C# NetCore使用AngleSharp爬取周公解梦数据 起因和页面数据拆解
起因
最近突然心血来潮想做个小程序,学习一下小程序开发流程,然后新手就想做个查询的就可以了,少点交互能力,这种思来想去还是周公解梦比较靠谱,
网上一搜,还真有小程序源码,但是这里面似乎数据都是取第三方api的或者固定死的演示数据,或者残缺不全的数据,然后csdn上面居然还有积分下载周公
解梦数据的,评论都是说数据不全的,我这个脑子啊,这我就不愿意了,我要就要最全的,搞出来我也分享一下数据。。。。。。(其实是不是还是拖延症啊
不想学习小程序!!!)
然后网上搜了一下周公解梦,目前有一家数据是比较全的,而且页面结构是比较清晰的,可能是有程序员在维护。。。锁定数据源xzw。com 当然,如果
这种行为侵犯了xzw权益,请联系我删除。
言归正传
下面开始访问数据站,结构还是挺清晰的,梦的类别 梦的名称 里面的子项 及简介,我们大致可以设计一个表出来了

我们再点击进去看一下子项的内容,原来子项的内容都是依赖于外层的“孕妇”,这里我使用的是mysql数据库存储,
其实这种结构似乎更适合存储为nosql数据库,不纠结于这个,最多加个外键就OK。

可能初步的表是这样的
Dream表
| Id | 自增列 |
| Name | 梦的名字 例如 “孕妇” |
| Summary | 简介 这是搜索列表最外层的那个简介 |
| CateName | 分类名称 总分类可能就那固定的几个,我们这里只保存名称就好了 |
| CreateTime | 附属属性 |
| Url | 详细页面地址(这个是在下面会做说明) |
DreamInfo表
| Id | 自增列 |
| FkDreamId | Dream表主键 |
| DreamName | Dream表Name 例如 孕妇,为了不重复查询直接id和name都保存 |
| Name | 梦的详细名称,例如 未婚女人梦见孕妇 |
| Content | 梦的详细内容 |
| CreateTime | 附属属性,时间 |
分解页面结构
