C# NetCore使用AngleSharp爬取周公解梦数据 起因和页面数据拆解
起因
最近突然心血来潮想做个小程序,学习一下小程序开发流程,然后新手就想做个查询的就可以了,少点交互能力,这种思来想去还是周公解梦比较靠谱,
网上一搜,还真有小程序源码,但是这里面似乎数据都是取第三方api的或者固定死的演示数据,或者残缺不全的数据,然后csdn上面居然还有积分下载周公
解梦数据的,评论都是说数据不全的,我这个脑子啊,这我就不愿意了,我要就要最全的,搞出来我也分享一下数据。。。。。。(其实是不是还是拖延症啊
不想学习小程序!!!)
然后网上搜了一下周公解梦,目前有一家数据是比较全的,而且页面结构是比较清晰的,可能是有程序员在维护。。。锁定数据源xzw。com 当然,如果
这种行为侵犯了xzw权益,请联系我删除。
言归正传
下面开始访问数据站,结构还是挺清晰的,梦的类别 梦的名称 里面的子项 及简介,我们大致可以设计一个表出来了

我们再点击进去看一下子项的内容,原来子项的内容都是依赖于外层的“孕妇”,这里我使用的是mysql数据库存储,
其实这种结构似乎更适合存储为nosql数据库,不纠结于这个,最多加个外键就OK。

可能初步的表是这样的
Dream表
| Id | 自增列 |
| Name | 梦的名字 例如 “孕妇” |
| Summary | 简介 这是搜索列表最外层的那个简介 |
| CateName | 分类名称 总分类可能就那固定的几个,我们这里只保存名称就好了 |
| CreateTime | 附属属性 |
| Url | 详细页面地址(这个是在下面会做说明) |
DreamInfo表
| Id | 自增列 |
| FkDreamId | Dream表主键 |
| DreamName | Dream表Name 例如 孕妇,为了不重复查询直接id和name都保存 |
| Name | 梦的详细名称,例如 未婚女人梦见孕妇 |
| Content | 梦的详细内容 |
| CreateTime | 附属属性,时间 |
分解页面结构
