Spark Tachyon实战应用(配置启动环境、运行spark和运行mapreduce)
Tachyon实战应用
配置及启动环境
修改spark-env.sh
启动HDFS
启动Tachyon
Tachyon上运行Spark
添加core-site.xml
启动Spark集群
读取文件并保存
Tachyon运行MapReduce
修改core-site.xml
启动YARN
运行MapReduce例子
1 配置及启动环境
1.1.1 修改spark-env.sh
修改$SPARK_HOME/conf目录下spark-env.sh文件:
$cd /app/hadoop/spark-1.1./conf
$vi spark-env.sh
在该配置文件中添加如下内容:
export SPARK_CLASSPATH=/app/hadoop/tachyon-0.5./client/target/tachyon-client-0.5.-jar-with-dependencies.jar:$SPARK_CLASSPATH

1.1.2 启动HDFS
$cd /app/hadoop/hadoop-2.2./sbin
$./start-dfs.sh
1.1.3 启动Tachyon
在这里使用SudoMout参数,需要在启动过程中输入hadoop的密码,具体过程如下:
$cd /app/hadoop/tachyon-0.5./bin
$./tachyon-start.sh all SudoMount
1.2 Tachyon上运行Spark
1.2.1 添加core-site.xml
在Tachyon的官方文档说Hadoop1.X集群需要添加该配置文件(参见http://tachyon-project.org/documentation/Running-Spark-on-Tachyon.html),实际在Hadoop2.2.0集群测试的过程中发现也需要添加如下配置文件,否则无法识别以tachyon://开头的文件系统,具体操作是在$SPARK_HOME/conf目录下创建core-site.xml文件
$cd /app/hadoop/spark-1.1./conf
$touch core-site.xml
$vi core-site.xml
在该配置文件中添加如下内容:
<configuration>
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
</configuration>

1.2.2 启动Spark集群
$cd /app/hadoop/spark-1.1./sbin
$./start-all.sh
1.2.3 读取文件并保存
第一步 准备测试数据文件
使用Tachyon命令行准备测试数据文件
$cd /app/hadoop/tachyon-0.5./bin
$./tachyon tfs copyFromLocal ../conf/tachyon-env.sh /tachyon-env.sh
$./tachyon tfs ls /

第二步 启动Spark-Shell
$cd /app/hadoop/spark-1.1./bin
$./spark-shell
第三步 对测试数据文件进行计数并另存
对前面放入到Tachyon文件系统的文件进行计数
scala>val s = sc.textFile("tachyon://hadoop1:19998/tachyon-env.sh")
scala>s.count()


把前面的测试文件另存为tachyon-env-bak.sh文件
scala>s.saveAsTextFile("tachyon://hadoop1:19998/tachyon-env-bak.sh")

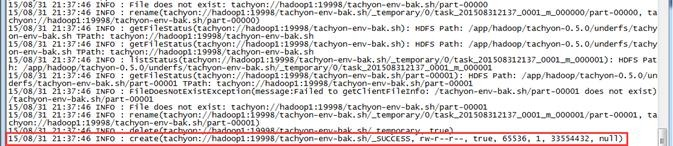
第四步 在Tachyon的UI界面查看
可以查看到该文件在Tachyon文件系统中保存成tahyon-env-bak.sh文件夹
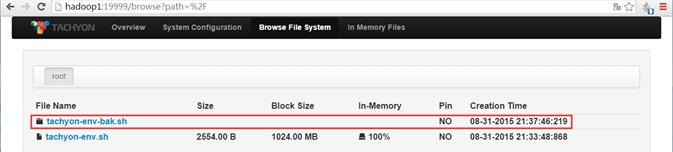
该文件夹中包含两个文件,分别为part-00000和part-00001:

其中tahyon-env-bak.sh/part-0001文件中内容如下:

