记intel杯比赛中各种bug与debug【其五】:朴素贝叶斯分类器的实现和针对性的优化
咱这个项目最主要的就是这个了
贝叶斯分类器用于做可以统计概率的二元分类
典型的例子就是垃圾邮件过滤
理论基础
对于贝叶斯算法,这里附上两个链接,便于理解:
朴素贝叶斯分类器的应用-阮一峰的网络日志
基于朴素贝叶斯到中文垃圾邮件分类器
朴素贝叶斯分类器和一般的贝叶斯分类器有什么区别?-知乎
这里我们用朴素贝叶斯分类,假设所有特征都彼此独立,贝叶斯公式是这样
\]
现在我们收到一封邮件,假设T为此邮件为垃圾邮件,Wn为第N个词的存在
$ P(T|W_{n}) $的意思是在第n个词的存在下,这封邮件为垃圾邮件的概率
那么垃圾邮件和正常邮件的概率比就是这样的
\]
代码实现
class BeyasFilter:
# 0-ham 1-spam
def __init__(self):
self.count=[0, 0]
self.prior=1
self.freq={}
def train(self, words, label):
# label: 0-ham 1-spam
for word in words:
self.count[label]+=1
if word not in self.freq:
self.freq[word]=[0, 0]
self.freq[word][label]+=1
def isspam(self, content):
pred=self.prior
words=self.segment(content)
for word in words:
if self.freq.get(word) and self.freq[word][1]!=0 and self.freq[word][0]!=0:
pred*=(self.freq[word][1]*self.count[0])/(self.freq[word][0]*self.count[1])
return True if pred>1 else False
做一个小小的优化
在贝叶斯决策时,若发现某一个词汇并没有在训练字典中出现,我们使用拉普拉斯平滑(Laplace Smoothing)对其进行处理。
原理即是设定一个很小的值作为其后验概率。这样做保证在处理新词时,不会让后验概率乘零,也不会让后验概率乘壹而放过这个信息。及决策变为:
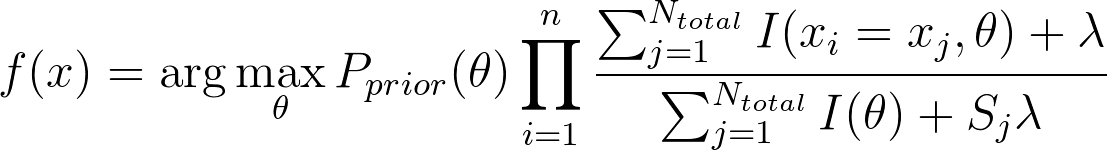
在处理较短的句子时,贝叶斯分类器很可能造成误判,比如消息“欢迎”。“欢迎”经常出现在重要消息中。但是这样一个短句独立的出现时,我们一般认为其是垃圾信息(因为不是重要信息)。通过贝叶斯决策理论发现我们难以处理这样的情况,所以我们对此作出优化。我们认为先验概率应包含句子长度的概率密度,最终优化效果令人满意。通过核概率密度估计,对句子长度做出统计,并在计算后验概率之后乘以这个调节函数,即可对短句作出优化。
具体的先验概率函数设计是这样的:
a. 首先对句子长度做出统计、平滑,得到下表。其中橙线为垃圾信息句子长度的概率密度,蓝线为重要信息句子长度的概率密度:
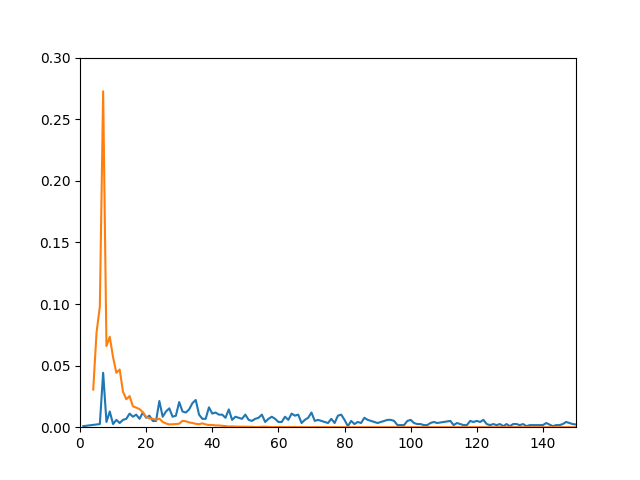
b. 结合图表,我们发现句子长度在垃圾信息和重要信息下的有较大分布差异
c. 设计一个函数,这个函数返回当前句子长度在垃圾信息和在重要信息中的概率比
d. 最终设计出函数:
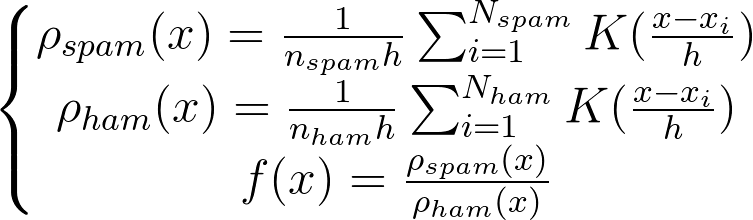
2018-02-28 Update: 修改一个关于先验概率的默认取值的错误
2018-08-02 Update: 写的什么垃圾,发现忘了更新这篇。优化部分用文档重写了
记intel杯比赛中各种bug与debug【其五】:朴素贝叶斯分类器的实现和针对性的优化的更多相关文章
- 记intel杯比赛中各种bug与debug【其一】:安装intel caffe
因为intel杯创新软件比赛过程中,并没有任何记录.现在用一点时间把全过程重演一次用作记录. 学习 pytorch 一段时间后,intel比赛突然不让用 pytoch 了,于是打算转战intel ca ...