然后开始我们的页面分解之路,这个页面我们可以拿到 DreamName 还有Dream Summary 后面还要进入详情页绑定内容建立从属关系,
那么保存下这个详细页面的url,供我们第二次爬详细页面的时候使用,所以才会有上面dream表里的url字段,边发现边修改。
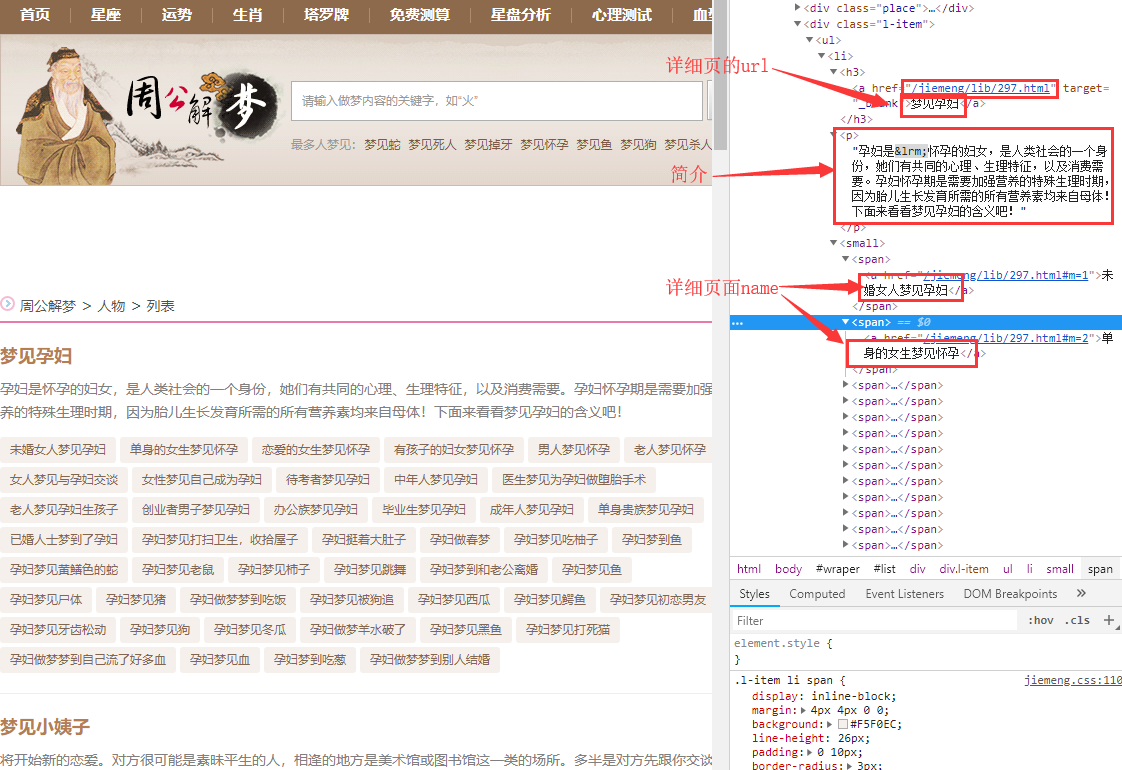
具体思路就有了,先获取分类下的名称信息、简介以及详情页url信息,下面有翻页,还是老规矩 递归翻页直到结束。
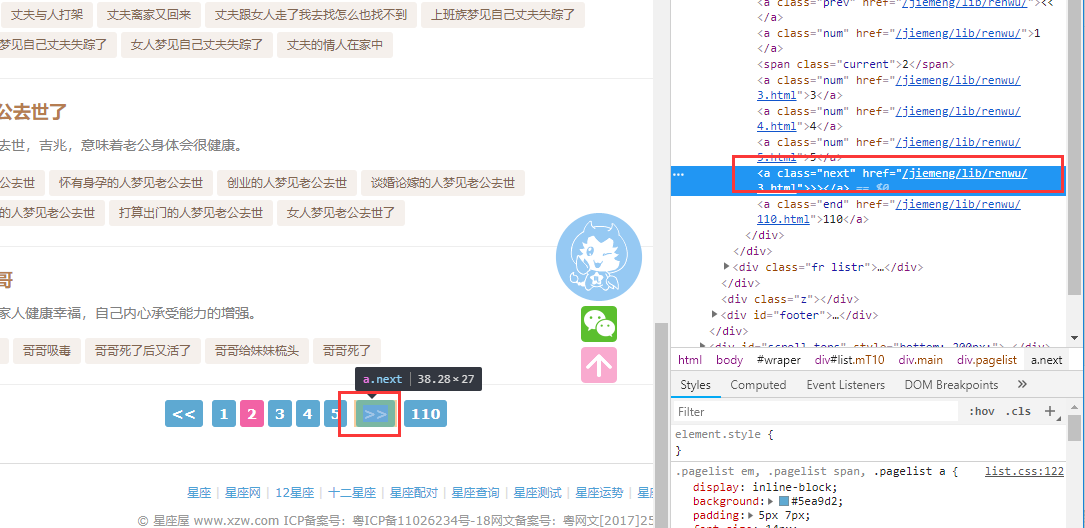
再来看看翻页,发现翻页这个地方,这里有个下一页的按钮,那么这个是不是就可以一直往下翻页了呢,我们就用它了。完美
总结
感觉自己脑袋乱糟糟的,没有固定的想法,可能一个想法牵扯出来多个想法,忘记自己第一个想法是什么了,感觉这种思维很可怕,咸鱼一般的感觉。
下一章开始详细编码。。。
C# NetCore使用AngleSharp爬取周公解梦数据 起因和页面数据拆解的更多相关文章
- C# NetCore使用AngleSharp爬取周公解梦数据
这一章详细讲解编码过程 那么接下来就是码代码了,GO 新建NetCore WebApi项目 空的就可以 NuGet安装 Install-Package AngleSharp 或者界面安装 using. ...
- Python爬取网上车市[http://www.cheshi.com/]的数据
#coding:utf8 #爬取网上车市[http://www.cheshi.com/]的数据 import requests, json, time, re, os, sys, time,urlli ...
- bert+seq2seq 周公解梦,看AI如何解析你的梦境?【转】
介绍 在参与的项目和产品中,涉及到模型和算法的需求,主要以自然语言处理(NLP)和知识图谱(KG)为主.NLP涉及面太广,而聚焦在具体场景下,想要生产落地的还需要花很多功夫. 作为NLP的主要方向,情 ...