然后开始我们的页面分解之路,这个页面我们可以拿到 DreamName 还有Dream Summary 后面还要进入详情页绑定内容建立从属关系,
那么保存下这个详细页面的url,供我们第二次爬详细页面的时候使用,所以才会有上面dream表里的url字段,边发现边修改。
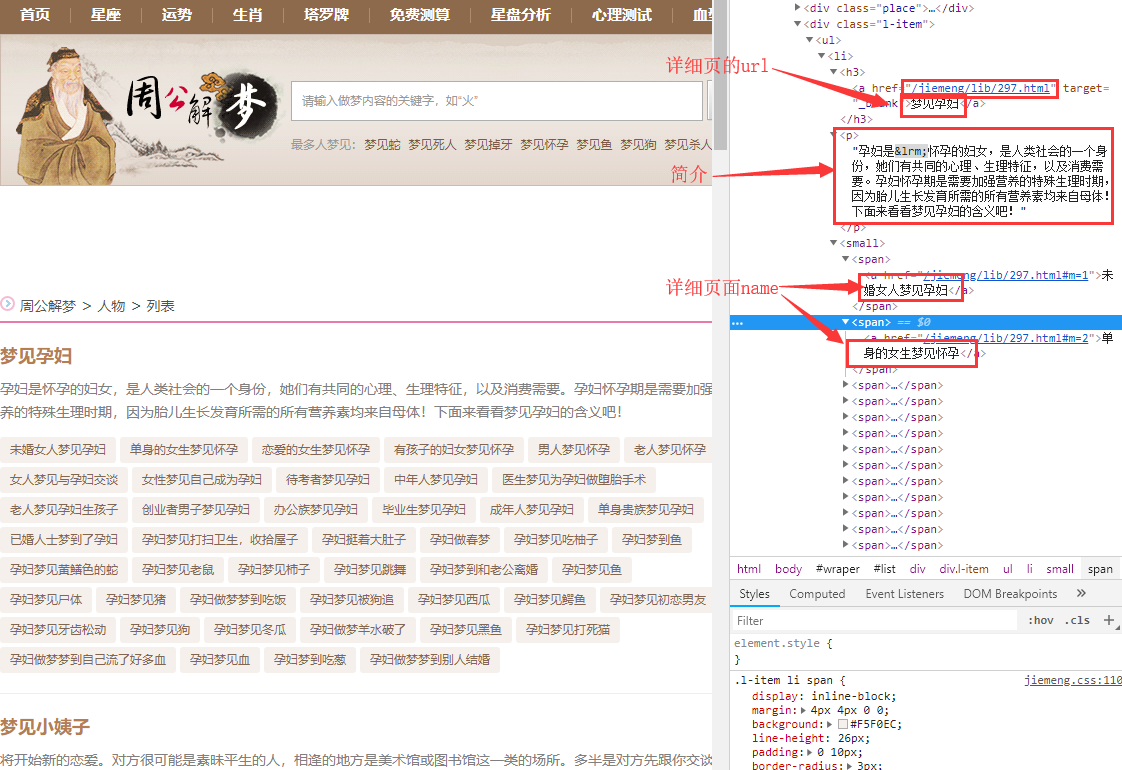
具体思路就有了,先获取分类下的名称信息、简介以及详情页url信息,下面有翻页,还是老规矩 递归翻页直到结束。
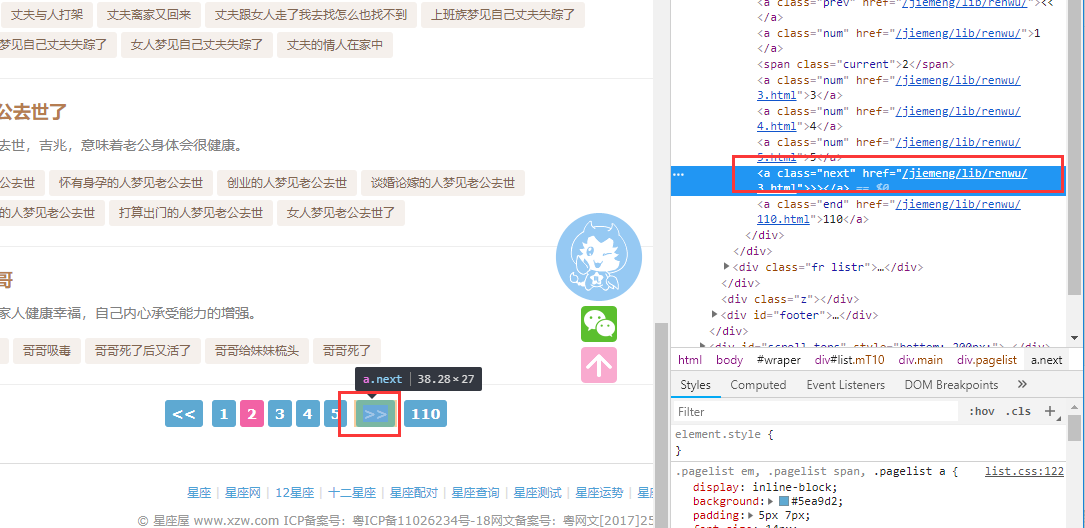
再来看看翻页,发现翻页这个地方,这里有个下一页的按钮,那么这个是不是就可以一直往下翻页了呢,我们就用它了。完美
总结
感觉自己脑袋乱糟糟的,没有固定的想法,可能一个想法牵扯出来多个想法,忘记自己第一个想法是什么了,感觉这种思维很可怕,咸鱼一般的感觉。
下一章开始详细编码。。。
C# NetCore使用AngleSharp爬取周公解梦数据 起因和页面数据拆解的更多相关文章
- C# NetCore使用AngleSharp爬取周公解梦数据
这一章详细讲解编码过程 那么接下来就是码代码了,GO 新建NetCore WebApi项目 空的就可以 NuGet安装 Install-Package AngleSharp 或者界面安装 using. ...
- Python爬取网上车市[http://www.cheshi.com/]的数据
#coding:utf8 #爬取网上车市[http://www.cheshi.com/]的数据 import requests, json, time, re, os, sys, time,urlli ...
- bert+seq2seq 周公解梦,看AI如何解析你的梦境?【转】
介绍 在参与的项目和产品中,涉及到模型和算法的需求,主要以自然语言处理(NLP)和知识图谱(KG)为主.NLP涉及面太广,而聚焦在具体场景下,想要生产落地的还需要花很多功夫. 作为NLP的主要方向,情 ...
