记intel杯比赛中各种bug与debug【其五】:朴素贝叶斯分类器的实现和针对性的优化
咱这个项目最主要的就是这个了
贝叶斯分类器用于做可以统计概率的二元分类
典型的例子就是垃圾邮件过滤
理论基础
对于贝叶斯算法,这里附上两个链接,便于理解:
朴素贝叶斯分类器的应用-阮一峰的网络日志
基于朴素贝叶斯到中文垃圾邮件分类器
朴素贝叶斯分类器和一般的贝叶斯分类器有什么区别?-知乎
这里我们用朴素贝叶斯分类,假设所有特征都彼此独立,贝叶斯公式是这样
\]
现在我们收到一封邮件,假设T为此邮件为垃圾邮件,Wn为第N个词的存在
$ P(T|W_{n}) $的意思是在第n个词的存在下,这封邮件为垃圾邮件的概率
那么垃圾邮件和正常邮件的概率比就是这样的
\]
代码实现
class BeyasFilter:
# 0-ham 1-spam
def __init__(self):
self.count=[0, 0]
self.prior=1
self.freq={}
def train(self, words, label):
# label: 0-ham 1-spam
for word in words:
self.count[label]+=1
if word not in self.freq:
self.freq[word]=[0, 0]
self.freq[word][label]+=1
def isspam(self, content):
pred=self.prior
words=self.segment(content)
for word in words:
if self.freq.get(word) and self.freq[word][1]!=0 and self.freq[word][0]!=0:
pred*=(self.freq[word][1]*self.count[0])/(self.freq[word][0]*self.count[1])
return True if pred>1 else False
做一个小小的优化
在贝叶斯决策时,若发现某一个词汇并没有在训练字典中出现,我们使用拉普拉斯平滑(Laplace Smoothing)对其进行处理。
原理即是设定一个很小的值作为其后验概率。这样做保证在处理新词时,不会让后验概率乘零,也不会让后验概率乘壹而放过这个信息。及决策变为:
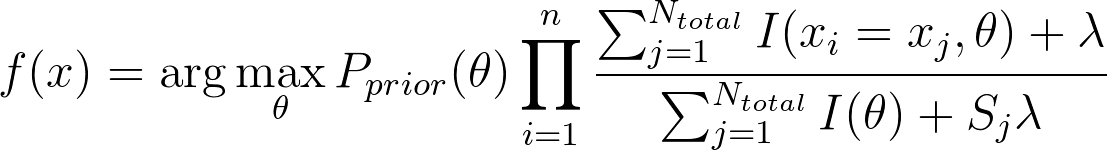
在处理较短的句子时,贝叶斯分类器很可能造成误判,比如消息“欢迎”。“欢迎”经常出现在重要消息中。但是这样一个短句独立的出现时,我们一般认为其是垃圾信息(因为不是重要信息)。通过贝叶斯决策理论发现我们难以处理这样的情况,所以我们对此作出优化。我们认为先验概率应包含句子长度的概率密度,最终优化效果令人满意。通过核概率密度估计,对句子长度做出统计,并在计算后验概率之后乘以这个调节函数,即可对短句作出优化。
具体的先验概率函数设计是这样的:
a. 首先对句子长度做出统计、平滑,得到下表。其中橙线为垃圾信息句子长度的概率密度,蓝线为重要信息句子长度的概率密度:
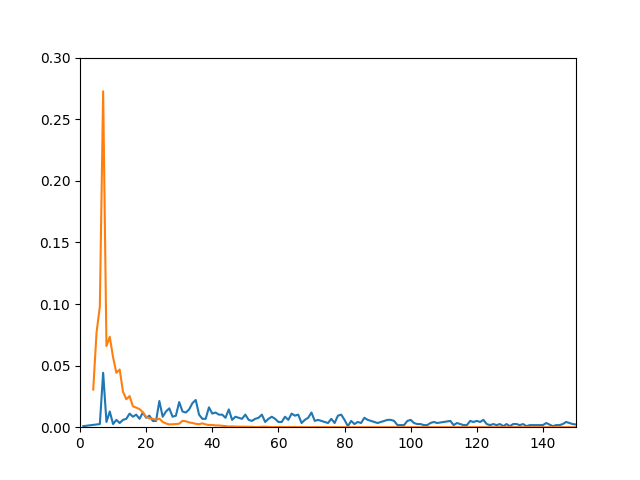
b. 结合图表,我们发现句子长度在垃圾信息和重要信息下的有较大分布差异
c. 设计一个函数,这个函数返回当前句子长度在垃圾信息和在重要信息中的概率比
d. 最终设计出函数:
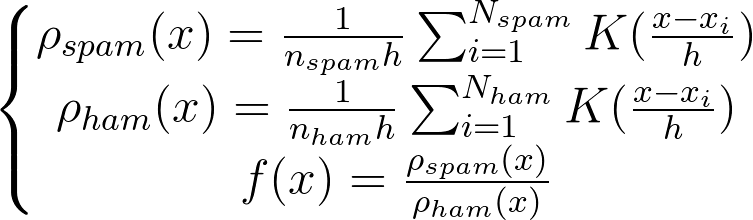
2018-02-28 Update: 修改一个关于先验概率的默认取值的错误
2018-08-02 Update: 写的什么垃圾,发现忘了更新这篇。优化部分用文档重写了
记intel杯比赛中各种bug与debug【其五】:朴素贝叶斯分类器的实现和针对性的优化的更多相关文章
- 记intel杯比赛中各种bug与debug【其一】:安装intel caffe
因为intel杯创新软件比赛过程中,并没有任何记录.现在用一点时间把全过程重演一次用作记录. 学习 pytorch 一段时间后,intel比赛突然不让用 pytoch 了,于是打算转战intel ca ...
