【scrapy实践】_爬取安居客_广州_新楼盘数据
需求:爬取【安居客—广州—新楼盘】的数据,具体到每个楼盘的详情页的若干字段。
难点:楼盘类型各式各样:住宅 别墅 商住 商铺 写字楼,不同楼盘字段的名称不一样。然后同一种类型,比如住宅,又分为不同的情况,比如分为期房在售,现房在售,待售,尾盘。其他类型也有类似情况。所以字段不能设置固定住。
解决方案:目前想到的解决方案,第一种:scrapy中items.py中不设置字段,spider中爬的时候自动识别字段(也就是有啥字段就保留下来),然后返回字典存起来。第二种,不同字段的网页分别写规则单独抓取。显然不可取。我采用的是第一种方案。还有其他方案的朋友们,欢迎交流哈。
目标网址为:http://gz.fang.anjuke.com/ 该网页下的楼盘数据

示例楼盘网址:http://gz.fang.anjuke.com/loupan/canshu-298205.html?from=loupan_tab
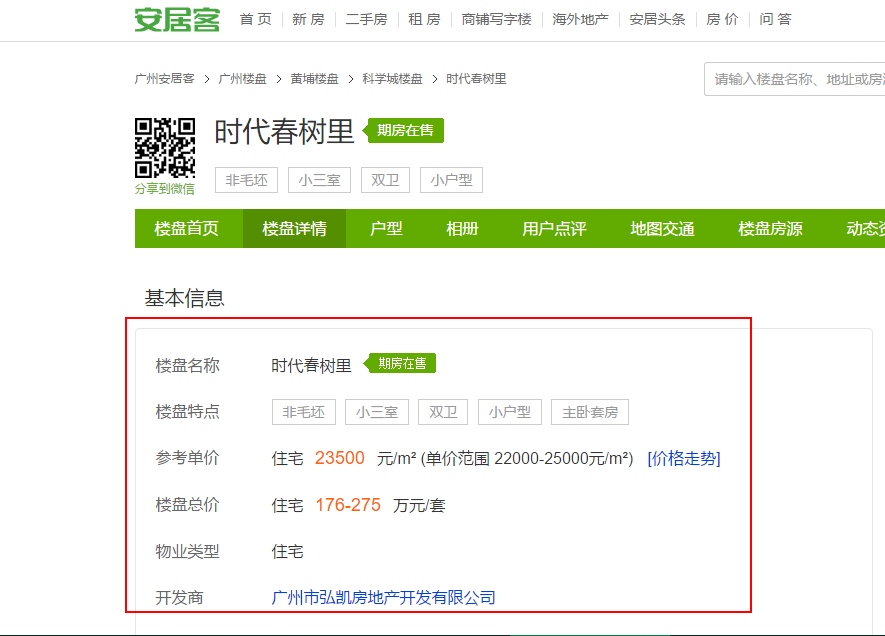
开始编写scrapy脚本。建立工程步骤略过。

1、count.py
__author__ = 'Oscar_Yang'
#-*- coding= utf-8 -*-
"""
查看mongodb存储状况的脚本count.py
"""
import time
import pymongo
client = pymongo.MongoClient("localhost", 27017)
db = client["SCRAPY_anjuke_gz"]
sheet = db["anjuke_doc1"] while True:
print(sheet.find().count())
print("____________________________________")
time.sleep(3)
"""
entrypoint.py
"""
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'anjuke_gz'])
# -*- coding: utf-8 -*-
"""
settings.py
""" # Scrapy settings for anjuke_gz project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'anjuke_gz' SPIDER_MODULES = ['anjuke_gz.spiders']
NEWSPIDER_MODULE = 'anjuke_gz.spiders'
MONGODB_HOST = "127.0.0.1"
MONGODB_PORT = 27017
MONGODB_DBNAME="SCRAPY_anjuke_gz"
MONGODB_DOCNAME="anjuke_doc1" # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'anjuke_gz (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'anjuke_gz.middlewares.AnjukeGzSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'anjuke_gz.middlewares.MyCustomDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'anjuke_gz.pipelines.AnjukeGzPipeline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
接下来,是items。因为没有设置字段,为默认的代码。
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class AnjukeGzItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
接下来,是piplines.py。在中设置了mongodb的配置。
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo
from scrapy.conf import settings class AnjukeGzPipeline(object):
def __init__(self):
host=settings["MONGODB_HOST"]
port=settings["MONGODB_PORT"]
dbname=settings["MONGODB_DBNAME"]
client=pymongo.MongoClient(port=port,host=host)
tdb = client[dbname]
self.post=tdb[settings["MONGODB_DOCNAME"]]
def process_item(self,item,spider):
info = dict(item)
self.post.insert(info)
return item
最后,是最主要的spider.py
from scrapy.http import Request
import scrapy
from bs4 import BeautifulSoup
import re
import requests
"""
spider脚本
"""
class Myspider(scrapy.Spider):
name = 'anjuke_gz'
allowed_domains = ['http://gz.fang.anjuke.com/loupan/']
start_urls = ["http://gz.fang.anjuke.com/loupan/all/p{}/".format(i) for i in range(39)] def parse(self, response):
soup = BeautifulSoup(response.text,"lxml")
content=soup.find_all(class_="items-name") #返回每个楼盘的对应数据
for item in content:
code=item["href"].split("/")[-1][:6]
real_href="http://gz.fang.anjuke.com/loupan/canshu-{}.html?from=loupan_tab".format(code) #拼凑出楼盘详情页的url
res=requests.get(real_href)
soup = BeautifulSoup(res.text,"lxml")
a = re.findall(r'<div class="name">(.*?)</div>', str(soup))
b = soup.find_all(class_="des")
data = {}
for (i, j) in zip(range(len(b)), a):
data[j] = b[i].text.strip().strip("\t")
data["url"] = real_href
yield data
下面是存入mongodb的情况。
因为针对不同的网页结构,爬取的规则是一个,所以爬取的时候就不能针对每个字段进行爬取,所以存到库里的数据如果要是分析的话还需要清洗。
在python中使用mongodb的查询语句,再配合使用pandas应该就很方便清洗了。