- C#使用phantomjs,爬取AJAX加载完成之后的页面
1.开发思路:入参根据apiSetting配置文件,分配静态文件存储地址,可实现不同站点的静态页生成功能.静态页生成功能使用无头浏览器生成,生成之后的字符串进行正则替换为固定地址,实现本地正常访问. ...
- 几句简单的python代码完成周公解梦功能
<周公解梦>是靠人的梦来卜吉凶的一本于民间流传的解梦书籍,共有七类梦境的解述.这是非常传统的中国文化体系的一部分,但是如何用代码来获取并搜索周公解梦的数据呢?一般情况下,要通过爬虫获取数据 ...
- APISpace 周公解梦API接口 免费好用
<周公解梦>,是根据人的梦来卜吉凶的一本解梦书籍,它对人的七类梦境进行解述. 周公解梦API,周公解梦大全,周公解梦查询,免费周公解梦. APISpace 有很多免费通用的API接 ...
- 猫眼电影爬取(二):requests+beautifulsoup,并将数据存储到mysql数据库
上一篇通过requests+正则爬取了猫眼电影榜单,这次通过requests+beautifulsoup再爬取一次(其实这个网站更适合使用beautifulsoup库爬取) 1.先分析网页源码 可以看 ...
- python爬取返利网中值得买中的数据
先使用以前的方法将返利网的数据爬取下来,scrapy框架还不熟练,明日再战scrapy 查找目标数据使用的是beautifulsoup模块. 1.观察网页,寻找规律 打开值得买这块内容 1>分析 ...
- selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
简介 上一个博文已经讲述了如何使用selenium跳过webdriver检测并爬取天猫商品数据,所以在此不再详细讲,有需要思路的可以查看另外一篇博文. 源代码 # -*- coding: utf-8 ...
随机推荐
- libiconv库链接问题一则
https://blog.csdn.net/jeson2090/article/details/54632063 出现过glibc中的iconv_open返回EINVAL,原因猜测是有些字符集转换不支 ...
- 网站访问优化(二):开启apache服务器gzip压缩
昨天,把带宽从1M升级到2M,使用cdn版本的jquery之后,网站访问速度由平均5s(在禁止缓存的情况下,使用缓存大概在2.8s)下降到2.8s的样子. 今天,继续优化. 第1步: 把图片进行了 ...
- 批量杀死MySQL连接的几种方法
法一: 通过information_schema.processlist表中的连接信息生成需要处理掉的MySQL连接的语句临时文件,然后执行临时文件中生成的指令. mysql> select ...
- Nginx的一些介绍
Apacheserver:http://httpd.apache.org,世界上用的最多的server,开放源码.支持跨平台,可移植性,模块支持丰富,虽速度和性能及内存消耗不及其它轻量级Webserv ...
- CentOS7.1 KVM虚拟化之虚拟机快照(5)
这里用之前克隆的虚拟机vm1-clone进行快照操作 注: 1.快照实际上做的是虚拟机的XML配置文件,默认快照XML文件在/var/lib/libvirt/qemu/snapshot/虚拟机名/下 ...
- 微信开发学习日记(五):weiphp开源框架的bug,公众号权限编辑问题
最近在研究weiphp,总体感觉还行,bug据说还挺多. 这不,我就遇到一个比较严重影响使用的.感觉不太应该出现这么严重的bug啊. weiphp的微信公众号等级,权限增加和编辑bug,看不到权限列表 ...
- ssh登录很慢,登录上去后速度正常问题的解决方法
1. DNS反向解析的问题 OpenSSH在用户登录的时候会验证IP,它根据用户的IP使用反向DNS找到主机名,再使用DNS找到IP地址,最后匹配一下登录的IP是否合法.如果客户机的IP没有域名,或者 ...
- 基于 Android NDK 的学习之旅-----序言
前些日子做了个Android项目, 引擎层 用C的, 准备写这个系类的文章,借此跟朋友来分享下我NDK开放的经验以及自己知识的总结和备忘.希望能给需要这方面资料的朋友提供一定的帮助. 主要涉及到: ...
- 【u028】数列的整除性
Time Limit: 1 second Memory Limit: 128 MB [问题描述] 对于任意一个整数数列,我们可以在每两个整数中间任意放一个符号'+'或'-',这样就可以构成一个表达式, ...
- [React Router v4] Use the React Router v4 Link Component for Navigation Between Routes
If you’ve created several Routes within your application, you will also want to be able to navigate ...