据其位置和声明的不同,可以 ...
- springboot+mybatis+dubbo+aop日志第二篇
本篇主要介绍dubbo-demo-api接口层和dubbo-demo-service层,以及如何通过dubbo把服务发布出去,介绍代码前,咱们先来回顾一下整个demo工程的结构,如下图所示: 1.du ...
- 痞子衡嵌入式:通用NOR接口标准(CFI-JESD68)及SLC Parallel NOR简介
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是CFI标准及SLC Parallel NOR. NOR Flash是嵌入式世界里最常见的存储器,常常内嵌在微控制器里(Parallel型 ...
- markdown文本转换word,pdf
pandoc及下载和安装 pandoc是什么 pandoc是一个软件,是一个能把千奇百怪的文档格式互相转换的神器,是一把文档转换的瑞士军刀(swiss-army knife).不多说,放一张其官网(h ...