- 记intel杯比赛中各种bug与debug【其二】:intel caffe的使用和大坑
放弃使用pytorch,学习caffe 本文仅记录个人观点,不免存在许多错误 Caffe 学习 caffe模型生成需要如下步骤 编写network.prototxt 编写solver.prototxt ...
- 记intel杯比赛中各种bug与debug【其四】:基于长短时记忆神经网络的中文分词的实现
(标题长一点就能让外行人感觉到高大上) 直接切入主题好了,这个比赛还必须一个神经网络才可以 所以我们结合主题,打算写一个神经网络的中文分词 这里主要写一下数据的收集和处理,网络的设计,代码的编写和模型 ...
- 记intel杯比赛中各种bug与debug【其三】:intel chainer的安装与使用
现在在训练模型,闲着来写一篇 顺着这篇文章,顺利安装上intel chainer 再次感谢 大黄老鼠 intel chainer 使用 头一次使用chainer,本以为又入了一个大坑,实际尝试感觉非常 ...
- SQL Server 字段类型 decimal(18,6)小数点前是几位?记一次数据库SP的BUG处理
原文:SQL Server 字段类型 decimal(18,6)小数点前是几位?记一次数据库SP的BUG处理 SQL Server 字段类型 decimal(18,6)小数点前是几位? 不可否认,这是 ...
- 那些盒模型在IE6中的BUG们,工程狮的你可曾遇到过?
HTML5学堂 那些盒模型在IE6中的BUG们,工程狮的你可曾遇到过? IE6已经渐渐的开始退出浏览器的历史舞台.虽然当年IE6作为微软的一款利器击败网景,但之后也因为版本的持续不更新而被火狐和谷歌三 ...
- 转:移动开发中一些bug及解决方案
网页开发要面对各种各样的浏览器,让人很头疼,而移动开发中,你不但要面对浏览器,还要面对各种版本的手机,iOS好一点,而安卓就五花八门了,你可能在开发中也被它们折磨过,或者正在被它们折磨,我在这里说几个 ...
- 写代码的心得,怎么减少编程中的 bug?
遭遇 bug 的时候,理性的程序员会说:这个 bug 能复现吗? 自负型:这不可能,在我这是好好的. 经验型:不应该,以前怎么没问题? 幻想型:可能是数据有问题. 无辜型:我好几个星期都没碰这块代码了 ...
- 新手数据比赛中数据处理方法小结(python)
第一次参加,天池大数据竞赛(血糖预测),初赛排名1%.因为自己对python不熟悉,所以记录一下在比赛中用到的一些python方法的使用(比较基础细节,大佬绕道): 1.数据初探 data.info( ...
随机推荐
- spring 发送邮件代码示例(带附件和不带附件的)
import javax.mail.MessagingException; import javax.mail.internet.MimeMessage; import org.springframe ...
- Sql Server 2012数据库的安装【自己一点一点敲的】
Sql Server 2012数据库的安装 1.到微软官网上下载 下载链接为:https://www.microsoft.com/zh-cn/download/details.aspx?id=2906 ...
- Vue.js Ajax动态参数与列表显示
一.动态参数显示 1.引入js <script type="text/javascript" src="/js/vue.min.js"></s ...
- 【原创】Google的文本内容对比代码
/* * Diff Match and Patch * * Copyright 2006 Google Inc. * http://code.google.com/p/google-diff-matc ...
- 小型ceph集群的搭建
了解ceph DFS(distributed file system)分布式存储系统,指文件系统管理的物理存储资源,不一定直接连接在本地节点上,而是通过计算机网络与节点相连,众多类别中,ceph是当下 ...
- 爬虫来啦!Day91
# 一.爬虫# 1.基本操作# 排名爬虫刷票# 抽屉网的所有发布新闻点赞# 自动化程序模拟用于的日常操作# 投票的机制是利用cookies,禁用cookies模式# 自定义的异步IO模块就是Socke ...
- vue 所有的路由跳转加一个统一参数
需求是什么 所有的路由跳转加一个统一的参数 实现方式 先深入理解一下router的全局前置守卫 router.beforeEach((to, from, next) => { const que ...
- VBA 中Dim含义
楼主是个初学者,在应用vba时遇到了dim方面的问题,查了很多资料后想把关于dim的这点儿知识简单整理出来 首先,从我遇到的问题作为切入点吧, (不得不承认我遇到的错误是很低级的) 具体的情境就不还原 ...
- Node_进阶_7
Node进阶第七天 一.复习 一.索引 数据库中,根据一个字段的值,来寻找一个文档,是很常见的操作.比如根据学号来找一个学生.这个学号是唯一的.只要有学号,就能唯一确认一个学生的文档.学号这个属性 ...
- [AH2017/HNOI2017]影魔(主席树+单调栈)
设\(l[i]\)为i左边第一个比i大的数的下标.\(r[i]\)为i右边第一个比i大的数的下标. 我们把\(p1,p2\)分开考虑. 当产生贡献为\(p1\)时\(i\)和\(j\)一定满足,分别为 ...