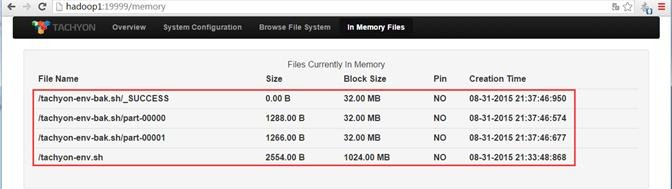
另外通过内存存在文件的监控页面可以观测到,这几个操作文件在内存中:
1.3 Tachyon运行MapReduce
1.3.1 修改core-site.xml
该配置文件为$Hadoop_HOME/conf目录下的core-site.xml文件
$cd /app/hadoop/hadoop-2.2./etc/hadoop
$vi core-site.xml
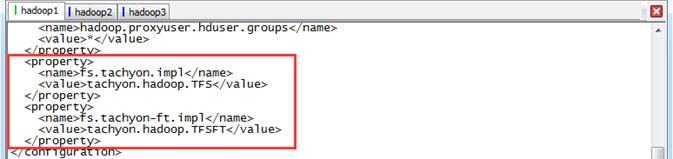
修改core-site.xml文件配置,添加如下配置项:
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
<property>
<name>fs.tachyon-ft.impl</name>
<value>tachyon.hadoop.TFSFT</value>
</property>
1.3.2 启动YARN
$cd /app/hadoop/hadoop-2.2./sbin
$./start-yarn.sh
1.3.3 运行MapReduce例子
第一步 创建结果保存目录
$cd /app/hadoop/hadoop-2.2./bin
$./hadoop fs -mkdir /class10
第二步 运行MapReduce例子
$cd /app/hadoop/hadoop-2.2./bin
$./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2..jar wordcount -libjars $TACHYON_HOME/client/target/tachyon-client-0.5.-jar-with-dependencies.jar tachyon://hadoop1:19998/tachyon-env.sh hdfs://hadoop1:9000/class10/output
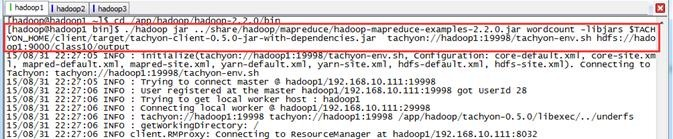