【scrapy实践】_爬取安居客_广州_新楼盘数据的更多相关文章
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- PyCharm+Scrapy爬取安居客楼盘信息
一.说明 1.1 开发环境说明 开发环境--PyCharm 爬虫框架--Scrapy 开发语言--Python 3.6 安装第三方库--Scrapy.pymysql.matplotlib 数据库--M ...
- python3 [爬虫实战] selenium 爬取安居客
我们爬取的网站:https://www.anjuke.com/sy-city.html 获取的内容:包括地区名,地区链接: 安居客详情 一开始直接用requests库进行网站的爬取,会访问不到数据的, ...
- python爬取安居客二手房网站数据(转)
之前没课的时候写过安居客的爬虫,但那也是小打小闹,那这次呢, 还是小打小闹 哈哈,现在开始正式进行爬虫书写 首先,需要分析一下要爬取的网站的结构: 作为一名河南的学生,那就看看郑州的二手房信息吧! 在 ...
- Python-新手爬取安居客新房房源
新手,整个程序还有很多瑕疵. 1.房源访问的网址为城市的拼音+后面统一的地址.需要用到xpinyin库 2.用了2种解析网页数据的库bs4和xpath(先学习的bs4,学了xpath后部分代码改成xp ...
- python爬虫爬取安居客并进行简单数据分析
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 爬取过程一.指定爬取数据二.设置请求头防止反爬三.分析页面并且与网页源码进行比对四.分析页面整理数据 ...
- python3 爬虫之爬取安居客二手房资讯(第一版)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author;Tsukasa import requests from bs4 import Beau ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
随机推荐
- GIS学习和开发的在线资源
1.OpenGIS Consortium标准,http://www.opengeospatial.org.著名的OGC标准是每个GIS开发者最后都不得不学习的,或深或浅. 2.SharpMap,Pro ...
- Python3 optparse模块
Python 有两个内建的模块用于处理命令行参数: 一个是 getopt,<Deep in python>一书中也有提到,只能简单处理 命令行参数: 另一个是 optparse,它功能强大 ...
- Swift 学习 用 swift 调用 oc
开发过程中 很可能 把swift不成熟的地方用成熟的oc 代码来弥补一下 , 下面简单来学习一下,我也是照着视频 学习的 卖弄谈不上 就是一次学习笔记, 具体问题还是具体分析吧. 需求 给展出出来的 ...
- Python学习进程(5)Python语法
本节介绍Python的基本语法格式:缩进.条件和循环. (1)缩进: Python最具特色的是用缩进来标明成块的代码. >>> temp=4;x=4; >> ...
- Java 集合系列13之 TreeMap详细介绍(源码解析)和使用示例
转载 http://www.cnblogs.com/skywang12345/p/3310928.html https://www.jianshu.com/p/454208905619
- JS 中 Date() 的其他操作集锦
好吧,这周完全是个业务型的程序猿了,明显地能感觉到洗头发时头皮都会有点疼,是秃顶的前兆. 算得上收获的就是有较多的接触到计算时间方面的事件...嗯,几个笔记分享一下 // 处理 /Date(" ...
- git 使用教程 --基础二
一:分支学习: branch称为分支,默认仅有一个名为master的分支.一般开发新功能流程为:开发新功能时会在分支dev上进行,开发完毕后再合并到master分支. 分支的作用: 创建分支:(创建分 ...
- 支持鼠标拖拽滑动的jQuery焦点图
在线演示 本地下载
- Eclipse与Tomcat的集成(无插件)
1.下载Eclipse(https://www.eclipse.org/downloads/)和Tomcat(http://tomcat.apache.org/),具体的安装略: 2.打开Eclips ...
- JMeter学习(十二)JMeter学习参数化User Defined Variables与User Parameters
相同点:二者都是进行参数化的. 一.User Defined Variables 1.添加方法:选择“线程组”,右键点击添加-Config Element-User Defined Variables ...