- C#使用phantomjs,爬取AJAX加载完成之后的页面
1.开发思路:入参根据apiSetting配置文件,分配静态文件存储地址,可实现不同站点的静态页生成功能.静态页生成功能使用无头浏览器生成,生成之后的字符串进行正则替换为固定地址,实现本地正常访问. ...
- 几句简单的python代码完成周公解梦功能
<周公解梦>是靠人的梦来卜吉凶的一本于民间流传的解梦书籍,共有七类梦境的解述.这是非常传统的中国文化体系的一部分,但是如何用代码来获取并搜索周公解梦的数据呢?一般情况下,要通过爬虫获取数据 ...
- APISpace 周公解梦API接口 免费好用
<周公解梦>,是根据人的梦来卜吉凶的一本解梦书籍,它对人的七类梦境进行解述. 周公解梦API,周公解梦大全,周公解梦查询,免费周公解梦. APISpace 有很多免费通用的API接 ...
- 猫眼电影爬取(二):requests+beautifulsoup,并将数据存储到mysql数据库
上一篇通过requests+正则爬取了猫眼电影榜单,这次通过requests+beautifulsoup再爬取一次(其实这个网站更适合使用beautifulsoup库爬取) 1.先分析网页源码 可以看 ...
- python爬取返利网中值得买中的数据
先使用以前的方法将返利网的数据爬取下来,scrapy框架还不熟练,明日再战scrapy 查找目标数据使用的是beautifulsoup模块. 1.观察网页,寻找规律 打开值得买这块内容 1>分析 ...
- selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
简介 上一个博文已经讲述了如何使用selenium跳过webdriver检测并爬取天猫商品数据,所以在此不再详细讲,有需要思路的可以查看另外一篇博文. 源代码 # -*- coding: utf-8 ...
随机推荐
- [Recompose] Replace a Component with Non-Optimal States using Recompose
Learn how to use the ‘branch’ and ‘renderComponent’ higher-order components to show errors or messag ...
- 编译Android下可用的FFmpeg+x264
编译Android下可用的FFmpeg+x264 编译x264: 下载最新版的x264 ftp://ftp.videolan.org/pub/videolan/x264/snapshots/ 1.解压 ...
- java生成6位随机数
生成6位随机数(不会是5位或者7位,仅只有6位): System.out.println((int)((Math.random()*9+1)*100000)); 同理,生成5位随机数: System. ...
- 摘录-解压版mysql配置(版本5.7)
1.下载解压2.创建my.ini文件基础配置:(注意编码必须为ANSI)#代码开始[Client]# 设置mysql客户端默认字符集default-character-set=utf8[mysqld] ...
- [Angular] Subscribing to the valueChanges Observable
For example we have built a form: form = this.fb.group({ store: this.fb.group({ branch: '', code: '' ...
- SpringSecurity3.2.5自己定义角色及权限的教程
近期阴差阳错的搞上了SpringSecurity3.由于是自己做的小系统.中间遇到了非常多坑,基本每一个坑都踩过了,网上也查了不少资料,发现有不少错误的.更是让我绕了一圈又一圈,如今把一些主要的东西总 ...
- Bootstrap手机网站开发案例
Bootstrap手机网站开发案例 一.总结 一句话总结:Bootstrap手机网站开发注意事项(3点):a.引入viewpoint声明,b.通过屏幕宽动态控制元素显隐 c.图片添加自适应 1.Boo ...
- js中的style与jQuery中的css
使用jQuery选择器时,可以直接使用css函数(注意不能使用$("p")[1].css()) $("p").css("background-colo ...
- NOIP模拟 最佳序列 - 二分 + 单调队列
题意: 各一个n(\(\le 20000\))的序列,定义纯洁序列为长度len满足\(L \le len \le R\)的序列,纯洁值为某一纯洁序列的平局值,输出所有纯洁序列中最大平均值. 分析: 二 ...
- Erlang游戏开发-协议
Erlang游戏开发-协议 选择什么协议? 协议包含通讯协议和数据格式. 通讯协议 通讯协议目前常用的是:HTTP 和TCP .其有各自的特点根据游戏的特点而进行选择. HTTP HTTP比较成熟,使 ...