第三步 查看结果
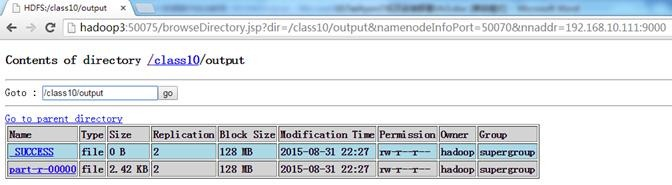
查看HDFS,可以看到在/class10中创建了output目录
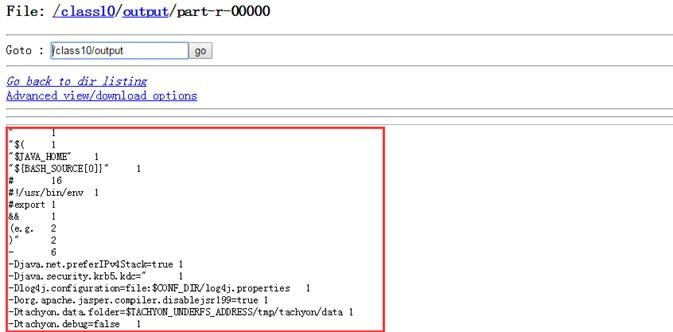
查看part-r-0000文件内容,为tachyon-env.sh单词计数
Spark Tachyon实战应用(配置启动环境、运行spark和运行mapreduce)的更多相关文章
- Spark Standalone Mode 多机启动 -- 分布式计算系统spark学习(二)(更新一键启动slavers)
捣鼓了一下,先来个手动挡吧.自动挡要设置ssh无密码登陆啥的,后面开搞. 一.手动多台机链接master 手动链接master其实上篇已经用过. 这里有两台机器: 10.60.215.41 启动mas ...
- Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder': —— windows 开发环境使用spark 无法访问hdfs 问题解决
## 错误: ## 解决方案: 下载 hadoop 的可执行tar包,解压放在windows 本地,并配置环境变量. 在 解压后的文件夹的bin目录下放入两个文件: winutils.exe, had ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
- Spark记录-spark-env.sh配置
环境变量 含义 SPARK_MASTER_IP master实例绑定的IP地址,例如,绑定到一个公网IP SPARK_MASTER_PORT mater实例绑定的端口(默认7077) SPARK_MA ...
- 在vscode成功配置Python环境
注意:如果您希望在Visual Studio Code中开始使用Python,请参阅教程.本文仅关注设置Python解释器/环境的各个方面. Python中的“环境”是Python程序运行的上下文.环 ...
- xampp本地服务器+HBuilder配置php环境
HBuilder配置PHP环境: 下载,运行HBuilder编辑器 打开右侧小窗口,点击设置图标—>设置web服务器—>外置web服务器 输入你想要浏 ...
- Spark master节点HA配置
Spark master节点HA配置 1.介绍 Spark HA配置需要借助于Zookeeper实现,因此需要先搭建ZooKeeper集群. 2.配置 2.1 修改所有节点的spark-evn.sh文 ...
随机推荐
- SVN在vs2013中使用
http://download.csdn.net/download/show_594/9112963 内包含VisualSVN 5.0.1的官方原版安装包及破解文件VisualSVN.Core.L.d ...
- python3.x学习笔记2(基础知识)
1.元组元组其实跟列表差不多,也是存一组数,只是它一旦创建,便不能在修改,所以又叫只读列表语法:names =('shgd','sjdh') 它只有两个方法,一个是count,一个是index 2.字 ...
- MVC5 + EF6 入门完整教程(转载)--01
MVC5 + EF6 入门完整教程 第0课 从0开始 ASP.NET MVC开发模式和传统的WebForm开发模式相比,增加了很多"约定". 直接讲这些 "约定&qu ...
- iOS——集成支付宝 系统繁忙,请稍后再试ALI10
问题描述:调用支付宝时,显示系统繁忙,请稍后再试(ALI10).代码没有报错,其他也是按照文档来的,为何老是提示显示系统繁忙? 解决方案:还需要在targets的中info里面,添加 url typ ...
- 使用 Beego 搭建 Restful API 项目
1 环境准备 首先你需要在你的环境安装以下软件: go:编程语言运行环境 git:版本控制工具 beego:go 语言流行的开发框架 bee:beego 配套的快速搭建工具 你喜欢的数据库:这里以 M ...
- java 自己定义异常,记录日志简单说明!留着以后真接复制
log4j 相关配制说明:http://blog.csdn.net/liangrui1988/article/details/17435139 自己定义异常 package org.rui.Excep ...
- linux系统 硬链接和软链接
背景: 当几个用户同在一个项目里工作时.经常须要共享文件. 假设一个共享文件同一时候出如今属于不同用户的不同文件夹下.工作起来就非常方便. 比如B和C文件夹下有一文件D是两者都能够訪问和改动的共享文件 ...
- vue20 父子组件数据交互
子组件使用父组件数据 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 如何更改jar包源码
首先将你要更改的源码文件在eclipse中编译成.class文件 再找到你需要更改的.jar包 在桌面右键新建个文件夹把你要改的.jar包ctrl+c和ctrl+v 准备好一个压缩工具(这里推荐234 ...
- 通过视频展示如何通过Samba配置PDC
通过视频展示如何通过Samba配置PDC(Linux企业应用案例精解补充视频内容) 本文通过视频,真实地再现了在Linux平台下如何通过配置smb.conf文件而实现Samba Server模拟win ...