- 记intel杯比赛中各种bug与debug【其二】:intel caffe的使用和大坑
放弃使用pytorch,学习caffe 本文仅记录个人观点,不免存在许多错误 Caffe 学习 caffe模型生成需要如下步骤 编写network.prototxt 编写solver.prototxt ...
- 记intel杯比赛中各种bug与debug【其四】:基于长短时记忆神经网络的中文分词的实现
(标题长一点就能让外行人感觉到高大上) 直接切入主题好了,这个比赛还必须一个神经网络才可以 所以我们结合主题,打算写一个神经网络的中文分词 这里主要写一下数据的收集和处理,网络的设计,代码的编写和模型 ...
- 记intel杯比赛中各种bug与debug【其三】:intel chainer的安装与使用
现在在训练模型,闲着来写一篇 顺着这篇文章,顺利安装上intel chainer 再次感谢 大黄老鼠 intel chainer 使用 头一次使用chainer,本以为又入了一个大坑,实际尝试感觉非常 ...
- SQL Server 字段类型 decimal(18,6)小数点前是几位?记一次数据库SP的BUG处理
原文:SQL Server 字段类型 decimal(18,6)小数点前是几位?记一次数据库SP的BUG处理 SQL Server 字段类型 decimal(18,6)小数点前是几位? 不可否认,这是 ...
- 那些盒模型在IE6中的BUG们,工程狮的你可曾遇到过?
HTML5学堂 那些盒模型在IE6中的BUG们,工程狮的你可曾遇到过? IE6已经渐渐的开始退出浏览器的历史舞台.虽然当年IE6作为微软的一款利器击败网景,但之后也因为版本的持续不更新而被火狐和谷歌三 ...
- 转:移动开发中一些bug及解决方案
网页开发要面对各种各样的浏览器,让人很头疼,而移动开发中,你不但要面对浏览器,还要面对各种版本的手机,iOS好一点,而安卓就五花八门了,你可能在开发中也被它们折磨过,或者正在被它们折磨,我在这里说几个 ...
- 写代码的心得,怎么减少编程中的 bug?
遭遇 bug 的时候,理性的程序员会说:这个 bug 能复现吗? 自负型:这不可能,在我这是好好的. 经验型:不应该,以前怎么没问题? 幻想型:可能是数据有问题. 无辜型:我好几个星期都没碰这块代码了 ...
- 新手数据比赛中数据处理方法小结(python)
第一次参加,天池大数据竞赛(血糖预测),初赛排名1%.因为自己对python不熟悉,所以记录一下在比赛中用到的一些python方法的使用(比较基础细节,大佬绕道): 1.数据初探 data.info( ...
随机推荐
- POJ 3368 线段树
思路: 先统计在第i个位置当前数字已经出现的次数. 维护两个数组,一个是当前位置的数字最后一次出现的位置,另一个是当前位置的数字第一次出现的位置 查找的时候分为两种情况: 没有和边界相交(意会意会)的 ...
- mysql导入数据,涉及到时间转换,乱码问题解决
表结构: drop table if exists `qi_an_log`;CREATE TABLE `qian_log` (`dt` LONG NOT NULL COMMENT '产生日期,格式yy ...
- Windows下安装和使用MongoDB
支持平台:从2.2版本开始,MongoDB不再支持Windows XP.要使用新版本的MongoDB,请用更新版本的Windows系统. 重要:如果你正在使用Windows Server 2008 R ...
- if switch
一.基本if结构: 1.语法:if (条件){ 代码块 } 2.执行顺序:先判断条件,条件成立则行{}内的代码,不成立则跳出if结构快既不执行{}内的代码. 3.什么情况下要用基本if选择结构:当需要 ...
- 头像文件上传 方法一:from表单 方法二:ajax
方法一:from表单 html 设置form表单,内包含头像预览div,内包含上传文件input 设置iframe用来调用函数传参路径 <!--表单提交成功后不跳转处理页面,而是将处理数据返回给 ...
- word-wrap与word-break的区别,以及无效情况
两种方法的区别说明: 1,word-break:break-all 例如div宽400px,它的内容就会到400px自动换行,如果该行末端有个英文单词很长(congratulation等),它会把单词 ...
- php创建图像具体步骤
php 的图像处理在验证码是最常见的,下面说下使用php创建图像的具体步骤. 简要说明:PHP 并不仅限于创建 HTML 输出, 它也可以创建和处理包括 GIF, PNG(推荐), JPEG, WBM ...
- c#获取DataTable某一列不重复的值,或者获取某一列的所有值
实现该功能是用了DataView的筛选功能,DataView表示用于排序.筛选.搜索.编辑和导航的 DataTable 的可绑定数据的自定义视图. 这里做了一个简单易懂的Demo来讲述该方法. 1.建 ...
- vue v-if的使用
代码部分 <el-row> <el-col :span="20"> <template v-for="(node,i) of hierarc ...
- redis 篇 - 键 and string
redis 进入控制台 redis-cil 需要输入密码的时候可以是用 -a redis-cil -a abcd1234 redis 数据类型 string hash list set zset( 有 ...